由Mayank Bansal和Abhijit Ogale - Waymo Research
在Waymo,我们专注于建立世界上最有经验的驾驶员。就像任何优秀的驾驶员一样,我们的车辆需要通过识别周围物体并预测下一步可能做什么来感知和理解周围的世界,然后在遵守交通规则的同时决定如何安全驾驶。
近年来,使用大量标记数据的深度神经网络的监督训练迅速改进了许多领域的最新技术,特别是在物体感知和预测领域,并且这些技术在Waymo中被广泛使用。 。随着神经网络对感知的成功,我们自然会问自己一个问题:鉴于我们有数百万英里的驾驶数据(即专家驾驶演示),我们是否可以使用纯监督的深度学习方法培训熟练的驾驶员?
这篇文章 - 基于我们刚刚发布的研究* - 描述了一种探索,以突破我们如何利用专家数据创建神经网络的界限,该神经网络不仅能够在模拟中的挑战性情况下驾驶汽车,而且还可靠足以在我们的私人测试设施中驾驶真正的车辆。如下所述,简单模仿大量专家演示不足以创建一种有能力且可靠的自驱动技术。相反,我们发现从良好的感知和控制开始,简化学习任务,为模型提供额外的损失,模拟坏事而不仅仅是模仿好事,这是有价值的。
创建司机网:一种用于驾驶的递归神经网络
为了通过模仿专家来驾驶,我们创建了一个名为ChauffeurNet的深度递归神经网络(RNN),通过观察场景的中级表示作为输入来训练发出驾驶轨迹。中级表示不直接使用原始传感器数据,从而将感知任务分解出来,并允许我们将真实数据和模拟数据相结合,以便更容易地进行转移学习。如下图所示,此输入表示包括一个自上而下(鸟瞰)环境视图,其中包含地图,周围物体,交通信号灯状态,汽车过去运动等信息。上。该网络还具有谷歌,地图风格的路线,可引导其前往目的地。
