scrapy爬虫与反爬虫
更多文章欢迎访问个人博客 www.herobin.top
爬虫和反爬虫
- 爬虫:自动获取网站数据的程序,关键是批量的获取
- 反爬虫:使用技术手段防止爬虫程序的方法
- 误伤:反爬技术将普通用户识别为爬虫,如果误伤过高,效果再好也不能用
- 成本:反爬虫需要的人力和机器成本
- 拦截:成功拦截爬虫,一般拦截率越高,误伤率越高
反爬虫的目的
- 初级爬虫:简单粗暴,不管服务器压力,容易弄挂网站
- 数据保护
- 失控的爬虫:由于某些情况下,忘记或者无法关闭的爬虫
- 商业竞争对手
爬虫和反爬虫对抗过程
爬虫和网站攻坚过程
- 爬虫:分析网络请求,用scrapy写爬虫爬取数据
- 网站:监控发现某个时间段访问陡增,ip相同,useragent都是python,直接限制访问(不能封ip)
- 爬虫:User-agent模拟firefox,获取ip代理
- 网站:发现ip变化,直接要求登录才能访问
- 爬虫:注册账号,每次请求带cookie或者token
- 网站:健全账号体系,即A只能访问好友的信息
- 爬虫:注册多个账号,多个账号联合爬取
- 网站:请求过于频繁,进一步加剧ip访问频率限制
- 爬虫:模仿人请求,限制请求速度
- 网站:弹出验证码,让识别验证码
- 爬虫:通过各种手段识别验证码
- 网站:1.增加动态网站,数据通过js动态加载,增加网络分析复杂
2.发现大量请求只请求html,不请求image和css以及js- 爬虫:通过selenium和phantomjs完全模拟浏览器操作
- 网站:成本太高,放弃…
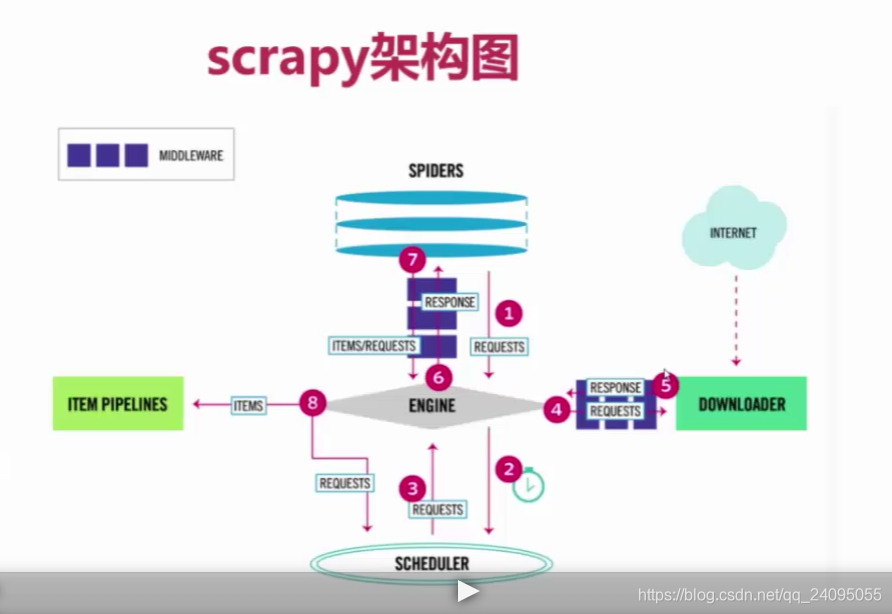
随机调用User-agent
settings.py
user_agent_list = [
"","",....
]
zhihu.py
from settings import user_agent_list
import random
random_index = random.randint(0, len(user_agent_list)-1)
random_agent = user_agent_list[random_index]
headers = {
"User-agent": random_agent,
...
}
然而这样代码冗余了
从上面流程图可以看到每次访问(4)都会请求MiddleWare,可以在settings中将DOWNLOADER_MIDDLEWARES的注释放开,在里面配置自己的Middleware
我们自定义的middleware写在自动生成的middlewares.py中
更简单的方法,使用插件fake-useragent
from fake_useragent import UserAgent
ua = UserAgent()
ua.ie
ua.firefox #而且每次都是不一样的随机的版本
ua.random #不同浏览器不同版本随机切换
settings:
from fake_useragent import UserAgent
DOWNLOADER_MIDDLEWARES = {
'ArticleSpider.middlewares.ArticlespiderDownloaderMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
可以设置RANDOM_UA_TYPE来制定浏览器或者random
RANDOM_UA_TYPE = "random"
middleware:
class RandomUserAgentMiddleware(object):
#随机更换user-agent
def __init__(self, crawler):
super(RandomUserAgentMiddleware, self).__init__()
# self.user_agent_list = crawler.settings.get("user_agent_list",[])
self.ua = UserAgent()
self.ua_type = crawler.settings.get("RANDOM_UA_TYPE", "random")
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_request(self, request, spider):
# request.headers.setdefault("User-Agent", self.ua.random)
def get_ua():
return getattr(self.ua, self.ua_type)
request.headers.setdefault("User-Agent", get_ua())
用代理ip速度会比较慢,可以用自己的ip注意限速爬取
ip代理 可以用西刺http://www.xicidaili.com/
也是加在上面的process_request中
request.meta["proxy"] = "http://122.114.31.177:808"
但是一个ip是不够的 我们要设置一个ip代理池 随机获取使用
这里可以通过爬取西刺这个网站 获取到代理ip的信息使用
用脚本的方式写这个爬虫,如下:
import requests
from scrapy.selector import Selector
import MySQLdb
conn = MySQLdb.connect(host="127.0.0.1", user="root", passwd="1234", db="article", charset="utf8")
cursor = conn.cursor()
def crawl_ips():
#爬取西刺的免费ip代理
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"}
for i in range(10):
re = requests.get("http://www.xicidaili.com/nn/{0}".format(i), headers=headers)
selector = Selector(text=re.text)
all_trs = selector.css("#ip_list tr")
ip_list = []
for tr in all_trs[1:]:
speed_str = tr.css(".bar::attr(title)").extract()[0]
if speed_str:
speed = float(speed_str.split("秒")[0])
all_texts = tr.css("td::text").extract()
ip = all_texts[0]
port = all_texts[1]
proxy_type = all_texts[5]
ip_list.append((ip, port, proxy_type, speed))
print(all_texts)
for ip_info in ip_list:
cursor.execute(
"insert into proxy_ip(ip, port, speed, proxy_type) VALUES ('{0}', '{1}', '{2}', 'HTTP')".format(
ip_info[0], ip_info[1], ip_info[3]
)
)
conn.commit()
class GetIP(object):
def delete_ip(self, ip):
#从数据库中删除无效的ip
delete_sql = "delete from proxy_ip where ip='{0}'".format(ip)
cursor.execute(delete_sql)
conn.commit()
return True
def judge_ip(self, ip, port):
#判断ip是否可用
http_url = "http://www.baidu.com"
proxy_url = "http://{0}:{1}".format(ip, port)
try:
proxy_dict = {
"http":proxy_url
}
response = requests.get(http_url,proxies=proxy_dict)
except Exception as e:
print("invalid ip and port")
self.delete_ip(ip)
return False
else:
code = response.status_code
if code >= 200 and code <=300:
print("effective ip")
return True
else:
print("invalid ip and port")
self.delete_ip(ip)
return False
def get_random_ip(self):
#从数据库中随机获取一个可用的ip
random_sql= """
SELECT ip,port FROM proxy_ip ORDER BY RAND() LIMIT 1
"""
result = cursor.execute(random_sql)
for ip_info in cursor.fetchall():
ip = ip_info[0]
port = ip_info[1]
judge_re = self.judge_ip(ip, port)
if judge_re:
return "http://{0}:{1}".format(ip, port)
else:
return self.get_random_ip()
# crawl_ips()
#注意这里的用法
if __name__ == "__main__":
a = GetIP()
b = a.get_random_ip()
print (b)
middleware中编写获取ip代理:
from tools.crawl_xici_ip import GetIP
class RandomProxyMiddleware(object):
#动态设置ip代理
def process_request(self, request, spider):
get_ip = GetIP()
request.meta["proxy"] = get_ip.get_random_ip()
scrapy-proxies github上有 可以去上面看
免费的代理ip可能不稳定,如果有需要可以试试收费的
scrapy-crawlera github上有的
tor:洋葱网络 洋葱浏览器 经过包装达到隐藏ip效果
验证码识别方法
- 编码实现(tesseract-ocr):识别率低
- 在线打码:高 例:云打码
- 人工打码:几乎就是人在操作。。。
其他防止被识别的技能:
禁用cookie (request就不会把我们的cookie带过去)(一般要登录的不禁用,不用登陆的禁用)
settings中:COOKIES_ENABLED = False
启用限速扩展 (前面已经说过了)
要先开启再设置值
AUTOTHROTTLE_ENABLED = TRUE
DOWNLOAD_DELAY = 10
给不用的spider适用不用的setting值
class LagouSpider(CrawlSpider):
#这里的会覆盖settings里的
custom_settings = {
"COOKIES_ENABLED": True
}