版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/jAVA_JLSONG/article/details/88034986
1. 机器学习的一些概念
有监督:给学习算法一个数据集。这个数据集由“正确答案”组成。监督 学习分为回归和分类。
无监督:给定一组数据,这组数据没有任何标签。我们的目标是发现数据中的特殊结构。
泛化能力:是指一个机器学习对于未见过的样本的识别能力。或者称为举一反三或者学以致用的能力。
过拟合:学习时选择的模型包含的参数过多,以致于出现这一模型对已知数据预测得很好,对未知数据预测得很差的现象。
解决办法:1)尽量减少特征的数量、(2)early stopping、(3)数据集扩增、(4)dropout、(5)正则化包括L1、L2、(6)清洗数据。
欠拟合:模型没有很好的捕捉到数据特征,不能够很好的拟合数据。
解决办法:(1)添加其他特征项,(2)添加多项式特征,(3)减少正则化参数
方差:反应的是每次输出结果与模型输出期望之间的误差,既模型的稳定性
形象化表示:
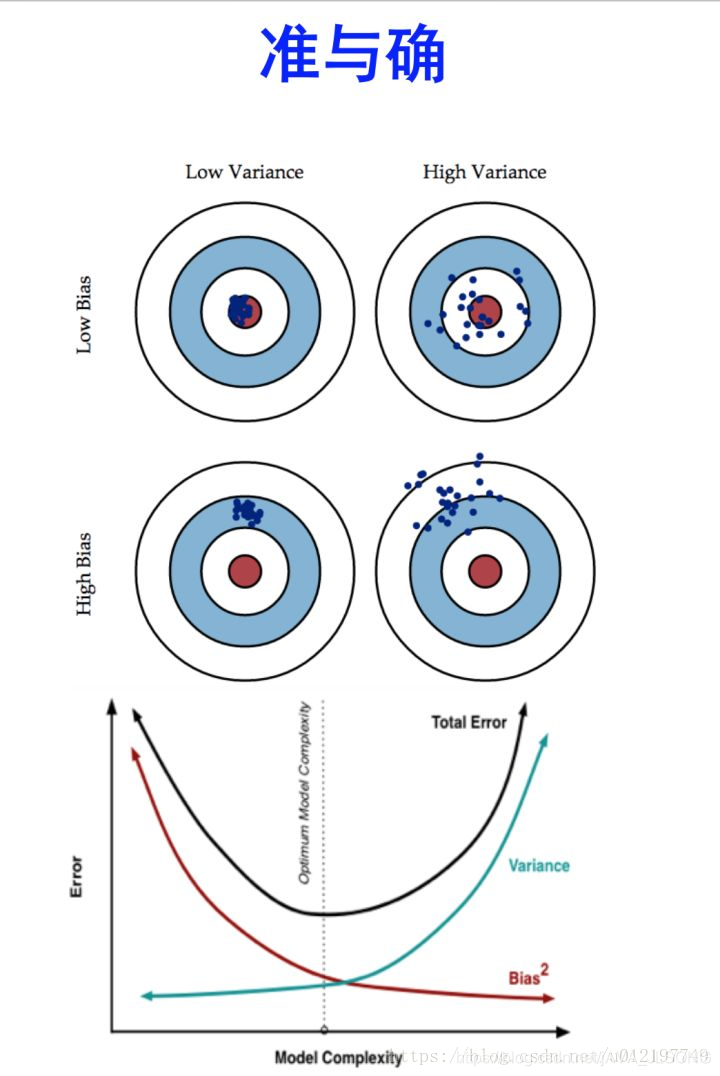
偏差:反映的是模型在样本上的输出与真实值之间的误差。即模型本身的精确度
交叉验证:就是重复的使用数据,把得到的样本数据进行切分,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏。在此基础上可以得到多组不同的训练集和测试集,某次训练集中的某样本在下次可能成为测试集中的样本,即所谓“交叉”。
2. 线性回归原理
创建模型:h(x)=w0+w1x
创建代价函数,目标是取代价函数最小值。问题可以转换为找到能使训练集中预测值和真实值的差的平方和的1/2m最小的w0和w1值。利用梯度下降算法或者正规方程来求解。
3.函数
损失函数:是用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。一般是针对单个样本
代价函数:任何能够衡量模型预测出来的值h(θ)与真实值y之间的差异的函数都可以叫做代价函数C(θ),如果有多个样本,则可以将所有代价函数的取值求均值,记做J(θ),一般是针对总体。
目标函数:代价函数+正则化项,使经验风险或者结构风险最小化
4.优化方法
梯度下降法:随机选择一个参数组合,计算代价函数,然后寻找下一个能让代价函数值下降最多的参数组合。持续这么做,直到找到一个局部最小值。有代数法和向量法两种表达方式
梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以也被称为是”最速下降法“。最速下降法越接近目标值,步长越小,前进越慢。
梯度下降法分为:
批量梯度下降---最小化所有训练样本的损失函数,使得最终求解的是全局的最优解,即求解的参数是使得风险函数最小,但是对于大规模样本问题效率低下。
随机梯度下降---最小化每条样本的损失函数,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近,适用于大规模训练样本情况。
牛顿法:关键问题是:切线是曲线的线性逼真。当无限放大切点的时候,切线在切点部分和曲线是吻合的。所以牛顿法就是一直迭代切线,直到找到方程的根。
牛顿法是一种在实数域和复数域上近似求解方程的方法。方法使用函数f (x)的泰勒级数的前面几项来寻找方程f (x) = 0的根。牛顿法最大的特点就在于它的收敛速度很快。