ChauffeurNet在每次迭代期间沿关系着未来驾驶轨迹输出一个点,同时将预测点写入在下一次迭代期间使用的存储器。从这个意义上讲,RNN并不是传统的,因为内存模型是明确制作的。然后,ChauffeurNet将由十个未来点组成的轨迹输出到一个低级控制器,该控制器将其转换为控制命令,例如转向和加速,以便驱动汽车。
此外,我们采用了一个单独的“PerceptionRNN”头,迭代地预测环境中其他移动物体的未来,并且该网络与预测我们自己驾驶的RNN共享特征。未来的一种可能性是在选择我们自己的驾驶轨迹的同时更深入地交叉预测其他代理人的反应的过程。

为驾驶模型渲染输入和输出。从左到右的顶行:路线图,红绿灯,限速和路线。从左到右的下排:当前代理框,动态框,过去的代理人姿势和输出的未来代理人姿势。
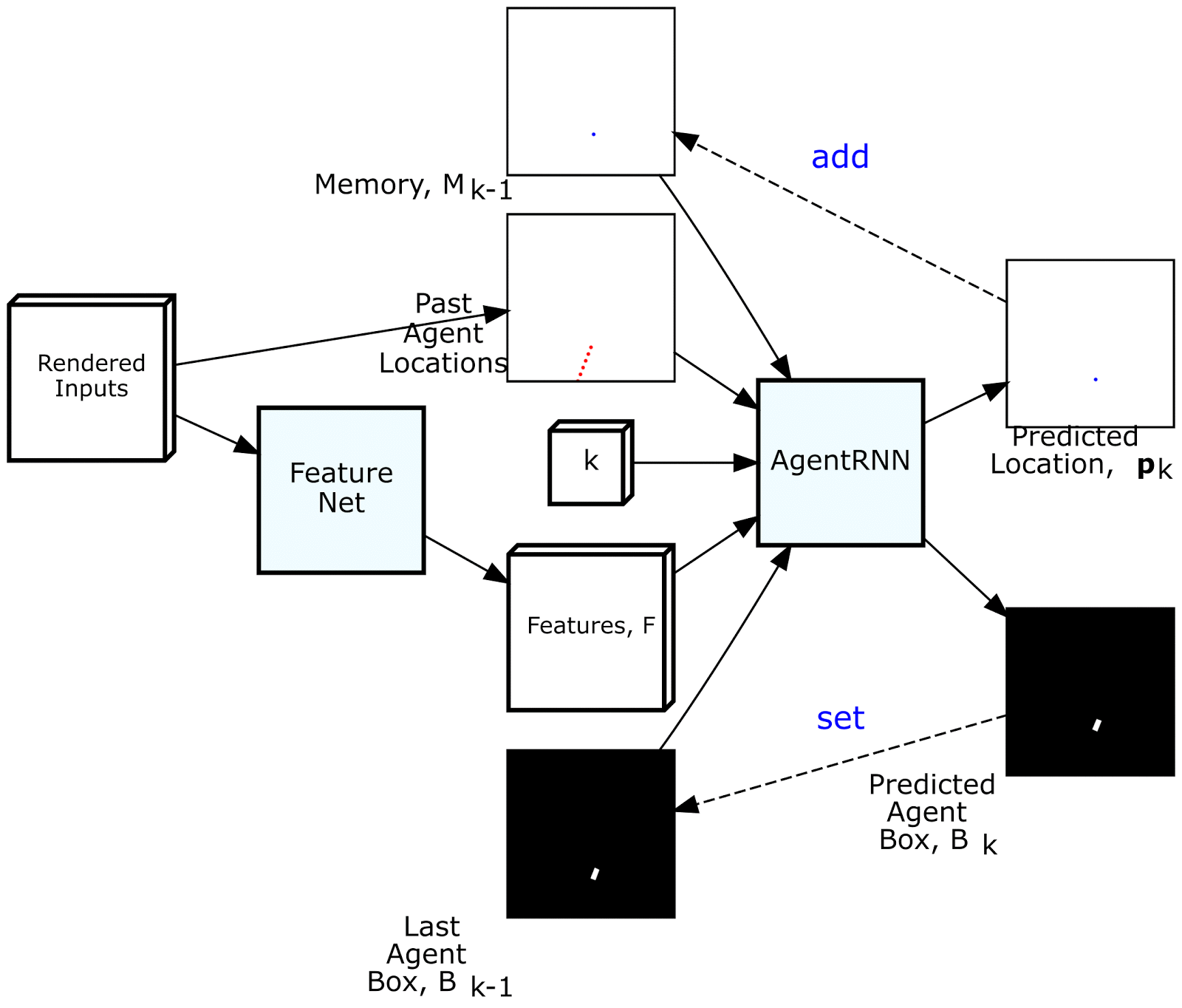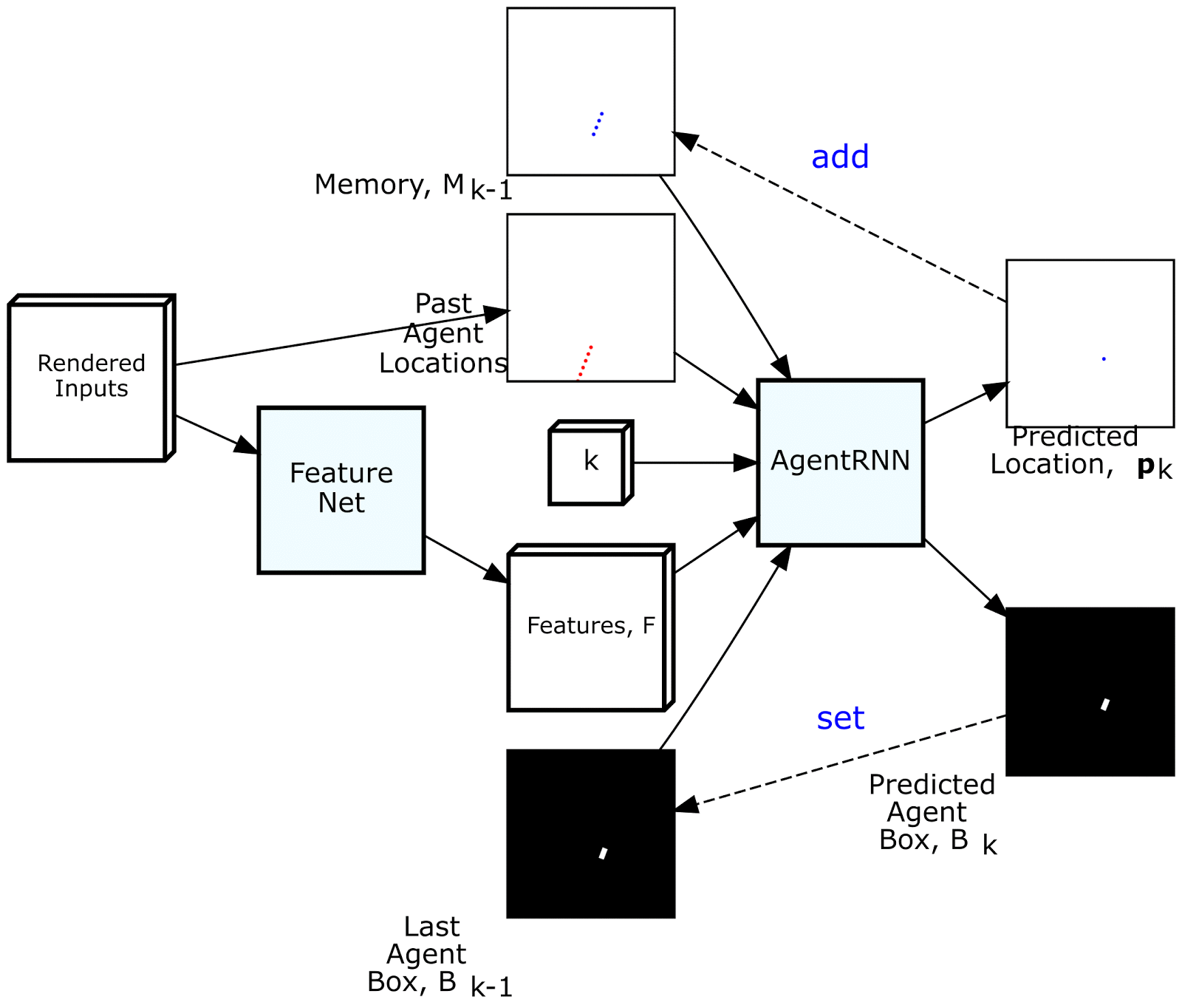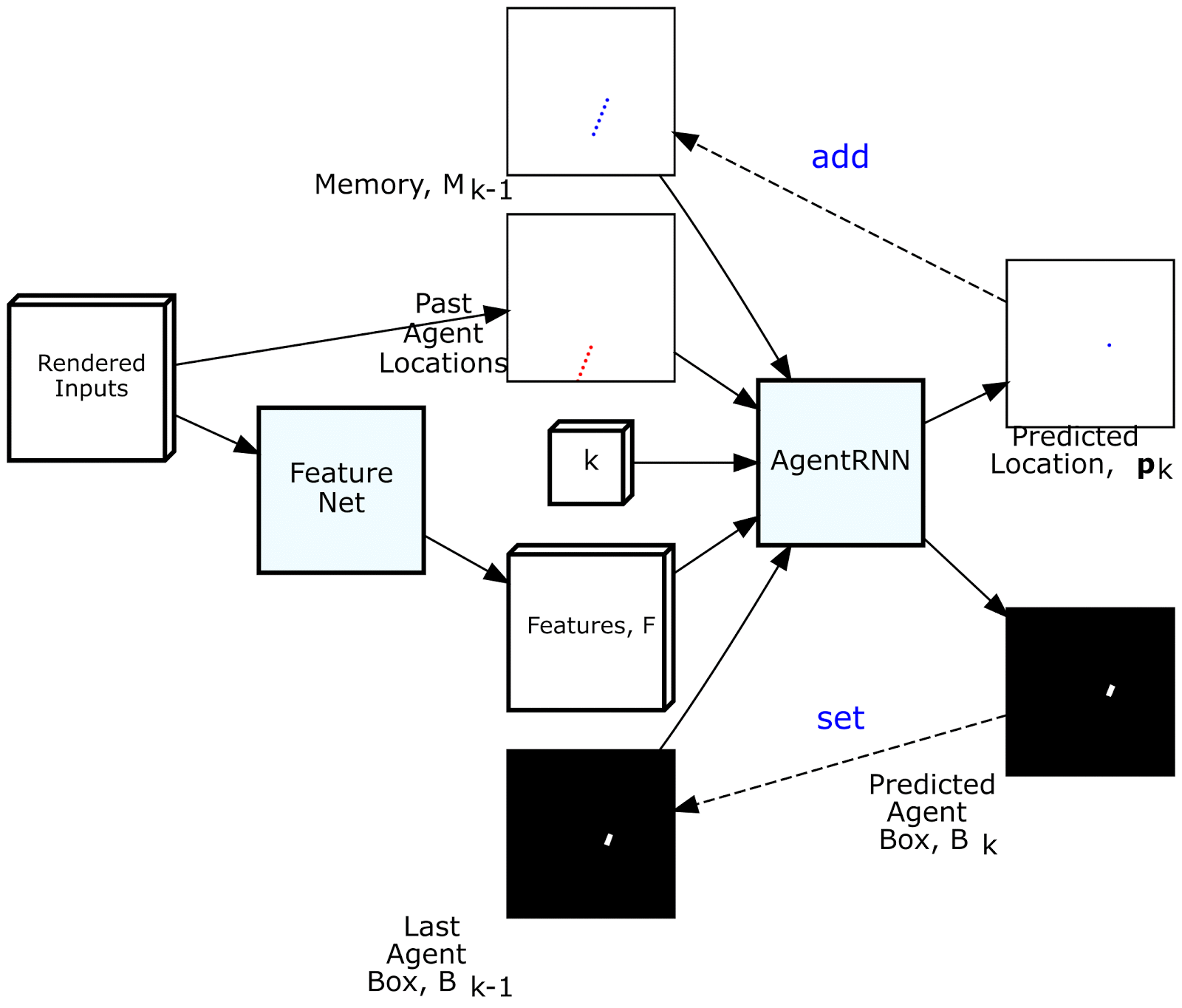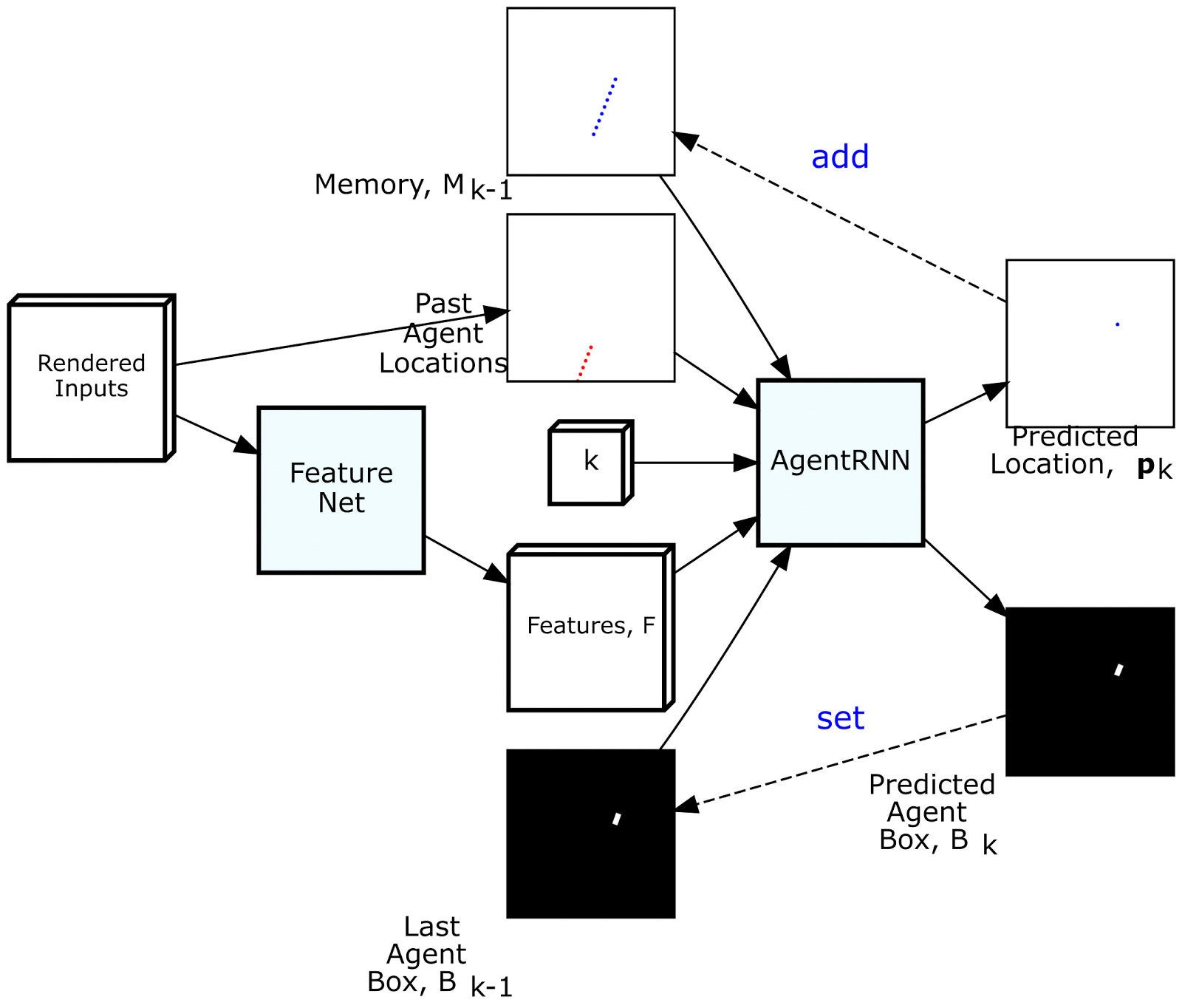
ChauffeurNet有两个内部部分,FeatureNet和AgentRNN。AgentRNN使用过去代理构成的渲染图像,由渲染输入的卷积网络“FeatureNet”计算的一组特征,具有最后一个代理框渲染的图像,以及具有预测渲染的显式存储器将来的代理构成预测下一个代理人姿势和自上而下视图中的下一个代理框。这些预测用于更新AgentRNN的输入以预测下一个时间步长。
