1、打开Scala IDE for Eclipse的官网,官网地址:http://scala-ide.org/
2、点击Download IDE。
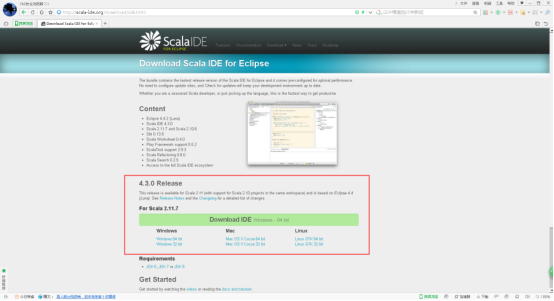
3、下载对应的版本。
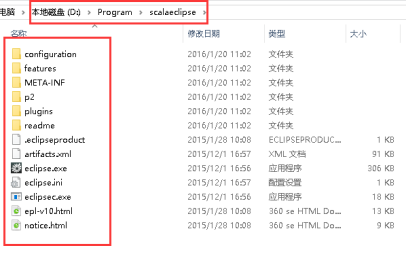
4、scala-SDK-4.3.0-vfinal-2.11-win32.win32.x86_64.zip为例,解压缩。
5、双击打开eclipse.exe。

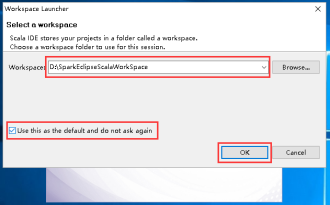
6、选择一个工作目录,然后点击OK。
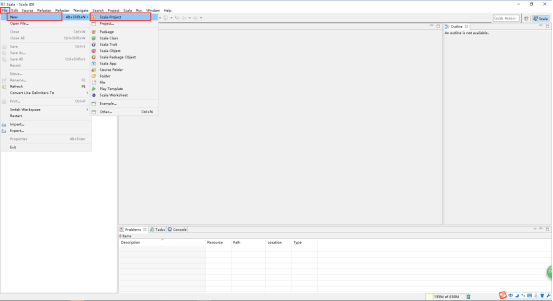
7、在打开的窗口中,File -> New -> Scala Project。
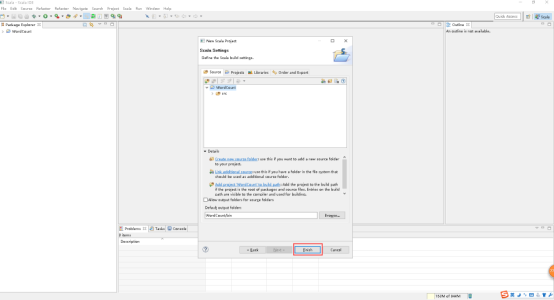
8、写好Project name,点击Next。

9、点击Finish。
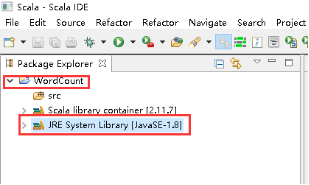
10、修改JRE System Library。
11、右击JRE System Library -> Build Path -> Configure Build Path...。

12、点击JRE System Library -> Edit。

13、选择Alternate JRE -> Installed JREs...。

14、点击Add...。

15、选择Standard VM,点击Next。
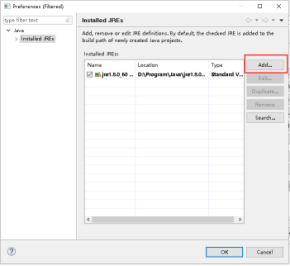
16、点击Directory...,选择本地文件安装JDK的安装目录,点击Finish。
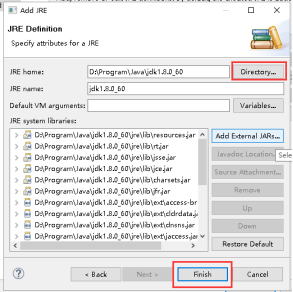
17、选择刚才加入的JDK,点击OK。
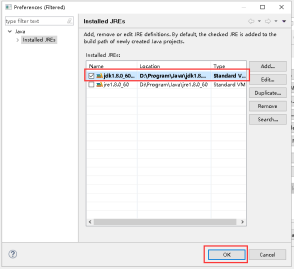
18、下拉列表里选择刚才加入的JDK,点击Finish。
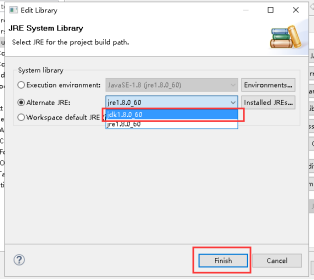
19、点击OK。

