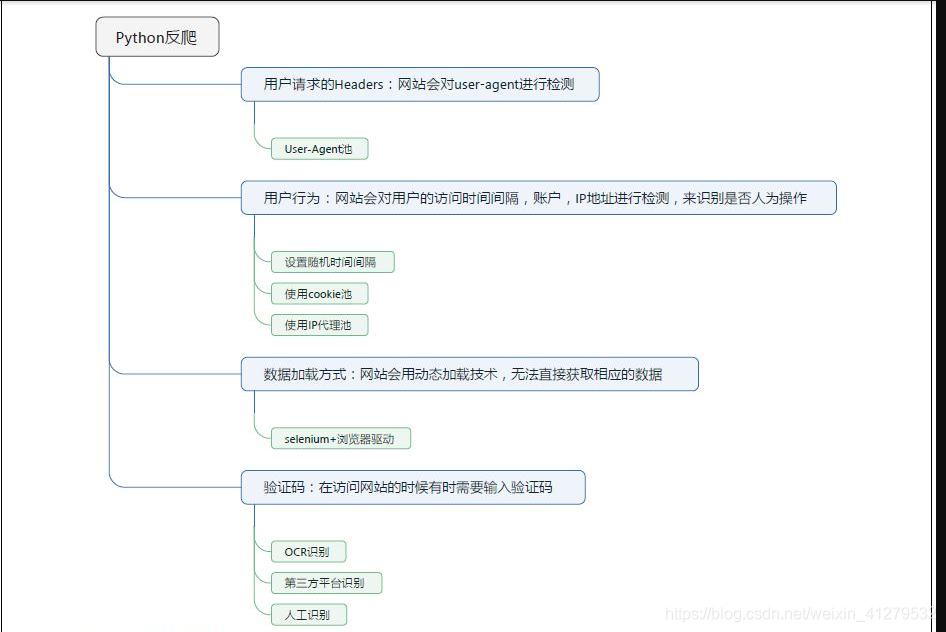
-
添加请求头User-Agent:
如果不添加请求头,网站会认为不是用浏览器操作,会进行反爬虫,添加请求头,网站会识别你是用哪个浏览器,不同的浏览器User-Agent不同 -
修改访问频率:
大多数情况下,我们遇到的是访问频率限制。如果你访问太快了,网站就会认为你不是一个人。这种情况下需要设定好频率的阈值,否则有可能误伤。
遇到这种网页,最直接的办法是限制访问时间
需要你限制不定的时间,不能用一个准确的时间 -
代理IP
如果对页的爬虫的效率有要求,那就不能通过设定访问时间间隔的方法来绕过频率检查了。
代理IP访问可以解决这个问题。如果用100个代理IP访问100个页面,可以给网站造成一种有100个人,每个人访问了1页的错觉。这样自然而然就不会限制你的访问了。
但是代理IP也很不稳定,需要时刻检验你的IP是否能用
- 分布式爬虫
分布式爬虫会部署在多台服务器上,每个服务器上的爬虫统一从一个地方拿网址。这样平均下来每个服务器访问网站的频率也就降低了。由于服务器是掌握在我们手上的,因此实现的爬虫会更加的稳定和高效。这也是我们这个课程最后要实现的目标。