模仿好
我们使用相当于约60天的专家驾驶数据的示例训练模型,同时包括过去运动辍学等训练技术,以确保网络不会简单地继续从其过去的运动中推断并实际对环境做出正确响应。正如许多人在我们面前发现的那样,包括ALVINN项目早在20世纪80年代,纯粹模仿专家给出了一个表现平稳的模型,只要情况不会偏离训练中看到的太多。该模型学会对停车标志和交通信号灯等交通管制做出适当的响应。然而,诸如对轨道引入扰动或将其置于近碰撞情况中的偏差导致其表现不佳,因为即使在训练大量数据时,它也可能在训练期间从未见过这些确切的情况。
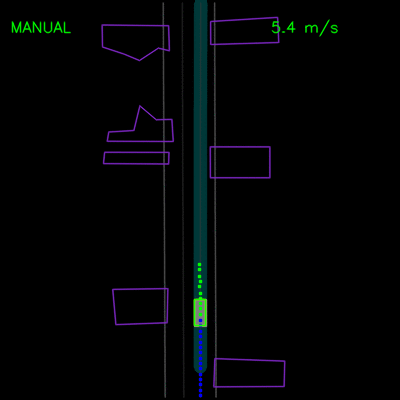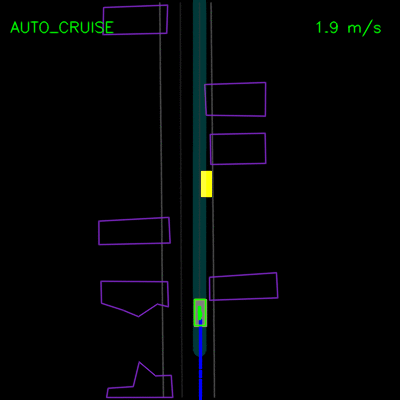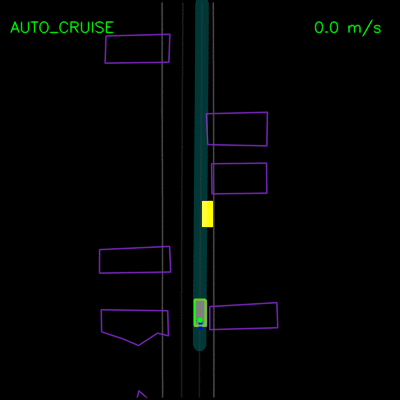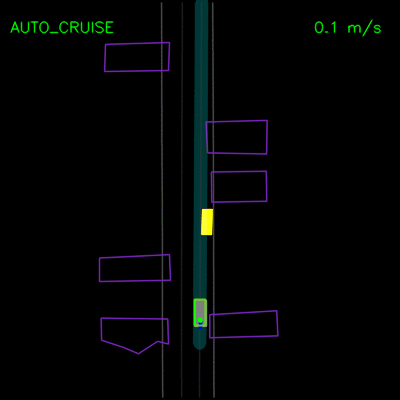
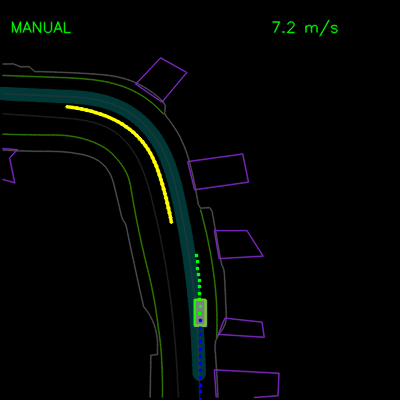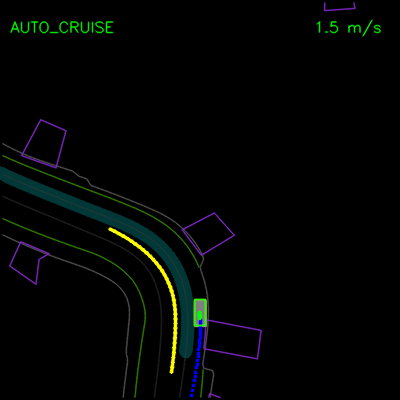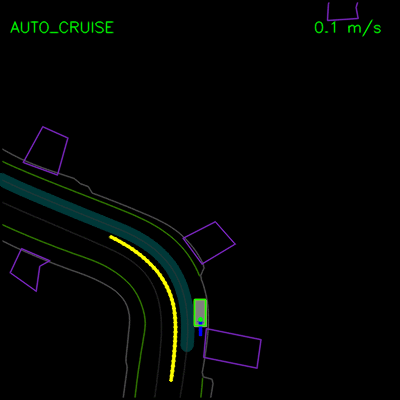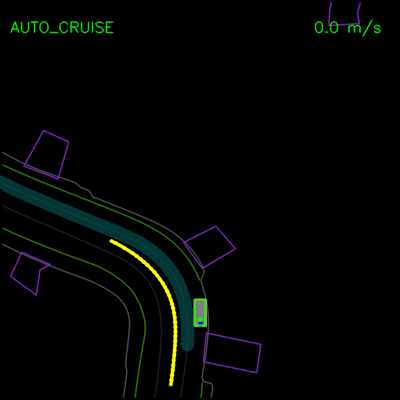