20、设置Scala library container。
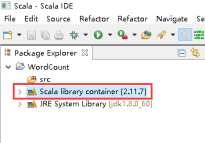
21、项目上有右击 -> Properties。
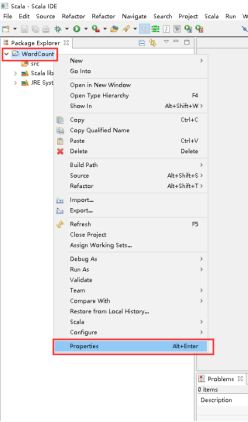
22、打开的窗口点击Scala Compiler。
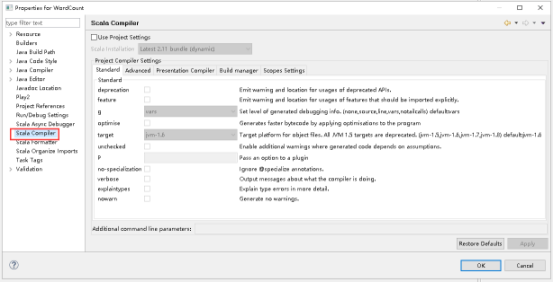
23、Use Project Settings打钩,打开Scala Installation下拉列表,选择Latest 2.10 bundle(dynamic),点击OK。
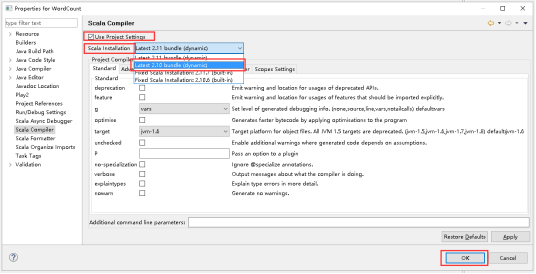
24、点击OK。
25、下载spark-1.6.0-bin-hadoop2.6.tgz,解压spark-1.6.0-bin-hadoop2.6.tgz,解压以后目录如下:
26、添加Spark的jar依赖,项目右击 -> Build Path -> Configure Build Path...。
27、点击Libraries -> Add External JARs...。

28、选择lib目录下的spark-assembly-1.6.0-hadoop2.6.0.jar文件,点击打开。
29、点击OK。

30、项目里创建包,右击src -> New -> Package。
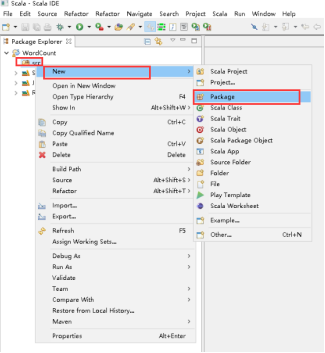
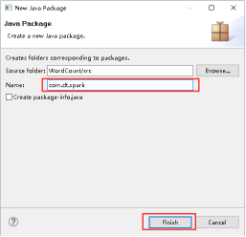
31、填写好Name,点击Finish。
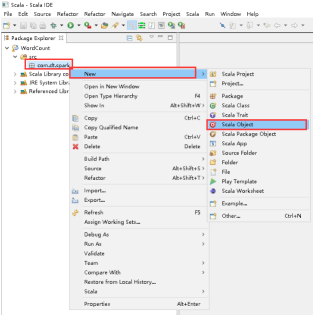
32、创建Scala Object,右击com.dt.spark -> New -> Scala Object。
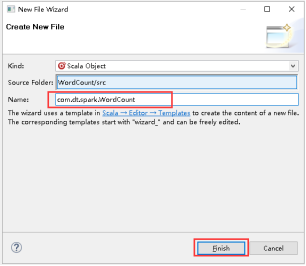
33、填写好Name,点击Finish。
34、开始编写WordCount,写Title。
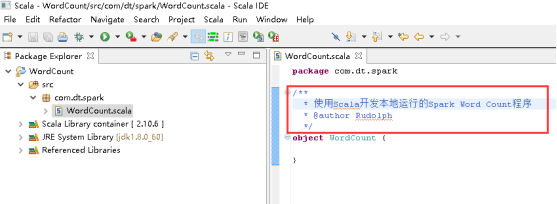
35、添加main方法。

