深度学习——自学笔记1(Tensorflow)
-
tf.nn.softmax()
将logistic的预测二分类的概率的问题推广到了n分类的概率的问题。 -
tf.matmul()
tf.matmul(a,b,transpose_a=False,transpose_b=False,adjoint_a=False,
adjoint_b=False,a_is_sparse=False,b_is_sparse=False,name=None)
输入矩阵a,b的秩应大于1;transpose_a或transpose_b为真,则在乘法计算之前先进行转置;adjoint_a或adjoint_b为真,则乘法计算之前先进行共轭和转置;a_is_sparse或b_is_sparse为真,则被处理为稀疏矩阵。 -
tf.reduce_sum()
用于压缩求和。
x=[[1,2],[3,4]]
#tf.reduce_sum(x,axis,keepdims)
tf.reduce_sum(x) ==> 6
tf.reduce_sum(x,axis=0)==> [4,6]
tf.reduce_sum(x, axis=1) ==> [3, 7]
tf.reduce_sum(x, axis=1, keep_dims=True) ==> [[3], [7]]
tf.reduce_sum(x, axis=0, keep_dims=True) ==> [4,6]
- tf.train.AdamOptimizer()
tf.train.AdamOptimizer.__init__(learning_rate=0.001,beta1=0.9,bera2=0.999,epsilon=1e-08,use_locking=False,name=‘Adam’) - tf.nn.softmax_cross_entropy_with_logits()——交叉熵计算
(labels=None, logits=None, dim=-1, name=None)
labels的每一行都是一个概率分布;logits代表未缩放的对数概率;
dims: 类的维度,默认-1,也就是最后一维;name: 操作的名称;
返回值:长度为batch_size的一维Tensor。
logits与labels的形状必须相同,logits未经过缩放
交叉熵(cross entropy)的公式如下:
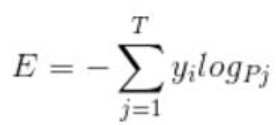
import tensorflow as tf
#分步计算交叉熵
labels=[[0.1,0.2,0.7],
[0.2,0.2,0.6]]
logits=[[1,2,7],
[2,5,6]]
logits_change=tf.nn.softmax(tf.cast(logits,dtype=tf.float32))
res1=-tf.reduce_sum(tf.log(logits_change)*labels,axis=1)
#综合计算交叉熵
res2=tf.nn.softmax_cross_entropy_with_logits_v2(labels=labels,
logits=tf.cast(logits,dtype=tf.float32))
#注意logits此处输入的是整数,因此需要转换类型
with tf.Session() as sess:
res3=sess.run(res1)
res4=sess.run(res2)
print('res3')
print('res4')
输出结果为:
==>[1.6091745 1.3265626]
==>[1.6091745 1.3265628]
-
tf.cast()
tf.cast(x,dtype,name=None)
将x数据格式转化成dtype(tf.int8; tf.float32 等)数据类型 -
tf.reduce_mean()
tf.reduce_mean(input_tensor,reduction_indices=None,
keepdims=False,name=None)
参数reduction_indices:表示在哪一维上求解
同理,tf.reduce_max()