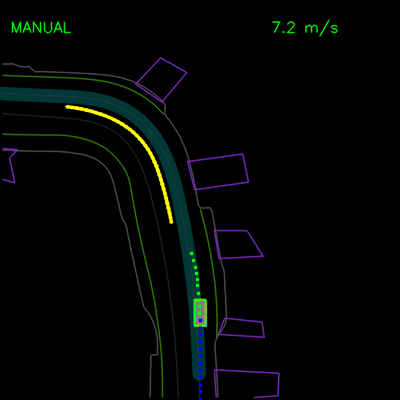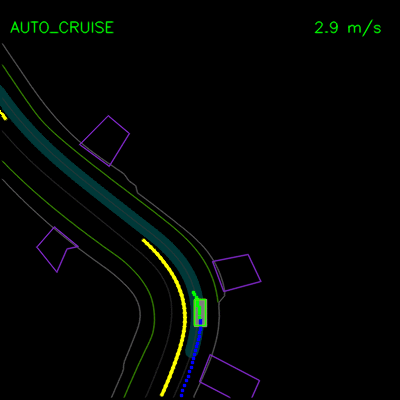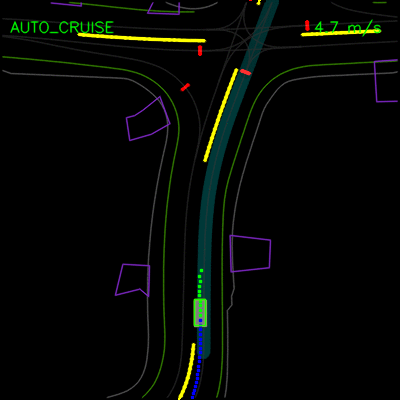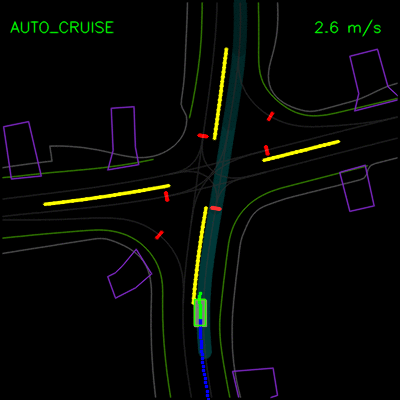
用纯模仿学习训练的特工被困在停放的车辆后面(左),并且在沿着弯曲的道路(右)行驶时无法从轨迹偏离中恢复。青色路径描绘输入路线,黄色框是场景中的动态对象,绿色框是代理,蓝色点是代理的过去位置,绿色点是预测的未来位置。
合成坏
从真实世界驾驶中获得的专家驾驶演示通常仅包含在良好情况下驾驶的示例,因为出于显而易见的原因,我们不希望我们的专业驾驶员进入近距离碰撞或攀爬路缘仅仅为了向神经网络展示如何恢复在这些情况下。为了训练网络摆脱困境,模拟或综合合适的训练数据是有意义的。一种简单的方法是通过添加我们扰乱驾驶轨迹的案例来完成专家的实际操作。扰动使得轨迹的起点和终点保持不变,偏差主要发生在中间。这教导神经网络如何从扰动中恢复。不仅如此,这些扰动产生了与其他物体或道路路缘的合成碰撞的例子,我们教网络通过增加明显的损失来避免这些冲突,从而阻止这种冲突。这些损失使我们能够利用领域知识来指导学习在新情况下更好地概括。
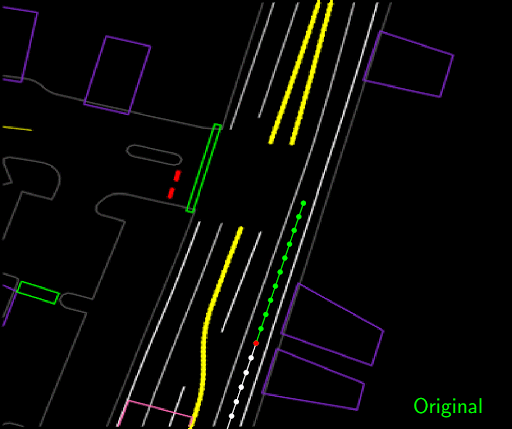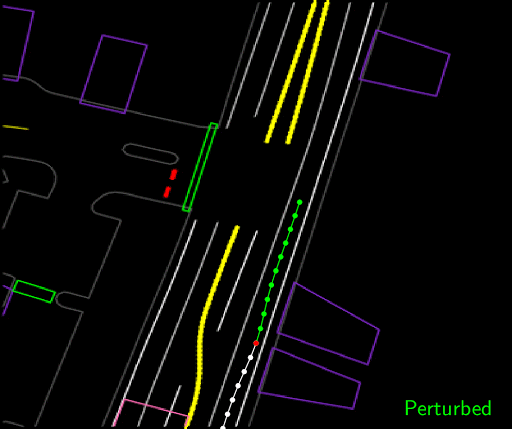
通过拉动当前代理位置(红点)远离车道中心然后拟合新的平滑轨迹,使代理返回到沿着车道中心的原始目标位置来进行轨迹扰动。
