我们平时经常会有一些搜集数据的需要,尤其是图片数据。如果一个一个从网上找再下载下来实在是太麻烦了,这么繁琐的工作不如交给脚本去做。于是我写了一个简单的PYTHON3爬取百度图片的爬虫,github: https://github.com/plutojia/crawler-for-baiduImage
我们先打开百度图片看看它到底是什么样子的:
在其中搜索“美女”:
我们在浏览这些图片时可以发现,当你下拉滚动条时,又会有新的图片出现,而这些新的图片并不是一开始就加载好的,而是随着你的向下浏览不断请求刷新的,这就说明百度图片这种瀑布流式加载使用了Ajax技术,那么我们看看它的Ajax请求到底是什么样的。
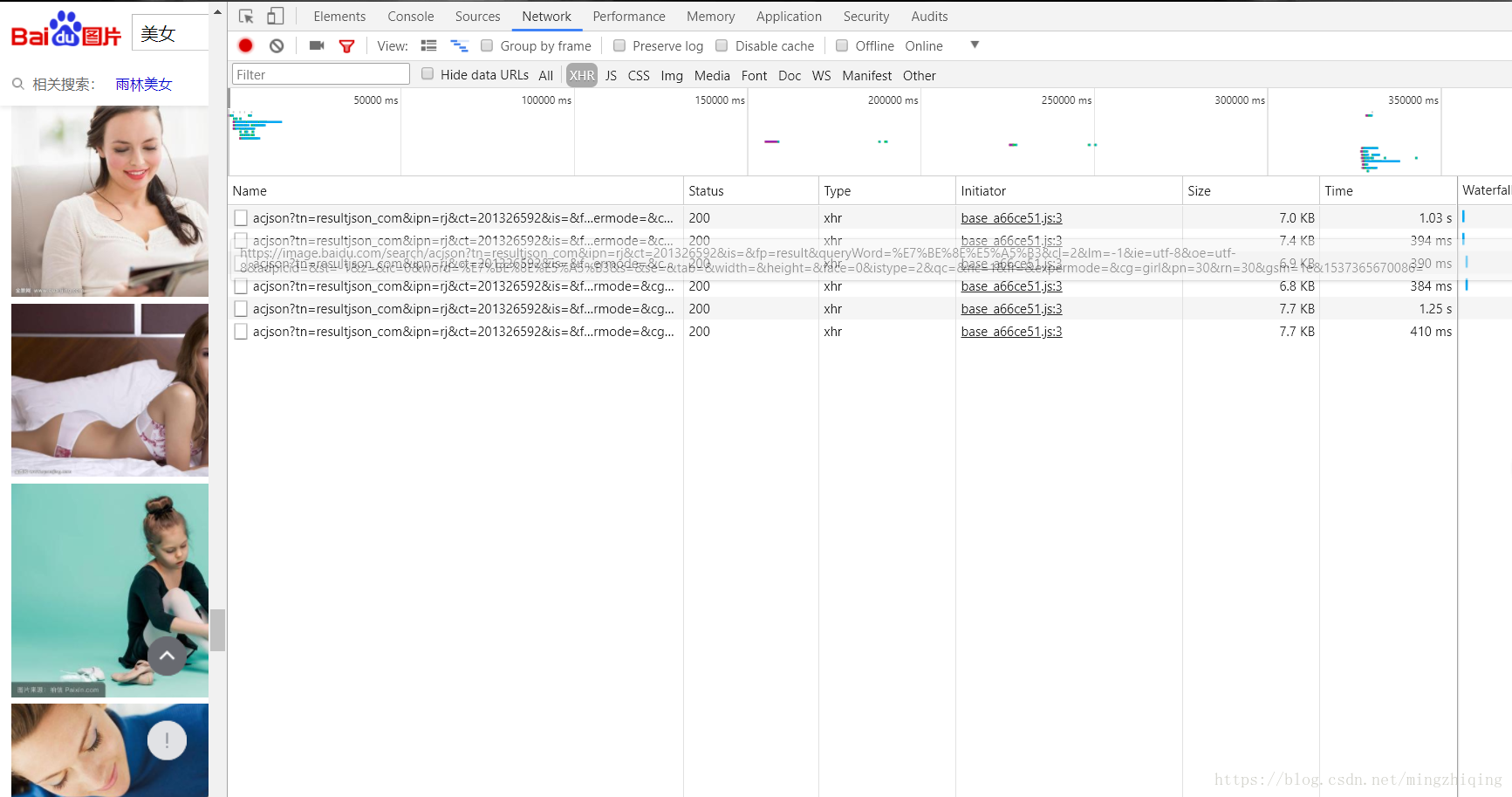
在搜索美女的页面下,打开chrome浏览器的开发者工具,选择Network选项卡,再选择Network选项卡里的XHR选项卡,然后把网页向下翻,多翻几页,应该会看到请求出现,如图所示:
双击点开其中的任意请求看看:
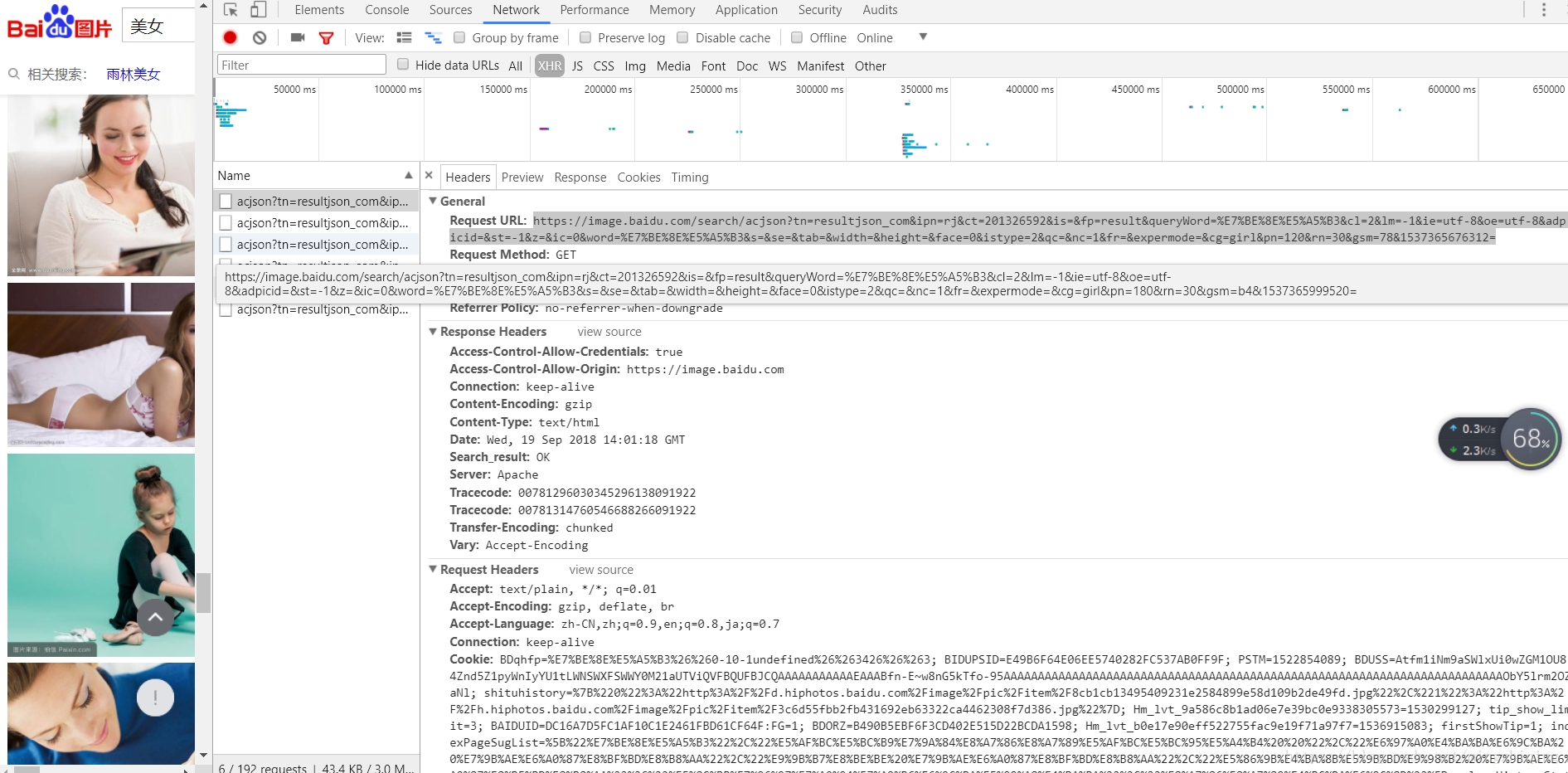
发现请求url是https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E7%BE%8E%E5%A5%B3&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=%E7%BE%8E%E5%A5%B3&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&cg=girl&pn=120&rn=30&gsm=78&1537365676312=
前面的https://image.baidu.com/search/acjson?还挺清楚,后面的一长串是什么玩意啊?别急,继续往下看。在开发者工具中继续往下查看,可以看到有这么一段:
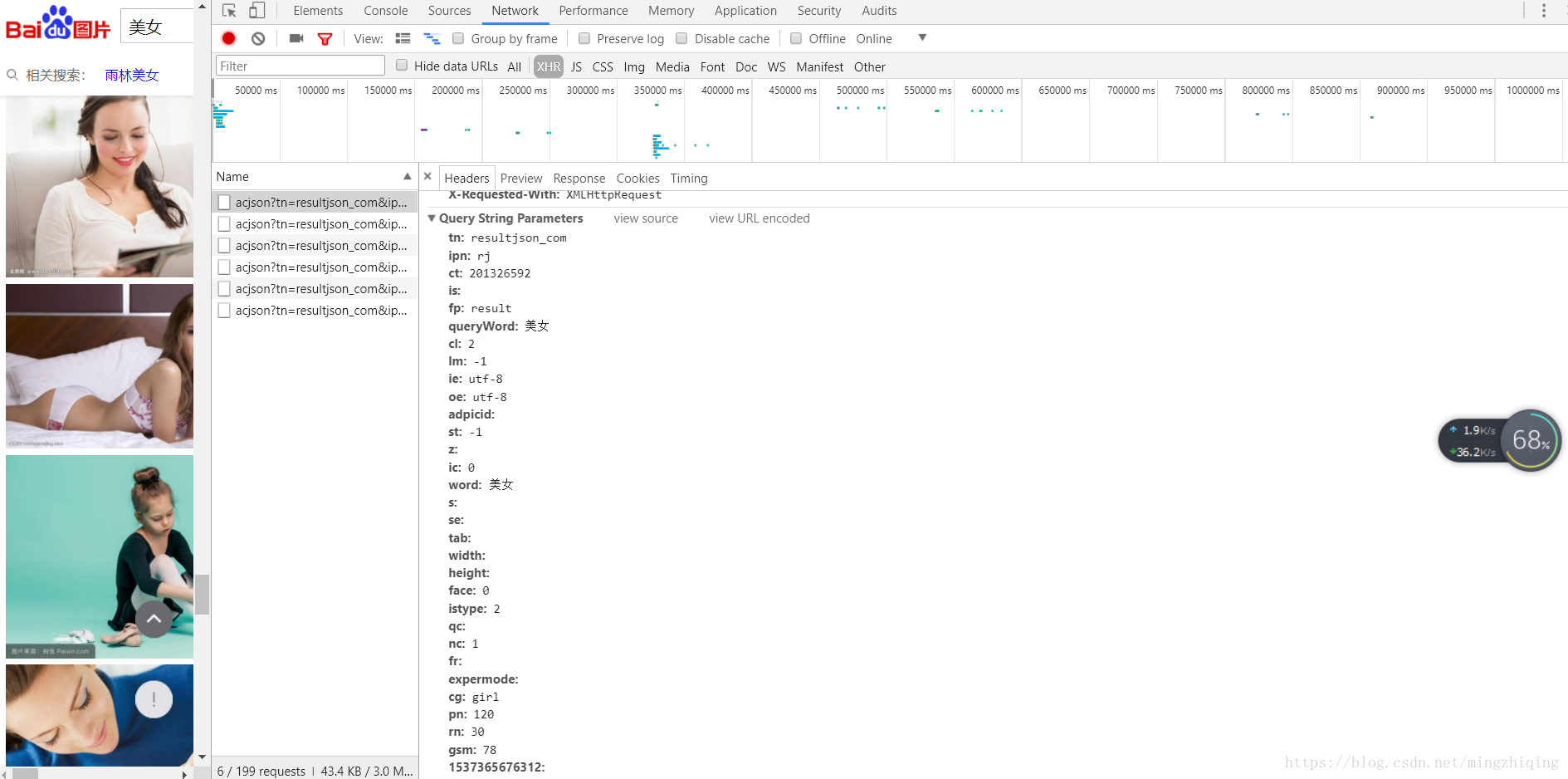
