ch2: 信息的表示和处理
信息的表示与处理
信息存储
字数据大小
机器的字长(word size) 决定指针的长度,也决定虚拟空间的最大大小.
常见的机器字长有32位和64位,程序以什么字长编译与机器字长无关,64位编译的程序只能在64位机器上运行,32位字长的机器既能在32位机器上运行,也能在64位机器上运行,这是一种向后兼容.
寻址和字节顺序
多字节的对象,在内存中有两种排列方法:大端法和小端法,他们的命名来自于将内存从低向高排列先遇到对象的高位还是低位
- 大端法: 低地址存放高位字节,高地址存放低位字节,字节的物理顺序与逻辑顺序相反 |
- 小端法: 低地址存放低位字节,高地址存放高位字节,字节的物理顺序与逻辑顺序相同 |
现在大多数机器都应用小端序,网络协议中常见大端序.可以通过将数据指针强制类型转换为char*指针来查看数据在内存中是以哪种顺序存储
C语言的位运算,逻辑运算
C语言的位运算: |(按位或),&(按位与),~(按位非)
C语言的移位运算: <<(左移,补零),>>(算数右移,补符号位)
对于无符号数,右移只能逻辑右移
对于有符号数,常用算数右移
C语言的逻辑运算: ||(或),&&(与),!(非)
整数表示
无符号数与补码
对于w位的无符号数,表示整数范围为0(w位全零)~2w-1(w位全一)
对于w位的有符号数补码,表示整数范围为-2w-1~2w-1-1
无符号数的二进制表示中,第i位权值为2i-1
有符号数补码的二进制表示中,第[0~w-1]位权值与无符号数相同,第w位的权值为 -2w-1
有符号数与无符号数之间的转换
对于一个整数,其有符号数与无符号数之间进行转换时,其二进制表示不变,仅仅是编译器对其理解方式发生变化.
因为无符号数和有符号数所表示的数值范围有重叠,在不重叠部分,考虑到其二进制表示,差别仅在于二进制表示最高位的权值的正负.因此对于w位二进制整数其转换遵循如下规律:
当整数数值介于0~2w-1-1之间时,即能用有符号补码表示,也能用无符号数表示,因此转换前后数值不变
当无符号整数数值介于2w-1~2w-1之间时,转换成有符号补码会发生溢出,考虑到二进制表示最高位的1的权值由正变负,其数值减小2w,变为负数
当有符号补码数值介于-2w-1~-1之间时,转换成无符号数,其数值增大2w,变为正数
转换的根本思路:对溢出的值加减2w(所能表示的最大范围),使数值最后落入可表示的范围
整数的位扩展与位截断
对于无符号数,其位扩展要在前边补零
对于有符号补码,其位扩展要在前边补充符号位
对于截断运算,相当于对数值取模之后再加减2w转换到相应的数值范围内
C语言的隐式类型转换
对于C语言,要注意将有符号数与无符号数进行运算时,有符号数会被隐式转换成为无符号数,这会引发一些BUG.在编程中,要注意避免这些类型转换.
int sum_elements(float a[], unsigned length) {
float result = 0;
for(int i=0; i<=length-1; i++) {
sum += a[i];
}
return result;
}
当输入length为0时,length-1=-1,会被转换成为一个很大的正数,产生bug.
整数运算
整数运算的本质是取模运算,将溢出的截断舍弃,在数值上表现为取模.
对于算术运算(加减乘除),编译器不关心数据是被解释成有符号数还是无符号数,对于两种表示方式,其二进制操作是相同的
整数加法
对于w位无符号数加法,将高位溢出部分舍弃,取低w位.
有符号数的加法与无符号数的二进制表现是相同的,分为正溢出和负溢出,分别加减2w取值.
判断无符号数是否溢出的标准:若加法运算结果s小于被加数x,y中任意一个,则发生溢出,否则不发生溢出.
判断有符号数是否溢出的标准:若两个负数相加得到正数,则发生负溢出;若两个正数相加得到负数,则发生负溢出;其他情况下不发生溢出.
加法运算满足阿贝尔群,亦即满足交换律和结合律,例如:不论运算过程中是否发生溢出,(x+y)-x==y永远成立
整数乘法
与加法相类似,乘法运算若发生溢出,也是将高位溢出部分舍弃,取低w位.
对于w位无符号数乘法运算,x*y运算的结果是 x*y mod 2w,相当于数值运算后进行取模运算.
对于有符号数的乘法运算,鉴于其与无符号数乘法运算的位级等价性,可以将其转化为无符号数相乘来考虑.
乘法运算不满足阿贝尔群,不满足交换律和结合律,例如:考虑到发生溢出的情况,(x*y)/x==y不恒成立
补码取非
对于除Tmin之外的任意整数x取反得到-x,
Tmin取反仍为Tmin本身
Tmin的这个性质常作为bug测试的一种考虑的情况
乘以常数
乘法运算在编译时常被优化成多个移位运算的和或差,根据优化成移位运算的和或差,有两种不同形式,下面以x*14为例
- 形式A(分解成和): x*14=(x<<3)+(x<<2)+(x<<1)
- 形式B(分解成差): x*14=(x<<4)-(x<<1)
若乘数二进制表示中相连1的个数小于等于2个,形式A较快,若相连1的个数大于2个,形式B较快
除以2的幂
乘以任意乘数的乘法运算都能被优化成移位运算,但对于除法,只有当除数是2的幂时,才会被优化成移位运算
-
无符号数x除以2的k次幂,相当于将x逻辑右移k位(无符号数的右移只有逻辑右移).除法运算的结果向负无穷取整.
