文章转自https://blog.csdn.net/qq_32166627/article/details/60882964
前言:
前面我们爬取图片的网站都是静态的,在页面中右键查看源码就能看到网页中图片的位置。这样我们用requests库得到页面源码后,再用bs4库解析标签即可保存图片到本地。
当我们在看百度图片时,右键–检查–Elements,点击箭头,再用箭头点击图片时,会显示图片的位置和样式。但是,当我们右键查看网页源码时,出来的却是一大堆JavaScript代码,并没有图片的链接等信息。这是为什么呢?
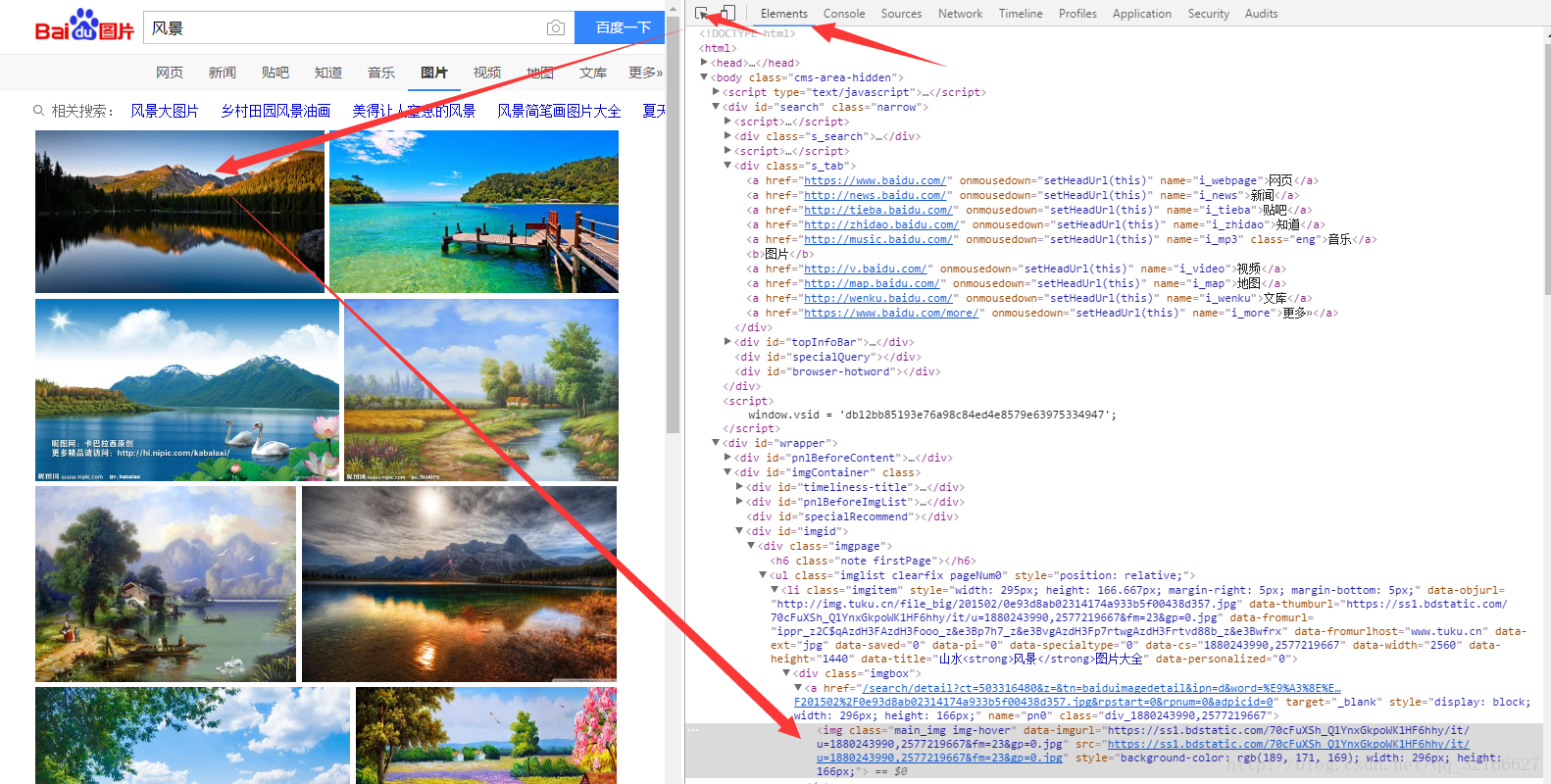

这是因为,百度图片的网页是一个动态页面,它的网页原始数据其实是没有这个图片的,通过运行JavaScript,把这个图片数据把它插入到网页的html标签里面,那这样造成的结果是,我们在开发者工具中虽然能看到这个html标签,但实际上,当我们在看网页的原始数据的时候,其实是没有这个标签的,它只在运行时加载和渲染,那这个时候怎么办呢?怎么把这个图片给下载下来呢?这里面我们就换一个思路,我们就来抓包。
