架构图:
看网上文档要用Spark开发搭建环境是挺麻烦的,需要多台机器安装Hadoop,还要建立和修改许多配置文件,有没有简单一点的方法呢?
作者研究了一下,发现了一种非常简便的方法,能让小盆友们快速上手Spark又避免复杂安装命令。
研究了Spark的支持方面,我发现Spark2.2和mongodb3.4这两个家伙已经宣布了互相支持。这下子狼狈为奸,一脚踢开复杂难用的Hadoop了。
废话不多说,直接安装mongodb吧。我在官网下载了mongodb的windows安装版本,mongodb-win32-x86_64-2008plus-ssl-3.4.7-signed.msi
链接在这里,
https://www.mongodb.com/download-center?jmp=nav#community
mongodb安装出奇简单,一路下一步就完成了。
运行文件在
C:\Program Files\MongoDB\Server\3.4\bin
复杂的命令不用说,先记住两个命令就可以了。
启动服务命令:
mongod.exe --dbpath D:\mgdbData
控制台命令:
mongo.exe
然后,就是打开Eclipse撸代码了。作者的运行环境JDK8,Eclipse Version: Oxygen Release (4.7.0)
先建立一个pom.xml下载一些相关jar包:
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.mongodb.spark</groupId>
<artifactId>mongo-spark-connector_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.2.0</version>
</dependency>
</dependencies>
经过漫长等待(跟网速有关系),jar全部下好了,就可以开始开发了。
==================================================================
第一个程序:
package myspark;
import com.mongodb.spark.MongoSpark;
import com.mongodb.spark.config.WriteConfig;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.SparkSession;
import org.bson.Document;
import static java.util.Arrays.asList;
import java.util.HashMap;
import java.util.Map;
public final class WriteToMongoDBWriteConfig {
public static void main(final String[] args) throws InterruptedException {
SparkSession spark = SparkSession.builder()
.master("local")
.appName("MongoSparkConnectorIntro")
.config("spark.mongodb.input.uri", "mongodb://127.0.0.1/test.myCollection")
.config("spark.mongodb.output.uri", "mongodb://127.0.0.1/test.myCollection")
.getOrCreate();
JavaSparkContext jsc = new JavaSparkContext(spark.sparkContext());
// Create a custom WriteConfig
Map<String, String> writeOverrides = new HashMap<String, String>();
writeOverrides.put("collection", "spark");
writeOverrides.put("writeConcern.w", "majority");
WriteConfig writeConfig = WriteConfig.create(jsc).withOptions(writeOverrides);
// Create a RDD of 10 documents
//这里有Lambad表达式的方式与下面语句等价
//JavaRDD<Integer> sparkDocuments2 = jsc.parallelize(asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10));
//sparkDocuments2.map(iparam -> Document.parse("{spark: " + iparam + "}"));
JavaRDD<Document> sparkDocuments = jsc.parallelize(asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)).map
(new Function<Integer, Document>() {
public Document call(final Integer i) throws Exception {
return Document.parse("{spark: " + i + "}");
}
});
/*Start Example: Save data from RDD to MongoDB*****************/
MongoSpark.save(sparkDocuments, writeConfig);
/*End Example**************************************************/
jsc.close();
}
}
==============================================================
这个程序就是写入一些Spark用的实验数据。
可能的结果如下:
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
17/09/11 14:56:18 INFO SparkContext: Running Spark version 2.2.0
17/09/11 14:56:18 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/09/11 14:56:18 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:378)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:393)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:386)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:79)
at org.apache.hadoop.security.Groups.parseStaticMapping(Groups.java:116)
at org.apache.hadoop.security.Groups.<init>(Groups.java:93)
at org.apache.hadoop.security.Groups.<init>(Groups.java:73)
at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:293)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:283)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:260)
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:789)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:774)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:647)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2430)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2430)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2430)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:295)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2509)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:909)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:901)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:901)
at myspark.WriteToMongoDBWriteConfig.main(WriteToMongoDBWriteConfig.java:28)
17/09/11 14:56:18 INFO SparkContext: Submitted application: MongoSparkConnectorIntro
17/09/11 14:56:18 INFO SecurityManager: Changing view acls to: zhouxj
17/09/11 14:56:18 INFO SecurityManager: Changing modify acls to: zhouxj
17/09/11 14:56:18 INFO SecurityManager: Changing view acls groups to:
17/09/11 14:56:18 INFO SecurityManager: Changing modify acls groups to:
17/09/11 14:56:18 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(zhouxj); groups with view permissions: Set(); users with modify permissions: Set(zhouxj); groups with modify permissions: Set()
17/09/11 14:56:18 INFO Utils: Successfully started service 'sparkDriver' on port 49309.