这项工作演示了使用合成数据的一种方法。除了我们的方法之外,可以执行对高度交互或罕见情况的广泛模拟,同时使用强化学习(RL)来调整驾驶政策。然而,做RL需要我们准确地模拟环境中其他代理人的现实行为,包括其他车辆,行人和骑自行车者。出于这个原因,我们在当前的工作中专注于纯粹的监督学习方法,记住我们的模型可以用于创建自然行为的“智能代理”用于自举RL。
实验结果
我们看到纯模仿学习模型如何在一辆停放的车辆周围轻推,并在上方的轨迹偏差中卡住。通过全套合成示例和辅助损失,我们的完整ChauffeurNet模型现在可以成功地在停放的车辆周围轻推(左)并从轨迹偏离中恢复以沿着弯曲道路(右)平稳地继续。
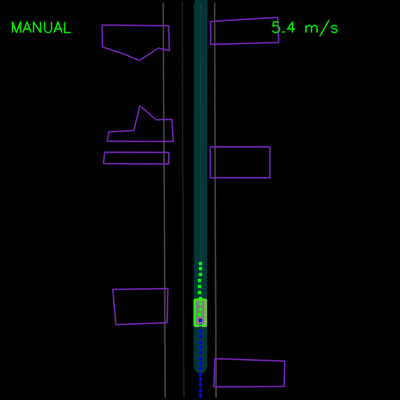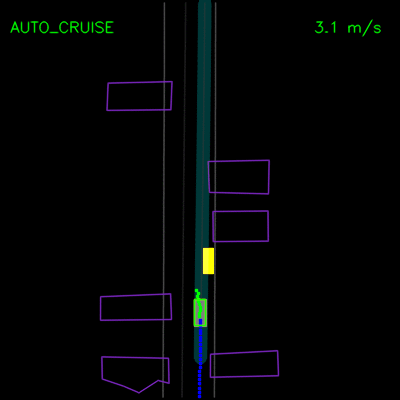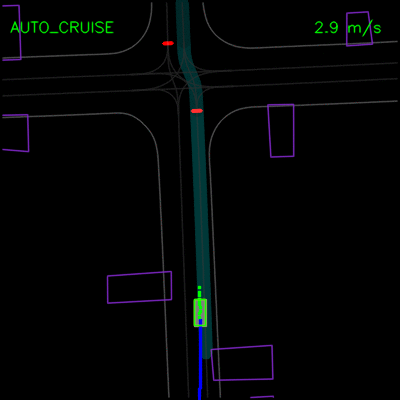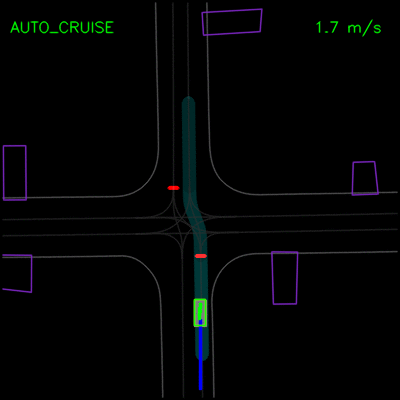
在下面的示例中,我们演示了ChauffeurNet对模拟器中closed-loop设置中记录示例的正确因果因素的响应。在左侧动画中,我们看到ChauffeurNet代理在停止标志(红色标记)之前完全停止。在右侧动画中,我们从渲染道路中删除停止标志,并看到代理不再完全停止,验证网络是否正在响应正确的因果因素。
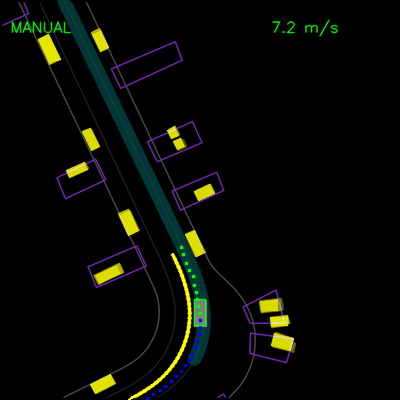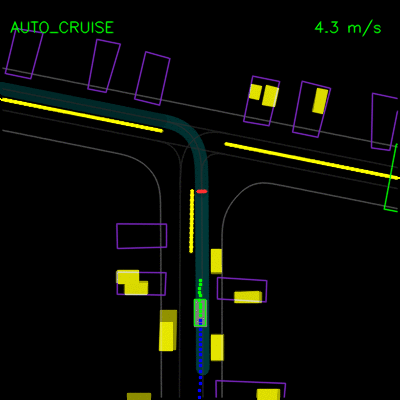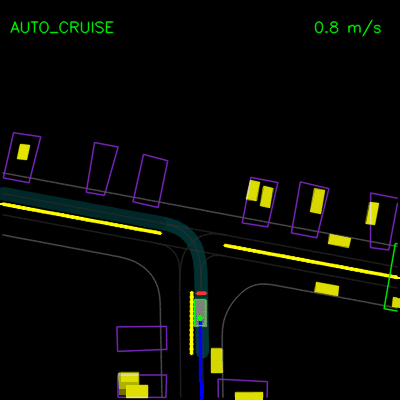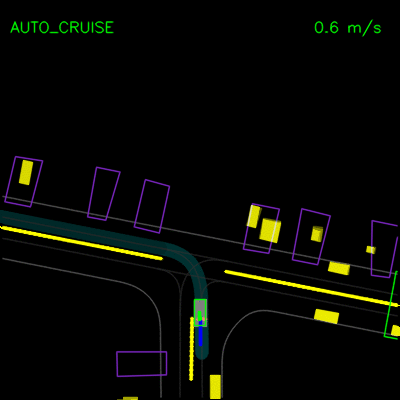