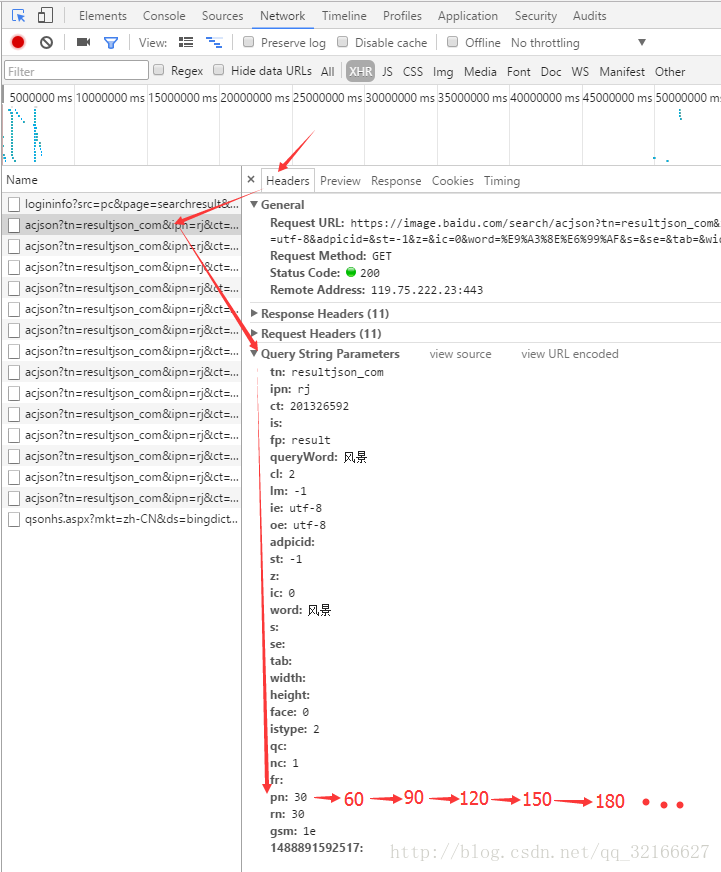
我们点击Network–XHR,然后我们在往下滑动滚动条时,会一直出现一个名为:acjson?tn=resultjson&ipn=…的请求,点击它再点Preview,我们看到这是一条json数据,点开data,我们看到这里面有30条数据,每一条都对应着一张图片。
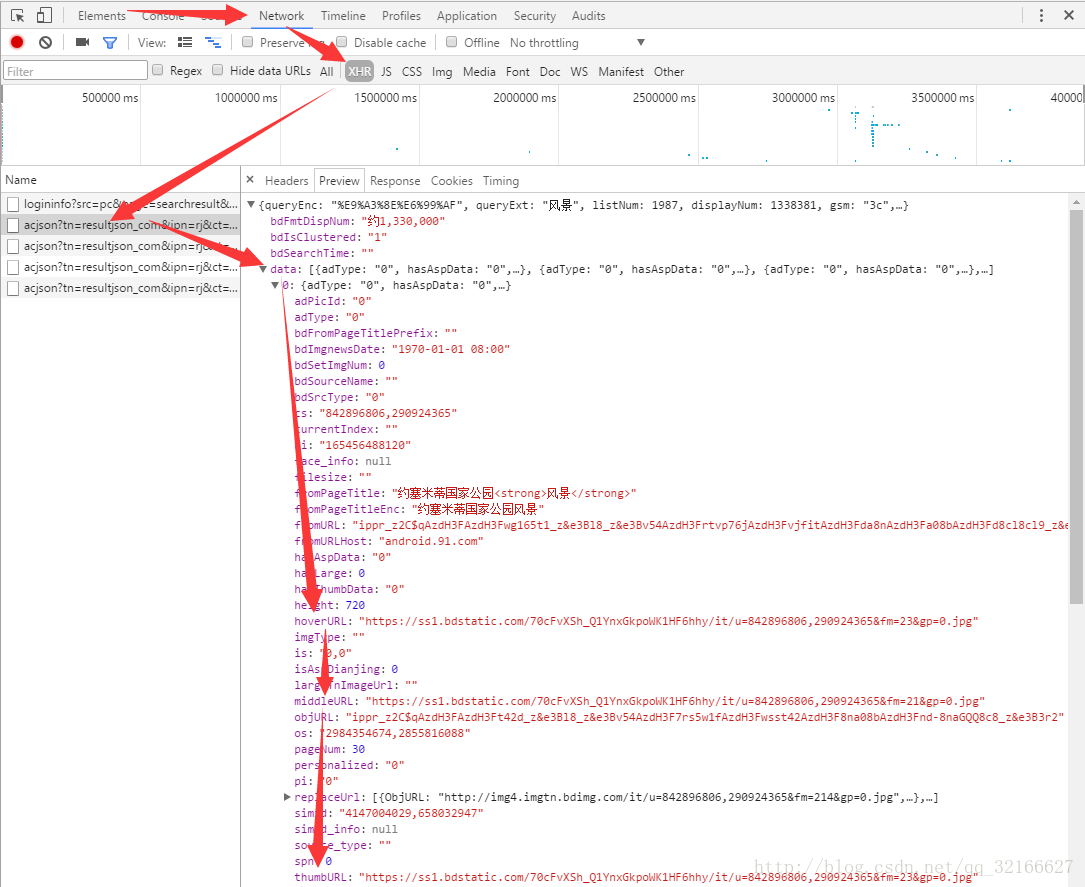
于是我们就清楚了,百度图片一开始只加载30张图片,当我们往下滑动滚动条时,页面会动态加载1条json数据,每条json数据里面包含了30条信息,信息里面又包含了图片的URL,JavaScript会将这些url解析并显示出来。这样,每次滚动到底就又多出30张图片。
那么,这些一直出现的json数据有什么规律呢?我们点击Headers,然后对比这些json数据的头部信息。通过对比,我们发现headers下的Query String Parameters中的字段大多保持不变,只有pn字段保持以30为步长递增。wonderful!这下找到规律啦!