17/09/11 14:56:18 INFO SparkEnv: Registering MapOutputTracker
17/09/11 14:56:18 INFO SparkEnv: Registering BlockManagerMaster
17/09/11 14:56:19 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
17/09/11 14:56:19 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
17/09/11 14:56:19 INFO DiskBlockManager: Created local directory at C:\Users\zhouxj\AppData\Local\Temp\blockmgr-5e64f280-5841-4048-a9c7-e6700798f101
17/09/11 14:56:19 INFO MemoryStore: MemoryStore started with capacity 899.7 MB
17/09/11 14:56:19 INFO SparkEnv: Registering OutputCommitCoordinator
17/09/11 14:56:19 INFO Utils: Successfully started service 'SparkUI' on port 4040.
17/09/11 14:56:19 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.1.215:4040
17/09/11 14:56:19 INFO Executor: Starting executor ID driver on host localhost
17/09/11 14:56:19 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 49318.
17/09/11 14:56:19 INFO NettyBlockTransferService: Server created on 192.168.1.215:49318
17/09/11 14:56:19 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
17/09/11 14:56:19 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.1.215, 49318, None)
17/09/11 14:56:19 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.1.215:49318 with 899.7 MB RAM, BlockManagerId(driver, 192.168.1.215, 49318, None)
17/09/11 14:56:19 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.1.215, 49318, None)
17/09/11 14:56:19 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 192.168.1.215, 49318, None)
17/09/11 14:56:19 INFO SharedState: Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir ('file:/D:/workspSVN/MdSpark/spark-warehouse/').
17/09/11 14:56:19 INFO SharedState: Warehouse path is 'file:/D:/workspSVN/MdSpark/spark-warehouse/'.
17/09/11 14:56:20 INFO StateStoreCoordinatorRef: Registered StateStoreCoordinator endpoint
17/09/11 14:56:21 INFO SparkContext: Starting job: foreachPartition at MongoSpark.scala:117
17/09/11 14:56:21 INFO DAGScheduler: Got job 0 (foreachPartition at MongoSpark.scala:117) with 1 output partitions
17/09/11 14:56:21 INFO DAGScheduler: Final stage: ResultStage 0 (foreachPartition at MongoSpark.scala:117)
17/09/11 14:56:21 INFO DAGScheduler: Parents of final stage: List()
17/09/11 14:56:21 INFO DAGScheduler: Missing parents: List()
17/09/11 14:56:21 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at WriteToMongoDBWriteConfig.java:39), which has no missing parents
17/09/11 14:56:21 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 3.4 KB, free 899.7 MB)
17/09/11 14:56:21 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 2.0 KB, free 899.7 MB)
17/09/11 14:56:21 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.1.215:49318 (size: 2.0 KB, free: 899.7 MB)
17/09/11 14:56:21 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1006
17/09/11 14:56:21 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at WriteToMongoDBWriteConfig.java:39) (first 15 tasks are for partitions Vector(0))
17/09/11 14:56:21 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
17/09/11 14:56:21 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 4927 bytes)
17/09/11 14:56:21 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
17/09/11 14:56:21 INFO cluster: Cluster created with settings {hosts=[127.0.0.1:27017], mode=SINGLE, requiredClusterType=UNKNOWN, serverSelectionTimeout='30000 ms', maxWaitQueueSize=500}
17/09/11 14:56:21 INFO cluster: Cluster description not yet available. Waiting for 30000 ms before timing out
