版权声明:本文为IT晓白博主原创文章,转载请附上博文链接! https://blog.csdn.net/qq_38617531/article/details/84070652
1.创建maven工程
创建project--Java


创建module--maven
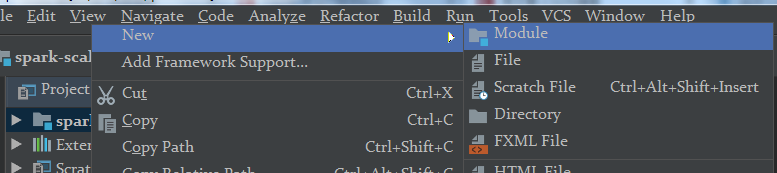
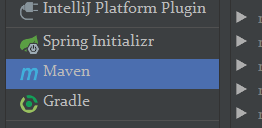
2.添加依赖
<dependencies>
<!--spark依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<!--scala依赖-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<!--Hadoop 依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>
3.添加scala支持


选择scala 2.11 版本
4.编写spark代码--测试WordCount
package com.sparkcore
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//第一步:创建sparkConf
val conf = new SparkConf()
//设置spark的运行模式:本地模式(用来测试),standalone(spark集群模式),yarn,Mesos,k8s
//通常情况下:用本地模式测试(开发环境),用yarn部署(生产环境)
//从spark2.3版本起支持k8s模式,未来spark程序大多会运行在k8s集群上
//本地模式:local[x];x=1,代表启动一个线程,
// X=2代表启动两个线程,x=* 代表启动跟所在机器cpu核数相等的线程数
//注意:不能使用local[1],原因:spark本地模式是通过多线程来模拟分布式运行
.setMaster("local[*]").setAppName("wordcount")
//第二步:创建sparkContext
val sc = new SparkContext(conf)
//第三步:通过sparkcontext读取数据,生成rdd
//4:尽可能与CPU核数对应
val rdd=sc.textFile("d:\\test\\01.txt",4)
//path:代表文件存储路径 minPartitions:最小分区数
//分区是spark进行并行计算的基础
println(rdd)
//第四步:把rdd作为一个集合,进行各种运算
rdd.map(line=>line.split(" ")).groupBy(x=>x)
.map(kv=>(kv._1,kv._2.size))
.collect().foreach(println)
}
}
总结:
Application: 利用sparkApi进行的计算
Submit:提交,把写好的spark应用提交给executor执行
Executor:就是运行spark任务的机器的代称
Jetty:web服务器(区别于tomcat,轻量级,可做嵌入式开发)
DAG:有向无环图
在计算机中图是一种数据结构:由边和顶点组成,其中边用来表示关系,顶点用来表示单位(数据)
在spark中用DAG来表示计算任务。
有向是为了表示计算任务是有步骤的,是有先后顺序的。
无环:用来表示任务不会反复执行,避免死循环
DAGScheduler:用来调度任务的一个线程
Stage:表示spark任务运行的一个阶段,spark任务可能有一个或多个stage. stage划分的标准是:shuffle(归并排序)
Task:一个分区的一个sparkAPI调用过程就是task
Shuffle:过程就是把相同的key放在同一个分区,就是算一个task。
Shuffle:形成宽依赖的过程叫shuffle:典型的如:group
,join,distinct。
窄依赖:子rdd的一个分区依赖与父rdd的一个分区;典型的操作有:map,flatMap,filter…
宽依赖:子rdd的一个分区依赖与父rdd的多个分区
Appilication(job)可能多个stage,一个stage可能多个task