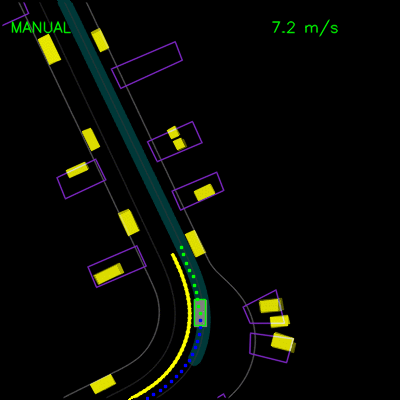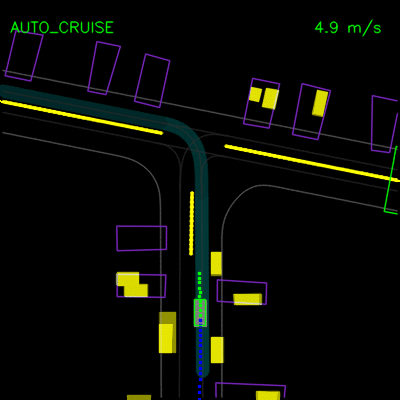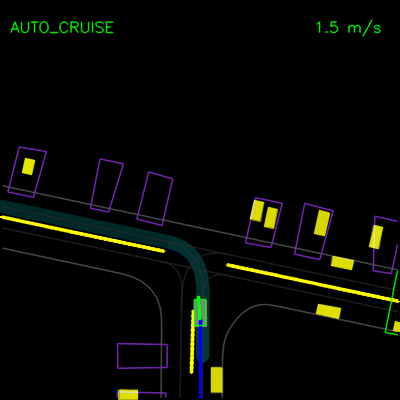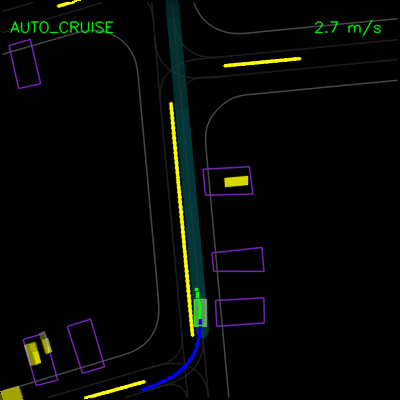
在下面的左侧动画中,我们看到ChauffeurNet代理停在其他车辆后面(黄色方框),然后在其他车辆移动时继续。在右侧动画中,我们从渲染输入中移除其他车辆,并看到代理自然地继续沿路径行进,因为路径中没有其他对象,验证网络对场景中其他车辆的响应。
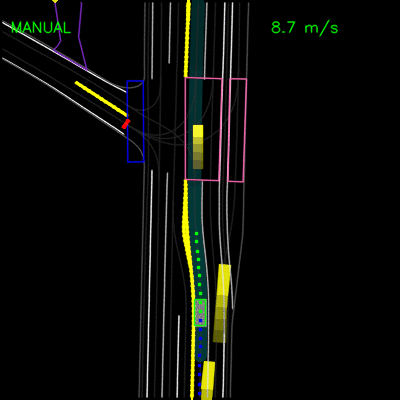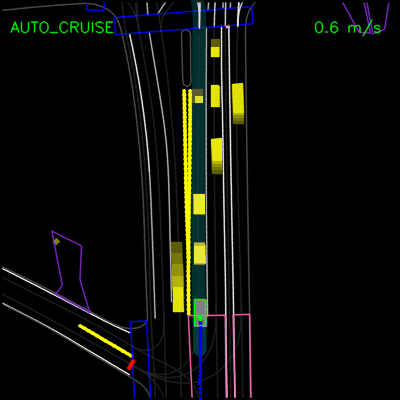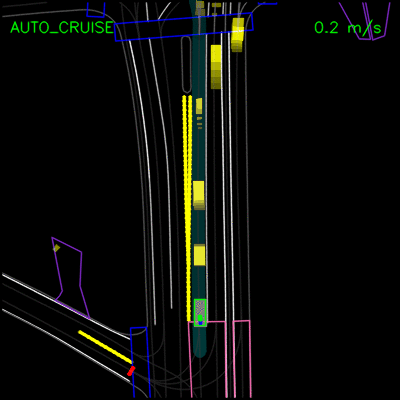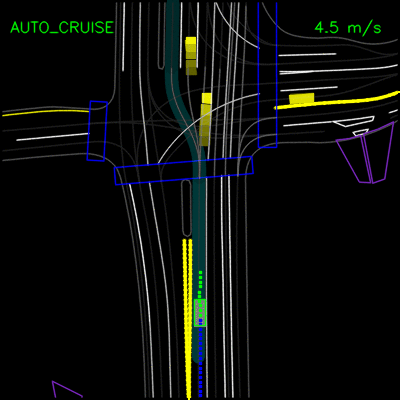
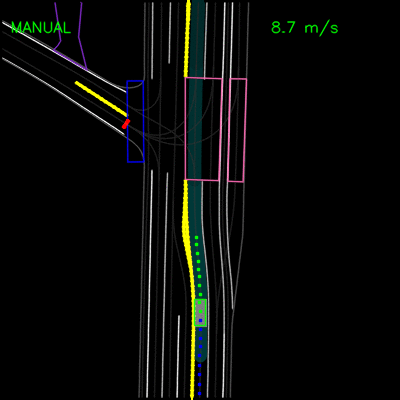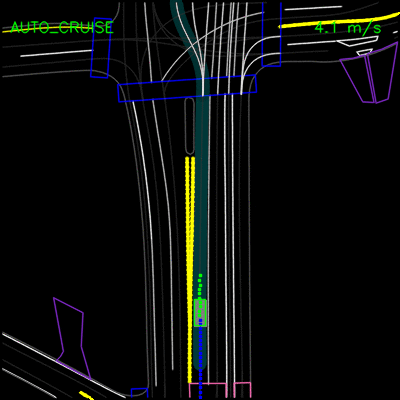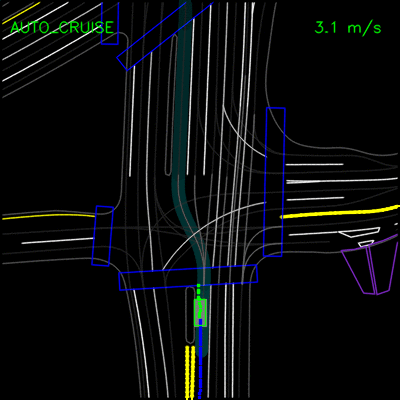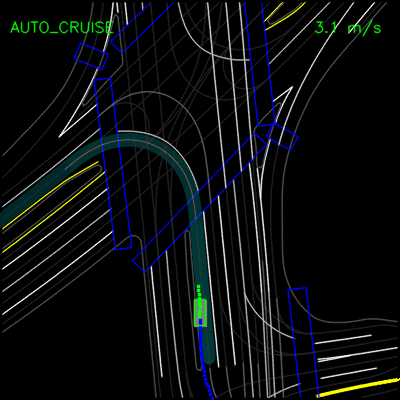
在下面的示例中,ChauffeurNet代理停止交通信号灯从黄色转换为红色(注意交通信号灯渲染强度的变化,显示为沿车道中心的曲线),而不是盲目跟随其他车辆。