17/09/11 14:56:22 INFO connection: Opened connection [connectionId{localValue:1, serverValue:24}] to 127.0.0.1:27017
17/09/11 14:56:22 INFO cluster: Monitor thread successfully connected to server with description ServerDescription{address=127.0.0.1:27017, type=STANDALONE, state=CONNECTED, ok=true, version=ServerVersion{versionList=[3, 4, 7]}, minWireVersion=0, maxWireVersion=5, maxDocumentSize=16777216, roundTripTimeNanos=619094}
17/09/11 14:56:22 INFO MongoClientCache: Creating MongoClient: [127.0.0.1:27017]
17/09/11 14:56:22 INFO connection: Opened connection [connectionId{localValue:2, serverValue:25}] to 127.0.0.1:27017
17/09/11 14:56:22 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 794 bytes result sent to driver
17/09/11 14:56:22 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 675 ms on localhost (executor driver) (1/1)
17/09/11 14:56:22 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
17/09/11 14:56:22 INFO DAGScheduler: ResultStage 0 (foreachPartition at MongoSpark.scala:117) finished in 0.698 s
17/09/11 14:56:22 INFO DAGScheduler: Job 0 finished: foreachPartition at MongoSpark.scala:117, took 0.902204 s
17/09/11 14:56:22 INFO SparkUI: Stopped Spark web UI at http://192.168.1.215:4040
17/09/11 14:56:22 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
17/09/11 14:56:22 INFO MemoryStore: MemoryStore cleared
17/09/11 14:56:22 INFO BlockManager: BlockManager stopped
17/09/11 14:56:22 INFO BlockManagerMaster: BlockManagerMaster stopped
17/09/11 14:56:22 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
17/09/11 14:56:22 INFO SparkContext: Successfully stopped SparkContext
17/09/11 14:56:22 INFO ShutdownHookManager: Shutdown hook called
17/09/11 14:56:22 INFO ShutdownHookManager: Deleting directory C:\Users\zhouxj\AppData\Local\Temp\spark-ece38a7d-ac50-47ea-8c31-2bcb8ba109a8
17/09/11 14:56:22 INFO MongoClientCache: Closing MongoClient: [127.0.0.1:27017]
17/09/11 14:56:22 INFO connection: Closed connection [connectionId{localValue:2, serverValue:25}] to 127.0.0.1:27017 because the pool has been closed.
======================================================================
喔擦~,为啥报错了,但是不用管,程序依然可以运行。
去控制台看看后台数据是否写对了。
cd C:\Program Files\MongoDB\Server\3.4\bin
mongo.exe
use test
db.spark.find()
==============================================
输出结果:
{ "_id" : ObjectId("59b6112c6b69d22bf071e478"), "spark" : 1 }
{ "_id" : ObjectId("59b6112c6b69d22bf071e479"), "spark" : 2 }
{ "_id" : ObjectId("59b6112c6b69d22bf071e47a"), "spark" : 3 }
{ "_id" : ObjectId("59b6112c6b69d22bf071e47b"), "spark" : 4 }
{ "_id" : ObjectId("59b6112c6b69d22bf071e47c"), "spark" : 5 }
{ "_id" : ObjectId("59b6112c6b69d22bf071e47d"), "spark" : 6 }
{ "_id" : ObjectId("59b6112c6b69d22bf071e47e"), "spark" : 7 }
{ "_id" : ObjectId("59b6112c6b69d22bf071e47f"), "spark" : 8 }
{ "_id" : ObjectId("59b6112c6b69d22bf071e480"), "spark" : 9 }
{ "_id" : ObjectId("59b6112c6b69d22bf071e481"), "spark" : 10 }
{ "_id" : ObjectId("59b611c66b69d237a04559d4"), "spark" : 1 }
{ "_id" : ObjectId("59b611c66b69d237a04559d5"), "spark" : 2 }
{ "_id" : ObjectId("59b611c66b69d237a04559d6"), "spark" : 3 }
{ "_id" : ObjectId("59b611c66b69d237a04559d7"), "spark" : 4 }
{ "_id" : ObjectId("59b611c66b69d237a04559d8"), "spark" : 5 }
{ "_id" : ObjectId("59b611c66b69d237a04559d9"), "spark" : 6 }
{ "_id" : ObjectId("59b611c66b69d237a04559da"), "spark" : 7 }
{ "_id" : ObjectId("59b611c66b69d237a04559db"), "spark" : 8 }
{ "_id" : ObjectId("59b611c66b69d237a04559dc"), "spark" : 9 }