这里的Query String Parameters其实就是我们的请求信息,其中好多都是固定的,需要注意的只有几个:queryWord和word是你的搜索关键字,rn代表一页有多少图,一般取30,pn代表已经显示了多少图,取30*n即可。这样我们对请求的分析就搞定啦,写个代码试一下
首先先import一些常用模块
-
from urllib.parse
import urlencode
-
import requests
-
import re
-
import os
-
-
def get_page(offset):
-
params = {
-
'tn':
'resultjson_com',
-
'ipn':
'rj',
-
'ct':
'201326592',
-
'is':
'',
-
'fp':
'result',
-
'queryWord':
'帅哥',
-
'cl':
'2',
-
'lm':
'-1',
-
'ie':
'utf-8',
-
'oe':
'utf-8',
-
'adpicid':
'',
-
'st':
'-1',
-
'z':
'',
-
'ic':
'0',
-
'word':
'帅哥',
-
's':
'',
-
'se':
'',
-
'tab':
'',
-
'width':
'',
-
'height':
'',
-
'face':
'0',
-
'istype':
'2',
-
'qc':
'',
-
'nc':
'1',
-
'fr':
'',
-
'expermode':
'',
-
'cg':
'girl',
-
'pn': offset*
30,
-
'rn':
'30',
-
'gsm':
'1e',
-
'1537355234668':
'',
-
}
-
url =
'https://image.baidu.com/search/acjson?' + urlencode(params)
-
try:
-
response = requests.get(url)
-
if response.status_code ==
200:
-
return response.json()
-