拟牛顿法:拟牛顿法是求解非线性优化问题最有效的方法之一。拟牛顿法的本质思想是改善牛顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使用正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度。拟牛顿法和最速下降法一样只要求每一步迭代时知道目标函数的梯度。通过测量梯度的变化,构造一个目标函数的模型使之足以产生超线性收敛性。这类方法大大优于最速下降法,尤其对于困难的问题。另外,因为拟牛顿法不需要二阶导数的信息,所以有时比牛顿法更为有效、
5.线性回归的评估指标
均方误差(MSE)
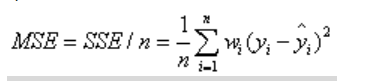
均方根误差(RMSE)
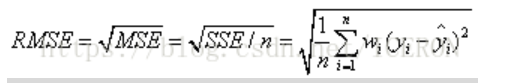
平方绝对误差(MAE)
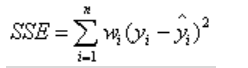
SSE越接近于0,说明模型选择和拟合更好,数据预测也越成功。
R Squared

其实“确定系数”是通过数据的变化来表征一个拟合的好坏。由上面的表达式可以知道“确定系数”的正常取值范围为[0 1],越接近1,表明方程的变量对y的解释能力越强,这个模型对数据拟合的也较好,R^2 越大,说明预测出来的数据可以通过模型的解释性就越强。
6.sklearn参数详解
n_neighbors:默认为5,就是k-NN的k的值,选取最近的k个点。
weights:默认是uniform,参数可以是uniform、distance,也可以是用户自己定义的函数。uniform是均等的权重,就说所有的邻近点的权重都是相等的。distance是不均等的权重,距离近的点比距离远的点的影响大。用户自定义的函数,接收距离的数组,返回一组维数相同的权重。
algorithm:快速k近邻搜索算法,默认参数为auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法ball_tree、kd_tree、brute方法进行搜索,brute是蛮力搜索,也就是线性扫描,当训练集很大时,计算非常耗时。kd_tree,构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。ball tree是为了克服kd树高纬失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。
leaf_size:默认是30,这个是构造的kd树和ball树的大小。这个值的设置会影响树构建的速度和搜索速度,同样也影响着存储树所需的内存大小。需要根据问题的性质选择最优的大小。
metric:用于距离度量,默认度量是minkowski,也就是p=2的欧氏距离(欧几里德度量)。p:距离度量公式。在上小结,我们使用欧氏距离公式进行距离度量。除此之外,还有其他的度量方法,例如曼哈顿距离。这个参数默认为2,也就是默认使用欧式距离公式进行距离度量。也可以设置为1,使用曼哈顿距离公式进行距离度量。
metric_params:距离公式的其他关键参数,这个可以不管,使用默认的None即可。
n_jobs:并行处理设置。默认为1,临近点搜索并行工作数。如果为-1,那么CPU的所有cores都用于并行工作。