{ "_id" : ObjectId("59b611c66b69d237a04559dd"), "spark" : 10 }
============================================================================================
第二个程序就是读数据了
import java.util.HashMap;
import java.util.Map;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SparkSession;
import org.bson.Document;
import com.mongodb.spark.MongoSpark;
import com.mongodb.spark.config.ReadConfig;
import com.mongodb.spark.rdd.api.java.JavaMongoRDD;
public final class ReadFromMongoDBReadConfig {
public static void main(final String[] args) throws InterruptedException {
SparkSession spark = SparkSession.builder()
.master("local")
.appName("MongoSparkConnectorIntro")
.config("spark.mongodb.input.uri", "mongodb://127.0.0.1/test.myCollection")
.config("spark.mongodb.output.uri", "mongodb://127.0.0.1/test.myCollection")
.getOrCreate();
// Create a JavaSparkContext using the SparkSession's SparkContext object
JavaSparkContext jsc = new JavaSparkContext(spark.sparkContext());
/*Start Example: Read data from MongoDB************************/
// Create a custom ReadConfig
Map<String, String> readOverrides = new HashMap<String, String>();
readOverrides.put("collection", "spark");
readOverrides.put("readPreference.name", "secondaryPreferred");
ReadConfig readConfig = ReadConfig.create(jsc).withOptions(readOverrides);
// Load data using the custom ReadConfig
JavaMongoRDD<Document> customRdd = MongoSpark.load(jsc, readConfig);
/*End Example**************************************************/
// Analyze data from MongoDB
System.out.println(customRdd.count());
System.out.println(customRdd.first().toJson());
System.out.println(customRdd.toString());
jsc.close();
}
}
--------------------------------------------------------------------------------
看到如下输出:
17/09/11 15:01:35 INFO DAGScheduler: Job 1 finished: first at ReadFromMongoDBReadConfig.java:44, took 0.041804 s
{ "_id" : { "$oid" : "59b6112c6b69d22bf071e478" }, "spark" : 1 }
MongoRDD[0] at RDD at MongoRDD.scala:52
=========================================================================
第三个程序条件搜索了
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SparkSession;
import org.bson.Document;
import com.mongodb.spark.MongoSpark;
import com.mongodb.spark.config.ReadConfig;
import com.mongodb.spark.rdd.api.java.JavaMongoRDD;
import static java.util.Collections.singletonList;
import java.util.HashMap;
import java.util.Map;
public final class Aggregation {
public static void main(final String[] args) throws InterruptedException {
System.setProperty("hadoop.home.dir", "D:\\mgdbData");
SparkSession spark = SparkSession.builder()
.master("local")
.appName("MongoSparkConnectorIntro")
.config("spark.mongodb.input.uri", "mongodb://127.0.0.1/test.myCollection")
.config("spark.mongodb.output.uri", "mongodb://127.0.0.1/test.myCollection")
.getOrCreate();
// Create a JavaSparkContext using the SparkSession's SparkContext object
JavaSparkContext jsc = new JavaSparkContext(spark.sparkContext());
//
// // Load and analyze data from MongoDB
// JavaMongoRDD<Document> rdd = MongoSpark.load(jsc);
// Create a custom ReadConfig
Map<String, String> readOverrides = new HashMap<String, String>();
readOverrides.put("collection", "spark");
readOverrides.put("readPreference.name", "secondaryPreferred");
ReadConfig readConfig = ReadConfig.create(jsc).withOptions(readOverrides);
// Load data using the custom ReadConfig
JavaMongoRDD<Document> rdd = MongoSpark.load(jsc, readConfig);
/*Start Example: Use aggregation to filter a RDD***************/