except requests.ConnectionError
as e:
-
print(
'Error', e.args)
-
-
if __name__==
'__main__':
-
json = get_page(
1)
-
print(json)
-
运行以上代码,输出即为响应的JSON形式,若能成功输出,则请求正确。我们还需要从其中获得图片的地址,过程如下:
在开发者工具中,选择Preview,点开其中的data,发现一堆0,1,2,3....这些就代表了各个图片及其信息,我们点开一个看看,比如点开0:
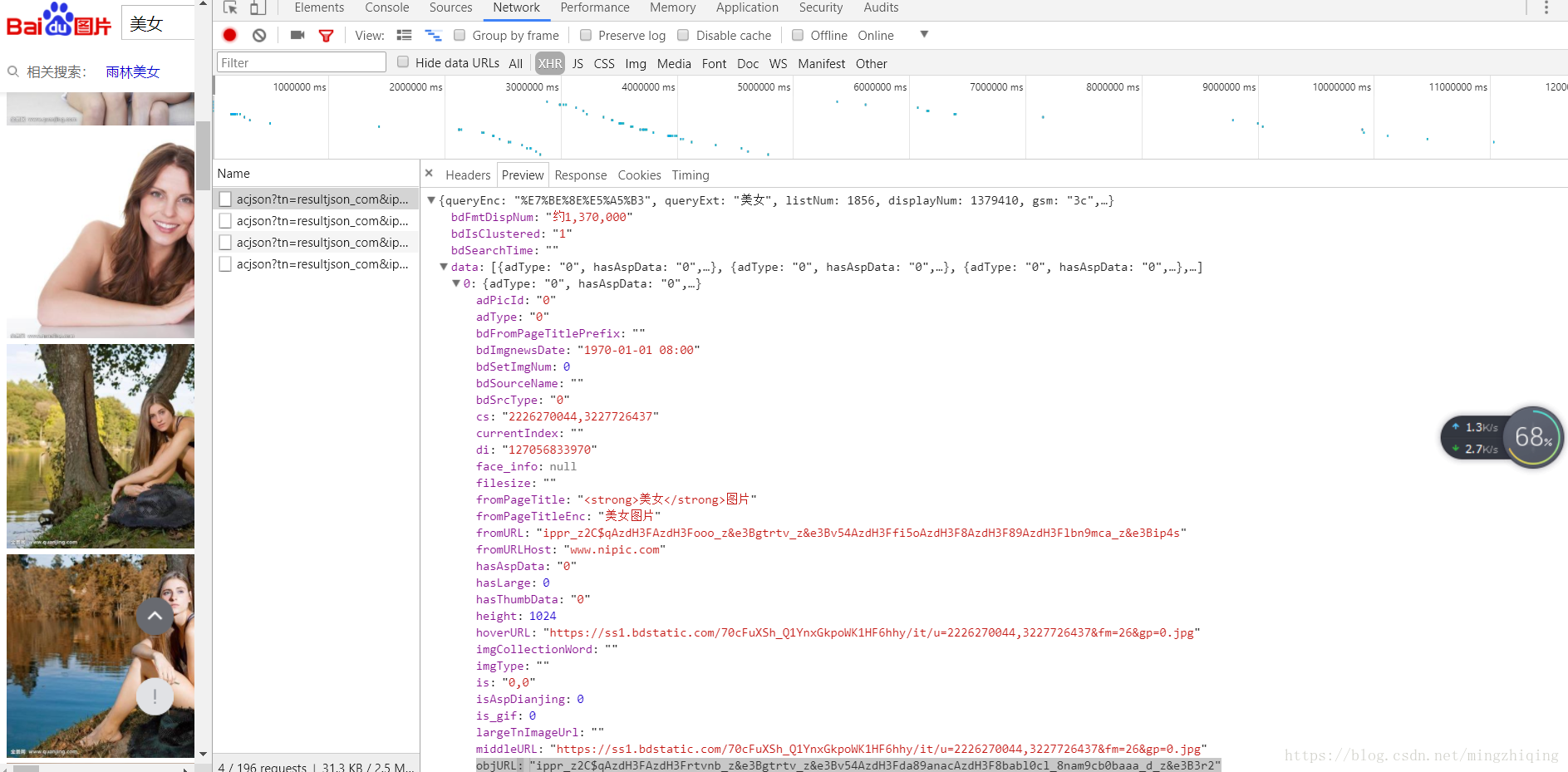
这里面的objURL就是图片的真实地址了,而且是未经压缩的大图哦!等等,这地址怎么看着这么奇怪,这是因为百度对其进行了加密,解密只需要一个函数:
-
def baidtu_uncomplie(url):
-
res =
''
-
c = [
'_z2C$q',
'_z&e3B',
'AzdH3F']
-
d= {
'w':
'a',
'k':
'b',
'v':
'c',
'1':
'd',
'j':
'e',
'u':
'f',
'2':
'g',
'i':
'h',
't':
'i',
'3':
'j',
'h':
'k',
's':
'l',
'4':
'm',
'g':
'n',
'5':
'o',
'r':
'p',
'q':
'q',
'6':
'r',
'f':
's',
'p':
't',
'7':
'u',
'e':
'v',
'o':
'w',
'8':
'1',
'd':
'2',
'n':
'3',
'9':
'4',
'c':
'5',
'm':
'6',
'0':
'7',
'b':
'8',
'l':
'9',
'a':
'0',
'_z2C$q':
':',
'_z&e3B':
'.',
'AzdH3F':
'/'}
-
if(url==
None
or
'http'
in url):
-
return url
-
else:
-
j= url
-
for m
in c:
-
j=j.replace(m,d[m])
