一、信息存储
机器级程序将存储器视为一个非常大的字节数组,称为虚拟内存。内存的每个字节由一个唯一的数字表示,称为它的地址,所有可能地址的集合称为虚拟地址空间。顾名思义,这个虚拟地址空间只是展现给机器级程序的概念性影像,实际的实现是将动态随机访问存储器、闪存、磁盘、特殊硬件和操作系统结合起来,为程序提供一个看上去统一的字节数组。
【注】 C语言中一个指针的值(无论它指向一个整数、一个结构体或是某个其他程序对象)都是某个存储快的第一个字节的虚拟地址。
1.1 十六进制表示法

Java将十进制转成二进制、八进制和十六进制的方法,也可以自己实现:
public class Main {
public static void main(String[] args) {
int n = 18;
Integer.toHexString(n);
System.out.println(n + "的二进制是:" + Integer.toBinaryString(n));
System.out.println(n + "的八进制是:" + Integer.toOctalString(n));
System.out.println(n + "的十六进制是:" + Integer.toHexString(n));
System.out.println(n + "的三进制是:" + Integer.toString(n, 3));
}
}
C++将一个整数字符串转成十六进制的方法:
string string_to_hex(const string& str) {
//transfer string to hex-string
string result="0x";
string tmp;
stringstream ss;
for(int i=0;i<str.size();i++) {
ss<<hex<<int(str[i])<<endl;
ss>>tmp;
result+=tmp;
}
return result;
}
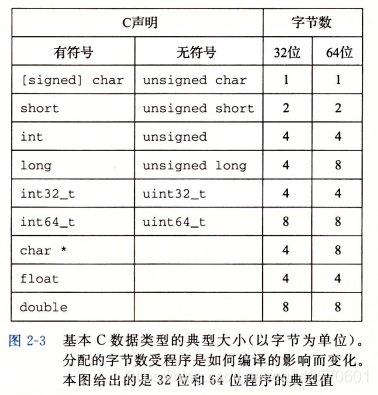
1.2 字数据大小
首先明白两个概念,字和字长:
- 字:计算机在进行数据处理,一次存取、加工、传送的数据长度称为字(word)。一个字一般由多个(整数倍)字节构成。
- 字长:计算机的每个字包含的位数称为字长,如字长为
32位或64位的计算机。
每台计算机都有一个字长,字长决定的最重要的系统参数就是虚拟地址空间的最大大小,如32位字长的机器限制虚拟地址空间为4GB,64位字长的机器限制虚拟地址空间为16EB。
【注】 C的数据类型char表示一个单独的字节,尽管被大家所熟知的是char用来存放文本串中的单个字符,但是它也能存储整数值。
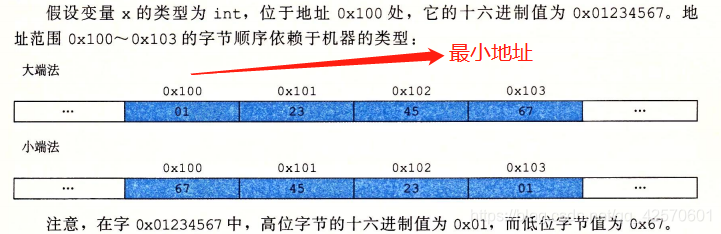
1.3 寻址和字节顺序
对于跨越多字节的程序对象,我们必须建立两个规则:
- 1)对象的地址是什么?(最小地址)
- 2)如何排列这些字节?(大端法、小端法)
最小地址:在几乎所有的机器上,多字节对象都被存储为连续的字节序列,对象的地址为所使用的字节中的最小的地址。
大端法和小端法:
- 在内存中按照从最高有效字节到最低有效字节的顺序存储对象,最高有效字节在前面,称为大端法。
- 在内存中按照从最低有效字节到最高有效字节的顺序存储对象,最低有效字节在前面,称为小端法。
如何判断自己计算机字节序列的存储方式是大段还是小端?
int i = 0x12345678;
if (*((char*)&i) == 0x12)
cout << "大端" << endl;
else
cout << "小端" << endl;
1.4 表示字符串
C语言中字符串被编码为一个以null(其值为0)字符结尾的字符数组,每个字符都有某个标准编码(C是ASCII)来表示,如:字符串"12345"对应的字节数组是:31 32 33 34 35 00。注意自己实现字符串转字节数组在跨平台或语言之间传送时,最后要补一个'\0'。
在使用相同字符标准编码作为字符码的任何系统都会表示相同的结果,与字节顺序和字大小规则无关。因而,文本数据比二进制数据具有更强的平台独立性。
utf-8表示将每个字符编码为一个字节序列,这样ASCII还是使用和它们在ASCII中一样的单字节编码为一个字节序列,所以ASCII字节序列用ASCII码和用utf-8码表示是一样的。
Java使用Unicode 来表示字符串,对于C语言也有支持Unicode的程序库
1.5 表示代码
同样的代码在不同的机器上会被编译成不同的二进制机器指令。

1.6 布尔代数简介
布尔值之间的4中运算(与、或、异或、非)可以拓展于位向量的运算,位向量就是固定长度为w、有0和1组成的串。位向量很有用的应用就是表示有限集合。

1.7 C语言中的位级运算
1.8 C语言中的逻辑运算
逻辑运算认为,所有非零的参数都表示true,参数0表示false。
1.9 C语言中的移位运算

左移:向左移动k位,丢弃最高的k位,并在右端补k个0
右移:分为逻辑右移和算术右移
- 逻辑右移:往左边补k个0(Java中是
>>>) - 算术右移:往左边补k个最高有效位的值,0补0,1补1(Java中是
>>)
大多数编译器或机器组合都对有符号数使用算术右移,对于无符号数右移必须是逻辑右移。为什么呢?

二、整数表示
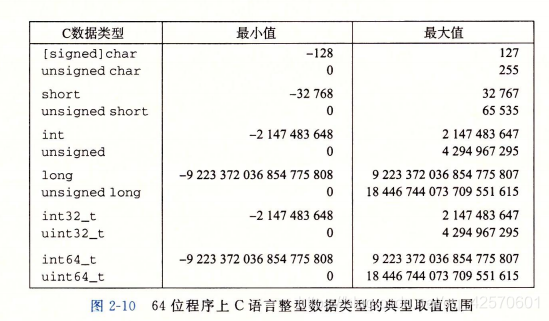
2.1 整型数据类型
C语言整型数据类型可以用关键字来指定大小,如:char、short、long或者long long,不同大小分配的字节数会根据机器的字长和编译器有所不同。根据字节分配,不同的大小所能表示的值的范围是不同的。注意下图中负数的范围比整数的范围大1:
2.2 无符号数的编码
无符号的二进制表示有一个很重要的属性,就是每个介于0~2^(w-1)之间的数都有唯一一个w位的编码值。这在数学函数中叫双射。

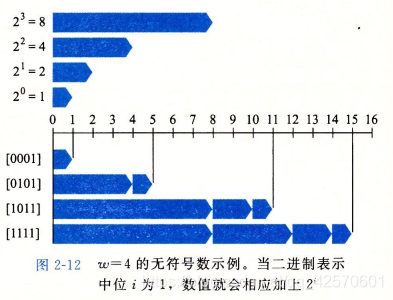
2.3 补码编码
最常见的有符号数的计算机表示方式就是补码形式,在这个定义中,将字的最高有效位解释为负权,每个介于-2^(w-1)和2^(w-1)之间的整数都有一个唯一长度为w的位向量二进制表示。补码也具有双射。

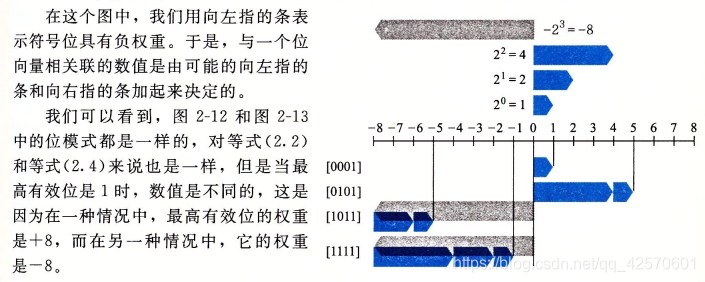
有符号数为什么要用补码表示?因为原码存储数据有两个问题:
- 0有两种表示方式:
-0:1000 0000和+0:0000 0000 - 减法运算结果不正确(计算机只会计算加法,不会计算减法)
使用补码就可以避免这两个问题,负数的补码 = 反码 + 1
2.4 有符号数和无符号数之间的转换
对于大多数C语言的实现,有符号与无符号之间的转换是位级角度,而不是数值角度。也就是说数值可能会变,但位模式不变。
short int a = -12345;
unsigned short b = (unsigned short)a;
cout << a << " is bit:\n" << bitset<16>(a) << endl;
cout << b << " is bit:\n" << bitset<16>(b) << endl;
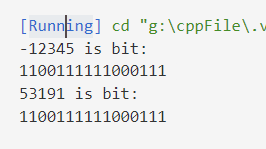
从上面代码的输出结果可以看出,有符号变量a和无符号变量b的位模式一样,转换过程只是让计算机把a的最高有效位的符号位当做b的数值位来处理。
2.5 C语言中的有符号数和无符号数
C语言默认为有符号,如果需要无符号末尾+U,例:12345U
C语言支持所有整型数据类型的有符号和无符号运算
C语言标注没有指定有符号数要采用某种表示,但是几乎所有的机器都使用补码
C语言允许无符号数和有符号数之间的转换.转换的原则是底层的位表示保持不变
2.6 扩展一个数字的位表示
下面两种扩展方式可以分别对比逻辑右移、算术右移
- 对于一个无符号数转为更大的数据类型,只需要简单地在表示的开头添加
0,这种运算称为零扩展 - 对于有符号的数,即补码,进行符号扩展(sign extension),就是添加最高有效位的值
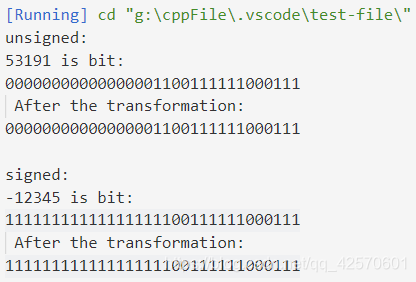
short a = -12345;
unsigned short b = (unsigned short)a;
cout<< "unsigned:"<<endl;
cout << b << " is bit:\n" << bitset<32>(b) << endl;
cout << " After the transformation:\n" << bitset<32>((unsigned short)b) << endl;
cout<< "\nsigned:"<<endl;
cout << a << " is bit:\n" << bitset<32>(a) << endl;
cout << " After the transformation:\n" << bitset<32>((int)a) << endl;
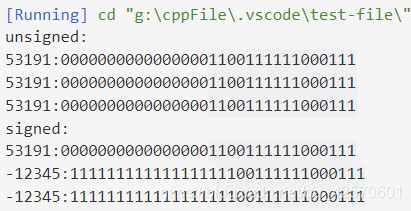
2.7 截断数字
截断一个数到k位,即舍去w-k的高位。
- 对于无符号数:截断x它到k位的结果相当于
B2U([Xk-1,Xk-2,….x0])=B2U([Xw-1,Xw-2…x0]) mod 2^k - 对于有符号的数x:截断的时候还是当做无符号的数看
B2T([Xk-1,Xk-2,….x0])=U2T(B2U([Xw-1,Xw-2…x0]) mod 2^k)
cout<<"unsigned:"<<endl;
unsigned int ua = 53191;
cout << ua << ":" << bitset<32>(ua) << endl;
unsigned short usa = (unsigned short)ua;
cout << usa << ":"<< bitset<32>(usa) << endl;
unsigned int uaa = usa;
cout << uaa << ":" << bitset<32>(uaa) << endl;
cout<<"signed:"<<endl;
int a = 53191;
cout << a << ":" << bitset<32>(a) << endl;
short sa = (short)a;
cout << sa << ":"<< bitset<32>(sa) << endl;
int aa = sa;
cout << aa << ":" << bitset<32>(aa) << endl;
三、整数运算
3.1 无符号加法
记x+y是两个数的和,2^w是最高权重,则和模就是(x+y) mod 2^w,所以有效的无符号整数运算应该符合这个等式:x+y = (x+y) mod 2^w。如果数据溢出,则采用高位舍去的方式舍去高位(有效位之外的位)。

当无符号加法数据数据溢出时,该如何判断?如果x,y的和数据溢出,则和模(x+y) mod 2^w比x,y中的任何一个值都小。

3.2 补码加法
补码加法不等同于无符号加法的地方在于,补码加法既有正溢出,也有负溢出。

补码加法溢出的检测原理:两个正数相加可能会产生正溢出,正溢出结果会变为负数;两个负数相加可能会产生负溢出,负溢出结果会变为正数。所以利用好符号位,就可以判断值是否溢出。
3.3 补码的非
模型加法形成的一种数学结构,称为阿贝尔群。补码的加法逆元,即是补码的非。

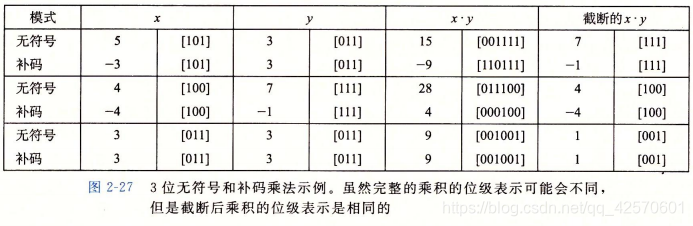
3.4 无符号乘法
对于无符号和补码乘法,乘法运算的位级表示都是一样的,是同一条指令。结果只取低w位表示的值,其余截断。

3.5 补码乘法
无符号和补码相乘出来的两个数的低W位 永远相等。

3.6 乘以常数
以往的整数乘法指令相当慢,一般需要10个或者更多的时钟周期,Core i7整数乘法也需要3个时钟周期。所以,会用移位和加法运算或减法运算的组合代替乘以常数因子的乘法。

对上面原理的梳理,以11 * 4为例,11 * 4 = 11 * 2^2 = (11<<2),以此基础理解x * 14,14 = 2^3 + 2^2 +2^1 = 2^4 - 2^1,所以 x * 14 = (x<<3) + (x<<2) + (2<<1) = (x<<4) - (x<<1)。
最后需要注意的一点是,执行固定字长的乘法,左移一个数值等价于执行一个与2的幂相乘的无符号乘法,同时固定字长的左移存在数据溢出的可能。
3.7 除以2的幂数
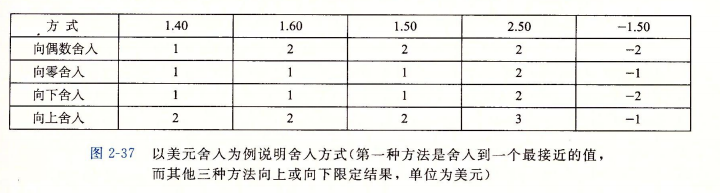
整数除法比乘法更慢,一般需要30个或者更多的时钟周期,利用右移的方式来实现整数和无符号数的除法。右移的结果又分为向下舍入和向上舍入,两者表达式区别在于x的值是否为非负数(x >= 0 ? x : (x + (1<<k)-1))>>k。

向下舍入:当x >= 0时,x/2^k = x>>k,如图 2-29。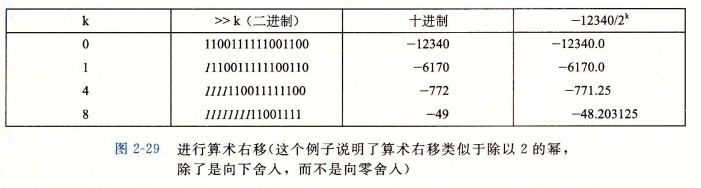
向上舍入(向零舍入):当x < 0时,x/2^k = (x + (1<<k)-1)>>k,偏量(1<<k)-1会让右移之后的值可能加1,如图 2-30。

四、浮点数
4.1 二进制小数
十进制小数中,小数点左边的数字的权为10的正数幂,是整数值,小数点右边的数字的权是10的负数幂,得到是小数值,如下图中的12.34。
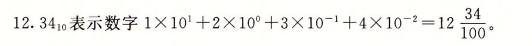
类似,考虑将十进制数换成二进制数,小数点左边的数字的权为2的正数幂,小数点右边的数字的权是2的负数幂,如下图中的二进制数101.11。由此可以知道,小数的二进制表示法只能表示那些能够被写成x * 2^y的数,其他的数值只能近似的表示。

4.2 IEEE浮点表示
IEEE的浮点格式,单精度浮点格式的三个字段分别是:1,8,23,双精度浮点格式的三个字段分别是:1,11,52。


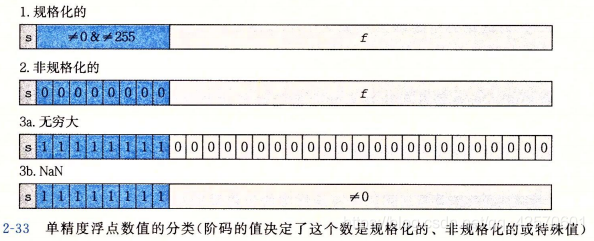
给定位表示,根据阶码字段exp的值,被编码的值可以分成三种不同的情况:规格化的,非规格化的,无穷大或NaN。需要注意的是,阶码值E、阶码字段e、小数字段f、尾数M这四个概念不能搞混。
- 规格化的值:阶码字段不全为
0,也不全为1。此时阶码值被解释为以偏置形式表示的有符号整数,也就是说,阶码值E = e - Bias,其中e是阶码字段exp,为无符号数,Bias是一个等于2^(k-1) - 1的偏置值。小数字段frac被解释为描述小数值f,其中0 <= f < 1,则尾数定义为M = 1 + f;且1 <= M < 2,这种方式也可以叫做隐含的以1开头的表示,因为M总是等于“一点几”,而由于前面总是等于1,所以我们也就不用显式表示它。 - 非规格化的值:当阶码全为
0的时候所表示的数,此时阶码值E = 1 - Bias,尾数值M = f,可以补偿非规格化值的位数没有隐含开头的1,有两个用途:
a. 由于规格化的值M>=1恒成立,所以不能表示0。非规格化的值,当符号位、阶码、小数域全为0时表示+0.0,符号位为1其他域为0表示-0.0,IEEE的浮点格式+0.0和-0.0在某些时候认为是不同的。
b. 另一个用途是表示那些非常接近0.0的数。 - 特殊值:当阶码全为1的时候会出现。小数域全为
0表示无穷(正负由符号位s决定),小数位为非零,结果值成为NaN(Not a Number),如“根号下的负一”。
4.3 数字示例
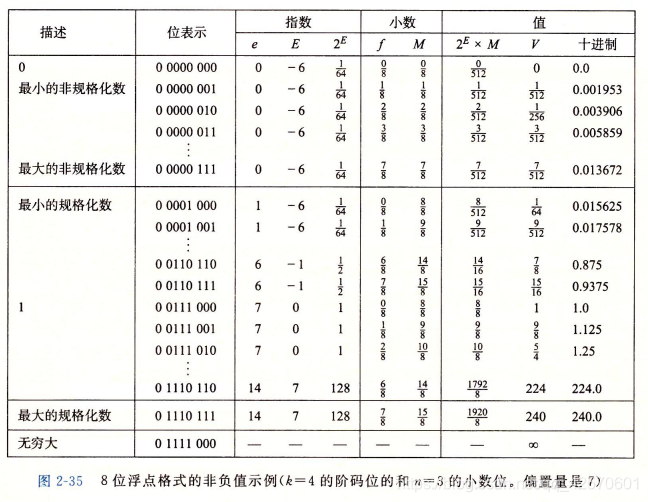
由IEEE浮点标准公式可知V = (-1)^s * M * 2^E,其中:
- 规格化的值:阶码值
E = e - Bias,e为k位阶码字段位模式表示的无符号值,Bias = 2^(k-1) - 1为偏置值,而M = 1 + f为为位数值。 - 非规格化的值:阶码值
E = 1 - Bias,Bias = 2^(k-1) - 1为偏置值,M = f为位数值。
如下图中的8位浮点格式示例中,有k = 4的阶码位和n = 3的小数位,所以偏置值Bias = 2^(4-1) - 1 = 7。如果将下面的位表示当做无符号整数,同浮点数一样,也是升序,所以可以使用整数函数来对浮点数进行排序。
下图是一些重要的单精度和双精度浮点数的表示和数字值:

如何把一个整数值转成浮点形式存储:

4.4 舍入
由于表示方法限制了浮点数的表示范围和精度,所以浮点只能近似的表示实数运算,而完成这个任务的运算方式就是舍入。