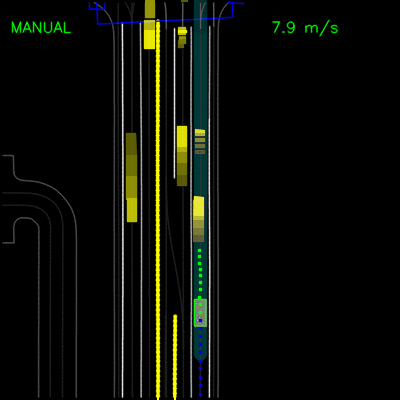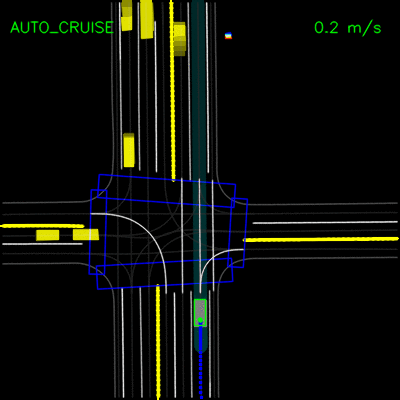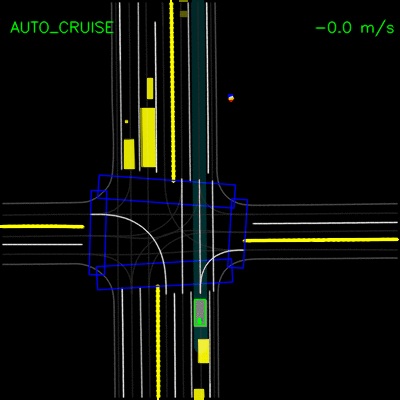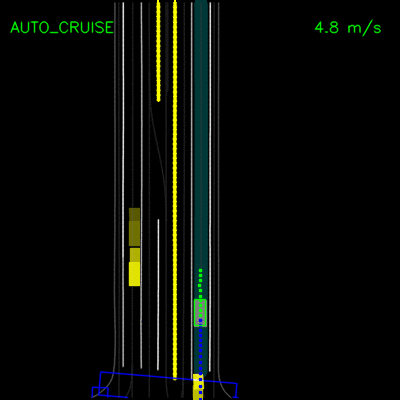
在模拟测试后,我们用ChauffeurNet替换了我们的主要计划模块,并用它在我们的私人测试轨道上驾驶克莱斯勒Pacifica小型货车。这些视频演示了车辆成功跟随弯道并处理停车标志和转弯。
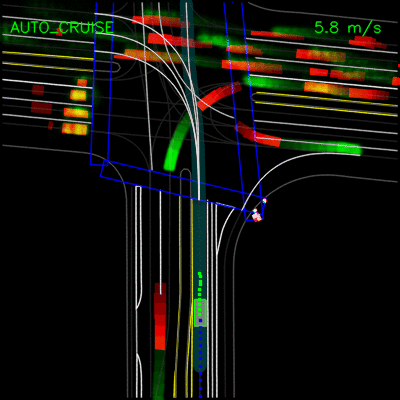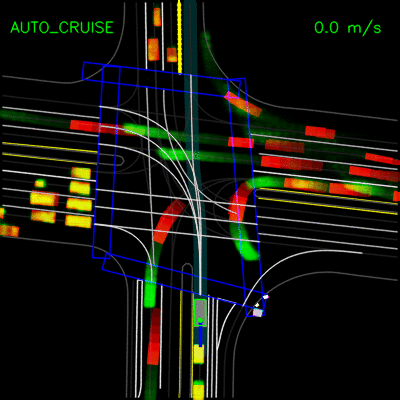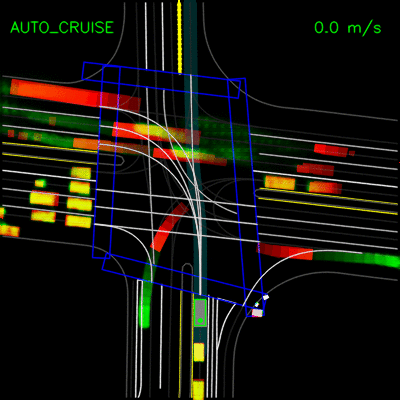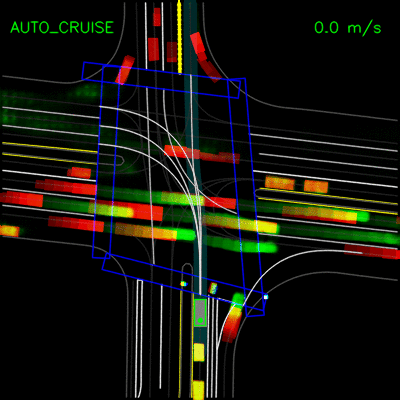
下面的示例演示了PerceptionRNN对已记录示例的预测。回想一下,PerceptionRNN预测其他动态对象的未来运动。红色轨迹表示场景中动态物体的过去轨迹; 绿色轨迹表示每个物体在未来两秒内的预测轨迹。
长尾,因果关系和终身学习
完全自动驾驶系统需要能够处理现实世界中发生的长尾事件。虽然深度学习在许多应用中取得了相当大的成功,但处理稀缺培训数据的情况仍然是一个悬而未决的问题 此外,深度学习识别训练数据中的相关性,但可以说,它不能通过纯粹观察相关性来构建因果模型,并且无法在模拟中主动测试反事实。