-
for char
in j:
-
if re.match(
'^[a-w\d]+$',char):
-
char = d[char]
-
res= res+char
-
return res
只需将objURL作为参数传进去就能返回图片真实地址。那么现在我们只需要写一个能分析响应从而得到objURL的函数,再将objURL变成真实地址,最后将图片下载下来就好了。已经没什么难的了,直接上完整代码:
-
from urllib.parse
import urlencode
-
import requests
-
import re
-
import os
-
save_dir=
'baidutu/'
-
-
def baidtu_uncomplie(url):
-
res =
''
-
c = [
'_z2C$q',
'_z&e3B',
'AzdH3F']
-
d= {
'w':
'a',
'k':
'b',
'v':
'c',
'1':
'd',
'j':
'e',
'u':
'f',
'2':
'g',
'i':
'h',
't':
'i',
'3':
'j',
'h':
'k',
's':
'l',
'4':
'm',
'g':
'n',
'5':
'o',
'r':
'p',
'q':
'q',
'6':
'r',
'f':
's',
'p':
't',
'7':
'u',
'e':
'v',
'o':
'w',
'8':
'1',
'd':
'2',
'n':
'3',
'9':
'4',
'c':
'5',
'm':
'6',
'0':
'7',
'b':
'8',
'l':
'9',
'a':
'0',
'_z2C$q':
':',
'_z&e3B':
'.',
'AzdH3F':
'/'}
-
if(url==
None
or
'http'
in url):
-
return url
-
else:
-
j= url
-
for m
in c:
-
j=j.replace(m,d[m])
-
for char
in j:
-
if re.match(
'^[a-w\d]+$',char):
