在回顾深度学习相关知识的时候参考链接博客,将自己遗忘的知识点进行整理归纳。
- Train/Dev(验证集)/Test Sets
没有Test sets也是没有问题的。Test sets的目标主要是进行无偏估计。我们可以通过Train sets训练不同的算法模型,分别在Dev sets(测试不同算法的表现)上进行验证,根据结果选择最好的算法模型。这样也是可以的,不需要再进行无偏估计了。如果只有Train sets和Dev sets,通常也有人把这里的Dev sets称为Test sets。 - Bias(偏差)/Variance(方差)
当base error0时,假设Train set error为1%,Dev set error为11%,即该算法模型对训练样本的识别很好,但是对验证集的识别却不太好。这说明了该模型对训练样本可能存在过拟合,模型泛化能力不强,导致验证集识别率低。这恰恰是high variance的表现。假设Train set error为15%,而Dev set error为16%,虽然二者error接近,即该算法模型对训练样本和验证集的识别都不是太好。这说明了该模型对训练样本存在欠拟合。这恰恰是high bias的表现。模型既存在high bias也存在high variance,可以理解成某段区域是欠拟合的,某段区域是过拟合的。 - Basic Recipe for Machine Learning
减少high bias的方法通常是增加神经网络的隐藏层个数、神经元个数,训练时间延长,选择其它更复杂的NN模型等。在base error不高的情况下,一般都能通过这些方式有效降低和避免high bias,至少在训练集上表现良好。
减少high variance的方法通常是增加训练样本数据,进行正则化Regularization(有效途径),选择其他更复杂的NN模型等。
防止过拟合的有效途径
- Regularization
L1 regularization vs L2 regularization:
与L2 regularization相比,L1 regularization得到的w更加稀疏,即很多w为零值。其优点是节约存储空间,因为大部分w为0。然而,实际上L1 regularization在解决high variance方面比L2 regularization并不更具优势。而且,L1的在微分求导方面比较复杂。所以,一般L2 regularization更加常用。
更新w[l]时,比没有正则项的值要小一些,不断迭代更新,不断地减小,当lambd比较大时,w接近于0,某些神经元的部分功能下降。选择合适的lambd的值就可以同时避免high variance和high bias.
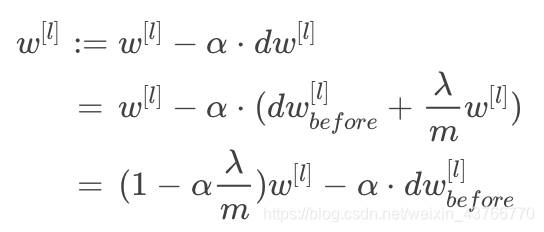
- Dropout Regularization
Dropout是指在深度学习网络的训练过程中,对于每层的神经元,按照一定的概率将其暂时从网络中丢弃。也就是说,每次训练时,每一层都有部分神经元不工作,起到简化复杂网络模型的效果,从而避免发生过拟合。
Dropout在电脑视觉CV领域应用比较广泛,因为输入层维度较大,而且没有足够多的样本数量。值得注意的是dropout是一种regularization技巧,用来防止过拟合的,最好只在需要regularization的时候使用dropout。 - 增加训练样本数量
- early stopping
Early stopping的做法通过减少得带训练次数来防止过拟合,这样J就不会足够小。L2 regularization可以实现“分而治之”的效果:迭代训练足够多,减小J,而且也能有效防止过拟合。而L2 regularization的缺点之一是最优的正则化参数λ
的选择比较复杂。对这一点来说,early stopping比较简单。总的来说,L2 regularization更加常用一些。
Normalization inputs
对训练样本进行归一化处理,提高训练的速度。
Vanishing and Exploding gradients
梯度消失和梯度爆炸。意思是当训练一个层数非常多的神经网络时,计算得到的梯度可能非常小或非常大,甚至是指数级别的减小或增大。这样会让训练过程变得非常困难。
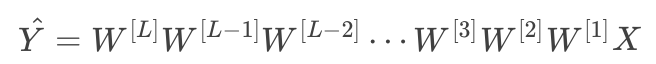
发生在指数稍大于1和稍小于1的情况下。
- 防止梯度爆炸和梯度消失
Weight Initialization for Deep Networks
为了让z不会过大或者过小,思路是让w与n有关,且n越大,w应该越小才好。这样能够保证z不会过大。一种方法是在初始化w时,令其方差为1/n.
如果激活函数是ReLU,权重w的初始化一般令其方差为2/n.
Gradient checking

参考博客
https://blog.csdn.net/red_stone1/article/details/78208851