36、创建SparkConf对象,图里的第1步。

37、创建SparkContext对象,图里的第2步。

38、读取本地文件,图里的第3步

39、将每一行的字符串拆分成单个的单词,图里的第4.1步。
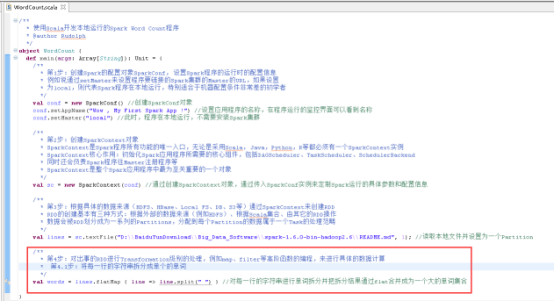
40、在单词拆分的基础上对每个单词实例计数为1,也就是word => (word, 1),图里4.2步。
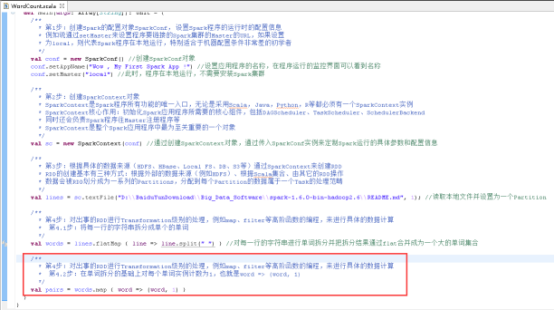
41、每个单词实例计数为1的基础之上统计每个单词在文件中出现的总次数,图里4.3步。
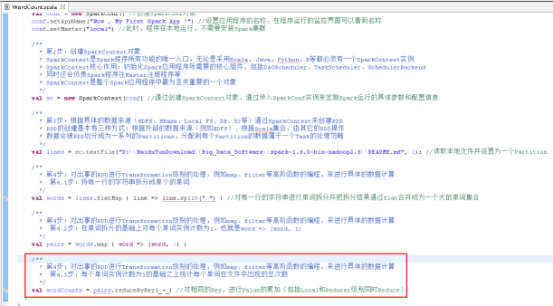
42、打印计算结果,图里的第5步。
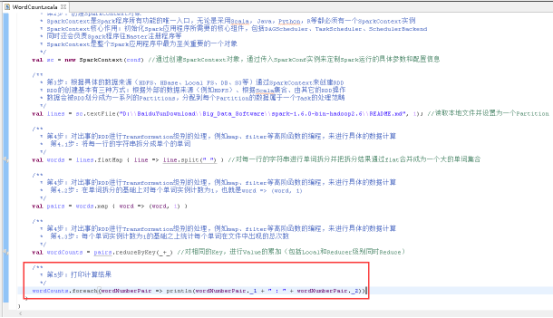
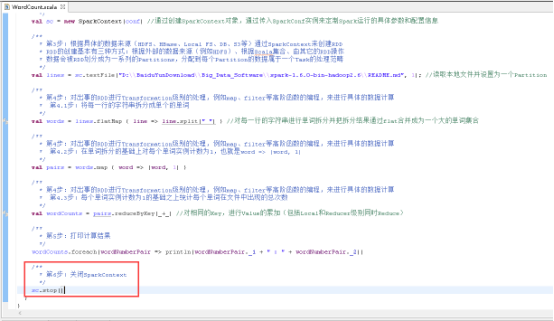
43、关闭SparkContext,图里的第6步。
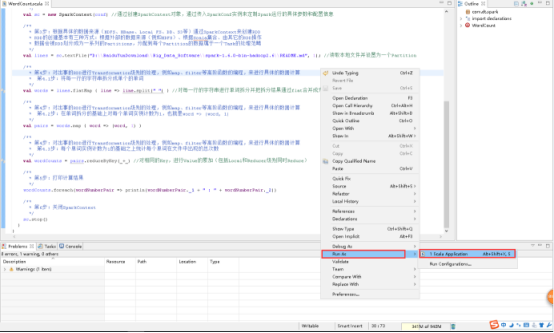
44、运行项目,右击WorkCount.scala文件 -> Run As -> Scala Application。
45、看见这样的结果,就代表成功了。