JavaMongoRDD<Document> aggregatedRdd = rdd.withPipeline(
singletonList(
Document.parse("{ $match: { spark : { $gt : 5 } } }")));
/*End Example**************************************************/
// Analyze data from MongoDB
System.out.println(aggregatedRdd.count());
System.out.println(aggregatedRdd.first().toJson());
jsc.close();
}
}
---------------------------------------------------------------------------------
输出结果:
17/09/11 15:06:48 INFO BlockManagerInfo: Removed broadcast_1_piece0 on 192.168.1.215:49430 in memory (size: 2.0 KB, free: 899.7 MB)
20
17/09/11 15:06:48 INFO SparkContext: Starting job: first at Aggregation.java:52
17/09/11 15:06:48 INFO DAGScheduler: Got job 1 (first at Aggregation.java:52) with 1 output partitions
17/09/11 15:06:48 INFO DAGScheduler: Final stage: ResultStage 1 (first at Aggregation.java:52)
17/09/11 15:06:48 INFO DAGScheduler: Parents of final stage: List()
17/09/11 15:06:48 INFO DAGScheduler: Missing parents: List()
17/09/11 15:06:48 INFO DAGScheduler: Submitting ResultStage 1 (MongoRDD[1] at RDD at MongoRDD.scala:52), which has no missing parents
17/09/11 15:06:48 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 3.5 KB, free 899.7 MB)
17/09/11 15:06:48 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 2.1 KB, free 899.7 MB)
17/09/11 15:06:48 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.1.215:49430 (size: 2.1 KB, free: 899.7 MB)
17/09/11 15:06:48 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:1006
17/09/11 15:06:48 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (MongoRDD[1] at RDD at MongoRDD.scala:52) (first 15 tasks are for partitions Vector(0))
17/09/11 15:06:48 INFO TaskSchedulerImpl: Adding task set 1.0 with 1 tasks
17/09/11 15:06:48 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, executor driver, partition 0, ANY, 4981 bytes)
17/09/11 15:06:48 INFO Executor: Running task 0.0 in stage 1.0 (TID 1)
17/09/11 15:06:48 INFO Executor: Finished task 0.0 in stage 1.0 (TID 1). 1085 bytes result sent to driver
17/09/11 15:06:48 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 19 ms on localhost (executor driver) (1/1)
17/09/11 15:06:48 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
17/09/11 15:06:48 INFO DAGScheduler: ResultStage 1 (first at Aggregation.java:52) finished in 0.020 s
17/09/11 15:06:48 INFO DAGScheduler: Job 1 finished: first at Aggregation.java:52, took 0.045374 s
{ "_id" : { "$oid" : "59b6112c6b69d22bf071e47d" }, "spark" : 6 }
17/09/11 15:06:48 INFO SparkUI: Stopped Spark web UI at http://192.168.1.215:4040
================================================================
运行结果似乎有点问题,但是程序是跑起来了。
下面解决讨厌的异常,不是说不需要Hadoop嘛,粑粑就不服了。网上搜索解决方案,发现了最简单的方法。
去下载一个winutils.exe,然后在程序里加上配置项就可以了。
System.setProperty("hadoop.home.dir", "D:\\mgdbData");
winutils.exe下载在这里的链接:
https://github.com/srccodes/hadoop-common-2.2.0-bin
解压缩后,把文件都丢到D:\mgdbData\bin下就可以了。
==========================================================================
RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集
RDD是Spark的核心,也是整个Spark的架构基础。它的特性可以总结如下:
- 它是不变的数据结构存储
- 它是支持跨集群的分布式数据结构
- 可以根据数据记录的key对结构进行分区
- 提供了粗粒度的操作,且这些操作都支持分区
- 它将数据存储在内存中,从而提供了低延迟性
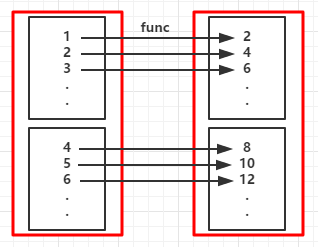
例如:
JavaRDD<String> lines = sc.textFile("data.txt");
JavaRDD<Integer> lineLengths = lines.map(new Function<String, Integer>() {
public Integer call(String s) { return s.length(); }
});
int totalLength = lineLengths.reduce(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer a, Integer b) { return a + b; }
});