-
char = d[char]
-
res= res+char
-
return res
-
-
def get_page(offset):
-
params = {
-
'tn':
'resultjson_com',
-
'ipn':
'rj',
-
'ct':
'201326592',
-
'is':
'',
-
'fp':
'result',
-
'queryWord':
'帅哥',
-
'cl':
'2',
-
'lm':
'-1',
-
'ie':
'utf-8',
-
'oe':
'utf-8',
-
'adpicid':
'',
-
'st':
'-1',
-
'z':
'',
-
'ic':
'0',
-
'word':
'帅哥',
-
's':
'',
-
'se':
'',
-
'tab':
'',
-
'width':
'',
-
'height':
'',
-
'face':
'0',
-
'istype':
'2',
-
'qc':
'',
-
'nc':
'1',
-
'fr':
'',
-
'expermode':
'',
-
'pn': offset*
30,
-
'rn':
'30',
-
'gsm':
'1e',
-
'1537355234668':
'',
-
}
-
url =
'https://image.baidu.com/search/acjson?' + urlencode(params)
-
try:
-
response = requests.get(url)
-
if response.status_code ==
200:
-
return response.json()
-
except requests.ConnectionError
as e:
-
print(
'Error', e.args)
-
-
def get_images(json):
-
if json.get(
'data'):
-
for item
in json.get(
'data'):
-
if item.get(
'fromPageTitle'):
-
title = item.get(
'fromPageTitle')
-
else:
-
title=
'noTitle'
-
image = baidtu_uncomplie(item.get(
'objURL'))
-
if(image):
-
yield {
-
'image': image,
-
'title': title
-
}
-
-
def save_image(item,count):
-
try:
-
response = requests.get(item.get(
'image'))
-
if response.status_code ==
200:
-
file_path = save_dir+
'{0}.{1}'.format(str(count),
'jpg')
-
if
not os.path.exists(file_path):
-
with open(file_path,
'wb')
as f:
-
f.write(response.content)
-
else:
-
print(
'Already Downloaded', file_path)
-
except requests.ConnectionError:
-
print(
'Failed to Save Image')
-
-
def main(pageIndex,count):
-
json = get_page(pageIndex)
-
for image
in get_images(json):
-
save_image(image, count)
-
count +=
1
-
return count
-
if __name__==
'__main__':
-
if
not os.path.exists(save_dir):
-
os.mkdir(save_dir)
-
count=
1
-
for i
in range(
1,
20):
-
count=main(i,count)
-
print(
'total:',count)
最后爬下来的图片会以1,2,3,4~命名,最终输出图片总数。