网址为https://tieba.baidu.com/f?ie=utf-8&kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&fr=search
基本思路就是:下载整个页面,然后用正则匹配要下载的内容,最后保存到本地。
1.下载整个页面
定义一个下载器
#首先定义一个下载器,用来下载网页
def load_page(my_url):
#设置代理IP
user_agent=user_agent='Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36'
headers={'User-Agent':user_agent}
response=request.Request(my_url,headers=headers)
results=request.urlopen(response)
html=results.read().decode('utf-8')
return html
my_url=''https://tieba.baidu.com/f?ie=utf-8&kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&fr=search'
html=load_page(my_url)
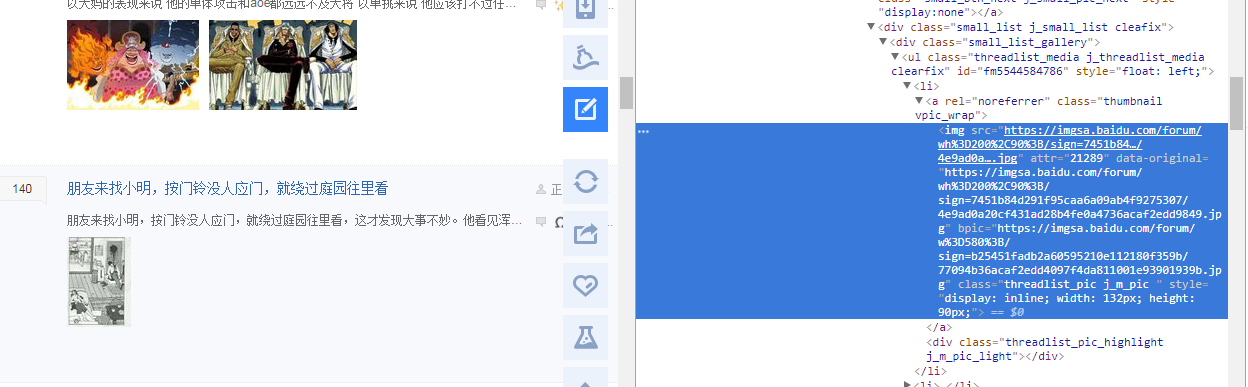
接下来用正则匹配,
img_inf=r'/wh%3D200%2C90%3B/sign=\w+/\w+\.jpg'
img=re.compile(img_inf)
img_list=re.findall(img,html)
返回一个列表
最后保存到本地:
for i in img_list:
img_name=str(i).split('/')[-1]
img_url='https://imgsa.baidu.com/forum%s' % (str(i))
file_path='f:\\wd.python\\tieba_haizeiwang\\%s' %(img_name)
f.write(request.urlopen(img_url).read())
f.close()
结果: