scrapy中如何反爬虫呢?
反爬虫策略:
策略一:设置download_delay
-
作用:设置下载的等待时间,大规模集中的访问对服务器的影响最大,相当与短时间中增大服务器负载。
-
缺点: 下载等待时间长,不能满足段时间大规模抓取的要求,太短则大大增加了被ban的几率
策略二:禁止cookies
- Cookie,有时也用其复数形式 Cookies,指某些网站为了辨别用户身份、进行 session 跟踪而储存在用户本地终端上的数据(通常经过加密)。
- 作用: 禁止cookies也就防止了可能使用cookies识别爬虫轨迹的网站得逞。
- 实现: COOKIES_ENABLES=False
策略三:使用user agent池(拓展: 用户代理中间件)
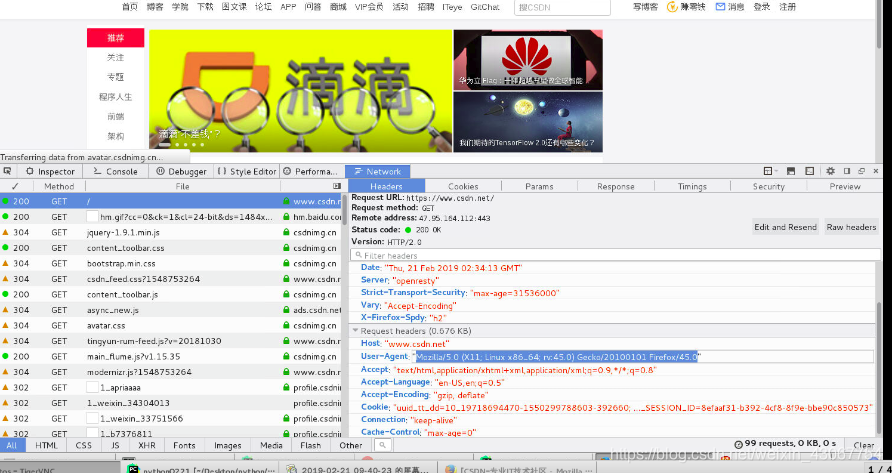
- 为什么使用? scrapy本身是使用Scrapy/0.22.2来表明自己身份的。这也就暴露了自己是爬虫的信息。
- user agent,是指包含浏览器信息、操作系统信息等的一个字符串,也称之为一种特殊的网络协议。服务
器通过它判断当前访问对象是浏览器、邮件客户端还是网络爬虫。
策略四:使用代理IP中间件
web server应对爬虫的策略之一就是直接将你的IP或者是整个IP段都封掉禁止访问,
这时候,当IP封掉后,转换到其他的IP继续访问即可。
策略五: 分布式爬虫Scrapy+Redis+MySQL # 多进程
Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。
它利用Redis对用于爬取的请求(Requests)进行存储和调度(Schedule),
并对爬取产生rapy一些比较关键的代码,将scrapy变成一个可以在多个主
机上同时运行的分布式爬虫。
继续上一篇博客的代码:
网页自带一些禁止访问爬虫权限如何解决

每个网页都有robots.txt这里存放的禁止访问的内容:以csdn为例

settings.py: ROBOTSTXT_OBEY = False
# https://blog.csdn.net/robots.txtc存储了网站爬取的权限
ROBOTSTXT_OBEY = False # 把这个ture改为false我们就可以不遵守这个规则
1. 设置DOWNLOAD_DELAY = 3,
设置下载的等待时间;每下载一个页面, 等待xxx秒。

2. 禁止cookie信息;
# Disable cookies (enabled by default)
COOKIES_ENABLED = False

3.设置用户代理
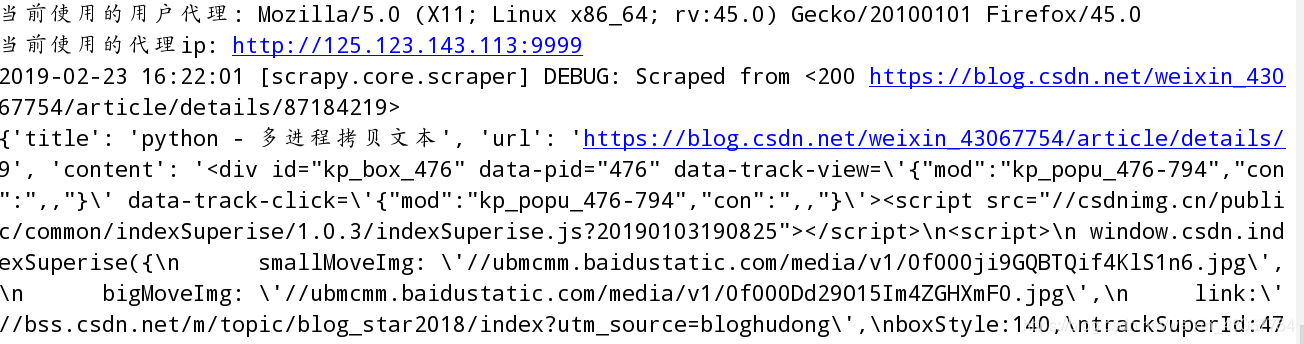
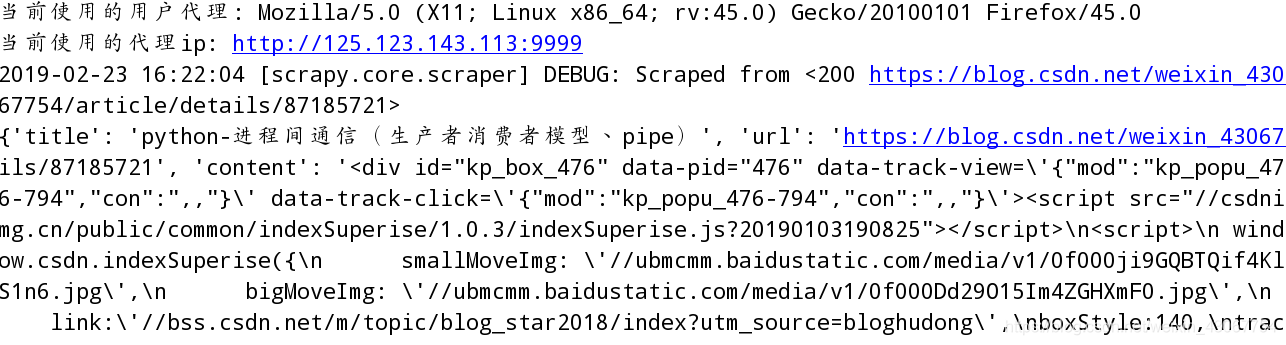
USER_AGENT = ‘Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0’

4. 设置User-Agent的中间键
middlewares.py中添加useragentmiddleware模块
class UserAgentMiddleware(object):
def __init__(self):
self.user_agent =[
'Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0',
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
]
def process_request(self,request,spider):
ua = random.choice(self.user_agent)
if ua:
request.headers.setdefault('User-Agent',ua)
settings.py文件中配置

执行一下
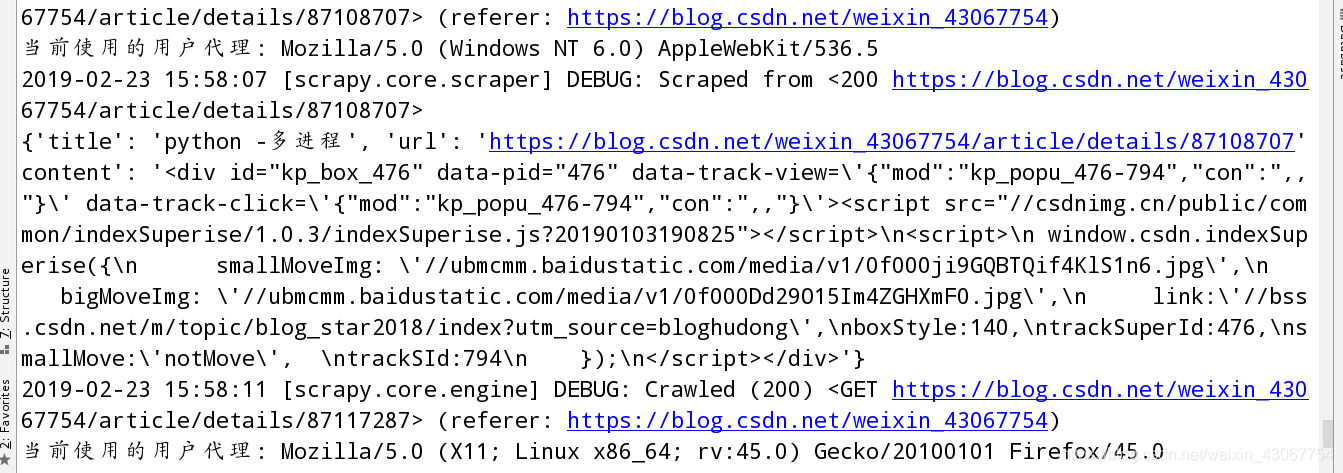
5. 设置代理IP的中间键
middlewares.py中添加Proxiesmiddleware模块
class ProxiesMiddleware(object):
# 留下练习:
# - 1). 从西刺代理IP网站获取所有的代理IP并存储到mysql/redis;
def __init__(self):
# 2). 连接redis/mysql数据库;
self.proxies = [
'http://116.209.54.221:9999',
"https://111.177.183.212:9999"
]
def process_request(self, request, spider):
"""当发起请求"""
# 3). 从数据库里面随即获取一个代理IP;
proxy = random.choice(self.proxies)
if proxy:
# 此行仅为了测试, 真实场景不要打印, 会影响爬虫的效率
# print("当前使用的代理IP: %s" %(proxy))
request.meta['proxy'] = proxy
# def process_response(self, response, spider):
# """当响应的时候自动执行的函数......"""
# pass
# def process_exception(self, request, exception, spider):
# if exception:
# # 4). 如果产生异常, 则删除数据库里面对应的数据;
# print("代理异常")
# return request
执行时代理ip和用户代理交替进行是反爬虫的有效手段