知道为什么和老练的驾驶员表现他们的方式是什么,他们反应是建立驾驶的因果模型的关键。出于这个原因,仅仅进行大量的模拟专家演示是不够的。理解为什么更容易知道如何改进这样的系统,这对于安全关键应用尤为重要。此外,如果可以以渐进和有针对性的方式执行此类改进,则系统可以无限地继续学习和改进。这种持续的终身学习是机器学习社区的一个活跃的研究领域。
今天在Waymo车辆上运行的规划器使用机器学习和明确推理的组合来持续评估大量可能性,并在各种不同场景中做出最佳驾驶决策,这些场景已被磨练超过1000万英里的公路测试仿真数十亿英里。因此,用于替换Waymo规划器的完全机器学习系统的标准非常高,尽管来自这样的系统的组件可以在Waymo规划器中使用,或者可以用于在模拟测试期间创建更真实的“智能代理”。规划师。
处理长尾情况,理解因果关系和持续的终身学习是Waymo以及更广泛的机器学习社区积极研究的主题。当我们在机器学习中解决这些具有挑战性的问题时,我们一直在寻找有才华的研究人员加入我们,请联系waymo.com/joinus。
有关此工作的更多详细信息,请参阅我们的论文:
* 司机网:通过模仿最佳和合成最糟糕的
Mayank Bansal
学习驾驶,Alex Krizhevsky,Abhijit Ogale (补充材料)
关注更多前沿科技,深入了解自动驾驶技术请参考:https://mp.csdn.net/postedit/87932784 加入群聊共享资源,交流学习。
waymo自动驾驶技术ChauffeurNet,Learning to Drive: Beyond Pure Imitation论文