-
有符号数x除以2的k次幂,需要对x进行算数右移.但若直接进行算数右移,则不论x的正负,运算结果都是向负无穷取整的.因此,除法操作应分解成这样:
x/2k= (x>0 ? x : x+(1<<k)-1 )>>k- 若x是正数,直接算数右移k位
- 若x是负数,要将x加上 2k-1 的偏移量(bias)再算数右移k位
这样可以保证除法运算结果永远向零取整
浮点数
IEEE浮点表示
IEEE浮点标准用 V=(-1)s*M*2E 来表示一个浮点数:
- 符号位s
- 尾数M: 尾数M是一个二进制小数,范围是[0,1)(非规格化)或[1,2)(规格化)
- 阶码E: 对浮点数加权
浮点数在内存中的存储方式为从高到低依次存储符号位s,exp,frac,其中
- exp编码阶码E
- frac编码尾数M
浮点数有两种精度的规格,其尾数和阶码的位数不同
根据exp的形式,被编码的值可以表现出3种不同的情况:
- 规格化的值(exp
不全为1且不全为0): 最普遍的情况- 阶码
E=exp-bias, exp编码一个无符号数,偏移量bias=2k-1 - 尾数
M=1.f,f为尾数的小数部分,M的范围为[1,2). 我们默认尾数的整数部分为1,这样我们省下了一个精度位.
- 阶码
- 非规格化的值(exp
全为0): 用来表示0和接近0的数- 阶码
E=1-bias.
尾数取1-bias而非-bias是为了使非规格化数平稳过渡到规格化数(规格化数的最小阶码为1-bias) - 尾数M=
1.f,M的范围为[0,1).
- 阶码
- 特殊值(exp
全为1):- exp
全为1且frac全为0: 表示无穷INF,用来表示溢出的结果 - exp
全为1且frac不全为0: 表示NaN,用来表示不存在的数
- exp
数字示例
对于位数较少的浮点数,其三种情况下的浮点值取值如下,我们可以看到:
越接近0,浮点数分布越密
非规格化的值全部分布在0附近,且非规格化的值全部小于规格化的值

下面我们考虑8位浮点数特殊值的编码:
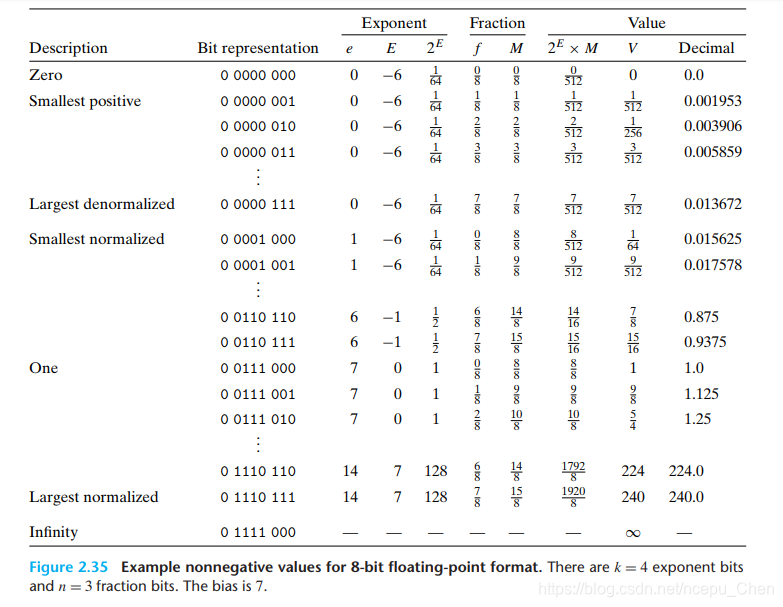
观察上表可以发现:
0有两种表示方式: +0和-0.
最大的非正规数与最小的正规数的取值之间是平稳过渡的.
浮点数的值大小随着其二进制值大小的增加而增加,这是因为浮点数在内存中存储时阶码存储在尾数之前.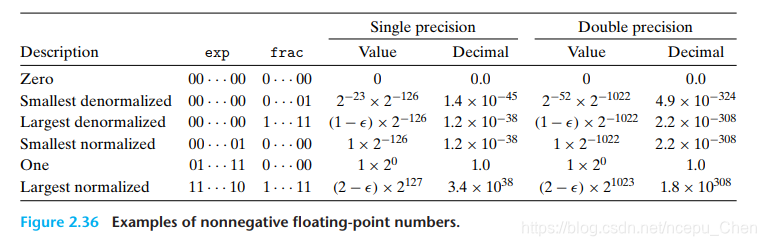
浮点数的舍入
IEEE浮点数的舍入遵循向偶数舍入的原则
浮点运算
浮点数的运算要经历舍入过程
- 浮点数的加法与乘法均:
- 满足交换律:
10E-10+10E10=10E10+10E-1010E-10*10E10=10E10*10E-10
- 不满足结合律
10E-10+10E10+3!=10E-10+(10E10+3)10E20*10E20*10E-20!=10E20*10E-20*10E20
- 满足交换律: