1. 什么是爬虫?
就是在互联网上一直爬行的蜘蛛, 如果遇到需要的资源, 那么它就会抓取下来(html内容);
模拟浏览器快速访问页面的内容.
2. 浏览网页的过程中发生了什么?
- 浏览器输入http://www.baidu.com/bbs/;
- 1). 根据配置的DNS获取www.baidu.com对应的主机IP;
- 2). 根据端口号知道跟服务器的那个软件进行交互。
- 3). 百度的服务器接收客户端请求:
- 4). 给客户端主机一个响应(html内容) ----- html, css, js
- 5). 浏览器根据html内容解释执行, 展示出华丽的页面;
</li> <li
style="margin: 0px 10px 0px 5px; width: 120px; float: left; height: 30px; display: inline;">
<a href="http://www.cfets-icap.com.cn/" target="_blank" style="color:#08619D">
上海国际货币经纪公司
</a>
</li>
常见模拟浏览器的信息:
1.Android
Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19
Mozilla/5.0 (Linux; U; Android 4.0.4; en-gb; GT-I9300 Build/IMM76D) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30
Mozilla/5.0 (Linux; U; Android 2.2; en-gb; GT-P1000 Build/FROYO) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1
2.Firefox
Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0
Mozilla/5.0 (Android; Mobile; rv:14.0) Gecko/14.0 Firefox/14.0
3.Google Chrome
Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36
Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19
4.iOS
Mozilla/5.0 (iPad; CPU OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A334 Safari/7534.48.3
下面学习两种解决反爬虫的方法
1.反爬虫模拟浏览器
把html的user-agent复制出来作为模拟浏览器,或者复制上面总结的常用模拟浏览器也可以
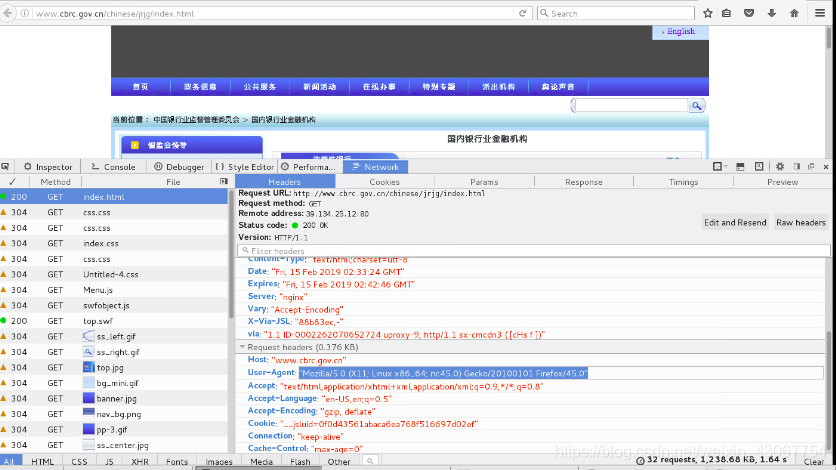
鼠标晃动到需要的银行网址上面,获取有网址的那一段html代码。

import random
import re
from urllib.request import urlopen, Request
from urllib.error import URLError
def get_content(url):
"""获取页面内容, 反爬虫之模拟浏览器"""
# 防止一个浏览器访问频繁被封掉;在html上复制即可
user_agents = [
"Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0",
"Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19",
"Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0",
]
try:
# reqObj = Request(url, headers={'User-Agent': user_agent})
# 1 实例化request对象
reqObj = Request(url)
# 动态添加爬虫请求的头部信息, 可以在实例化时指定, 也可以后续通过add—header方法添加
reqObj.add_header('User-Agent', random.choice(user_agents))
except URLError as e:
print(e)
return None
else:
# 2 urlopen
content = urlopen(reqObj).read().decode('utf-8').replace('\t', ' ')
return content
def parser_content(content):
"""解析页面内容, 获取银行名称和官网URL地址"""
pattern = r'<a href="(.*)" target="_blank" style="color:#08619D">\s+(.*)\s+</a>'
# findall只返回分组里的内容
bankinfos = re.findall(pattern, content)
if not bankinfos:
raise Exception("没有获取符合条件的信息")
else:
return bankinfos
# print(bankinfos)
"""
<a href="http://www.cdb.com.cn/" target="_blank" style="color:#08619D">
国家开发银行
</a>
"""
def main():
url = "http://www.cbrc.gov.cn/chinese/jrjg/index.html"
content = get_content(url)
bankinfos = parser_content(content)
with open('doc/bankinfo.txt', 'w') as f:
# ('http://www.cdb.com.cn/', '国家开发银行\r')
for bank in bankinfos:
name = bank[1].rstrip()
url = bank[0]
# 根据正则判断银行的url地址是否合法, 如果合法才写入文件;因为有很多银行网址不存在
pattern = r'^((https|http|ftp|rtsp|mms)?:\/\/)\S+'
if re.search(pattern, url):
f.write('%s: %s\n' %(name, url))
else:
print("%s无官方网站" %(name))
print("写入完成....")
if __name__ == '__main__':
main()
输出:

保存在文件里
 2.反爬虫设置ip代理
2.反爬虫设置ip代理
推荐一个代理网站西刺免费ip代理
1. 为什么?
2. 如何防止IP被封?
- 设置延迟: time.sleep(random.randint(1,3))
- 使用IP代理, 让其他的IP代替你的IP访问页面;
3. 如何获取代理IP?
https://www.xicidaili.com/ (西刺代理网站提供)
proxyhandler步骤与request的相似:
ProxyHandler ======> Request()
Opener ====== urlopen()
安装Opener
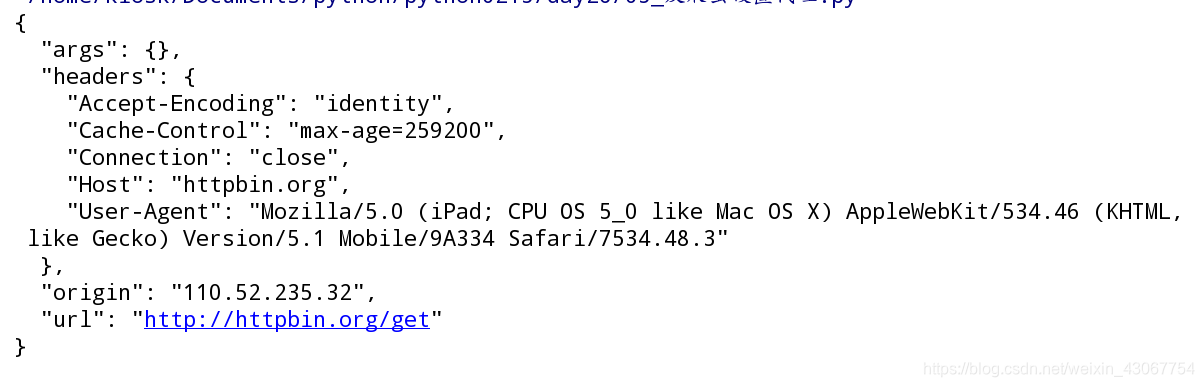
4. 如何检测代理是否成功? http://httpbin.org/get
from urllib.request import ProxyHandler, build_opener, install_opener, urlopen
def use_proxy(proxies, url):
# 1. 调用urllib.request.ProxyHandler
proxy_support = ProxyHandler(proxies=proxies)
# 2. Opener 类似于urlopen
opener = build_opener(proxy_support)
# 3. 安装Opener
install_opener(opener)
# user_agent = "Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0"
# user_agent = "Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0"
user_agent = 'Mozilla/5.0 (iPad; CPU OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A334 Safari/7534.48.3'
# 模拟浏览器;
opener.addheaders = [('User-agent', user_agent)]
urlObj = urlopen(url)
content = urlObj.read().decode('utf-8')
return content
if __name__ == '__main__':
url = 'http://httpbin.org/get'
# 检查ip是否设置成功的网站
proxies = {'https': "116.209.55.191:9999", 'http': '110.52.235.32:9999'}
# 这个ip在西刺上获取,尽量找存活时间长的
cont = use_proxy(proxies, url)
print(cont)
因为这个网站http服务,所以origin就是刚在proxies设置里的http服务的ip