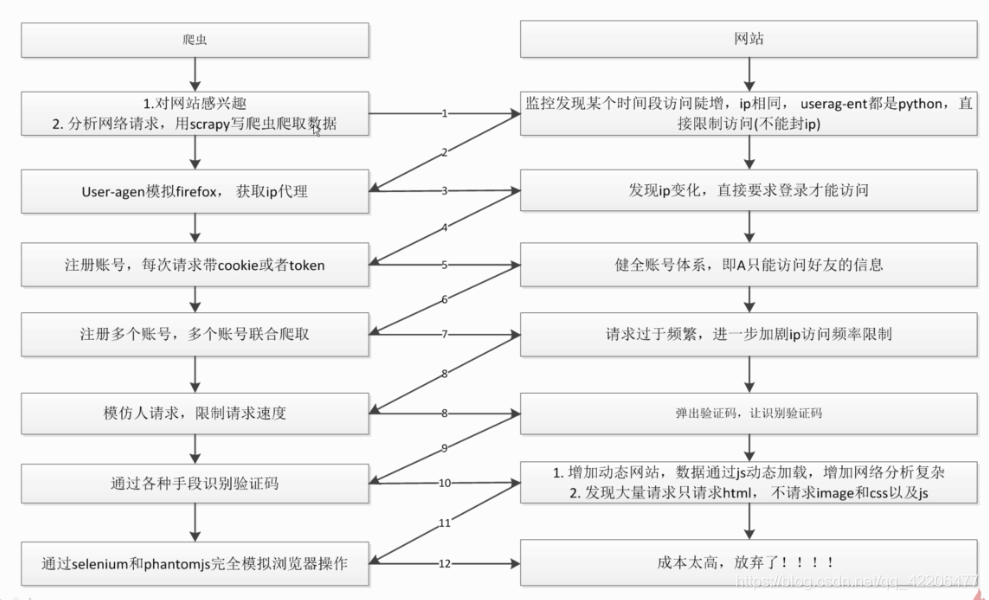
爬虫与反爬虫的对抗过程


对抗过程:
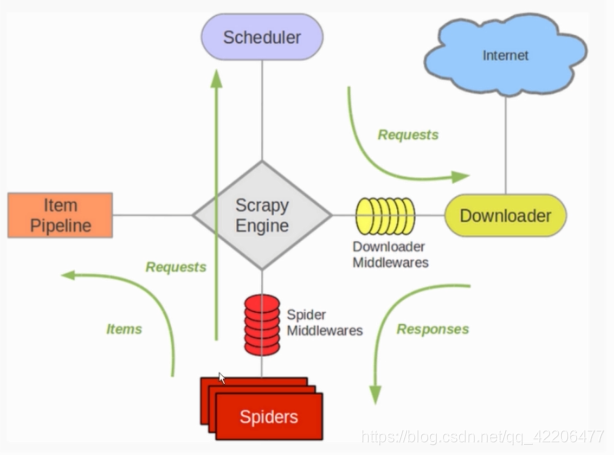
scrapy 架构分析
组件组成:
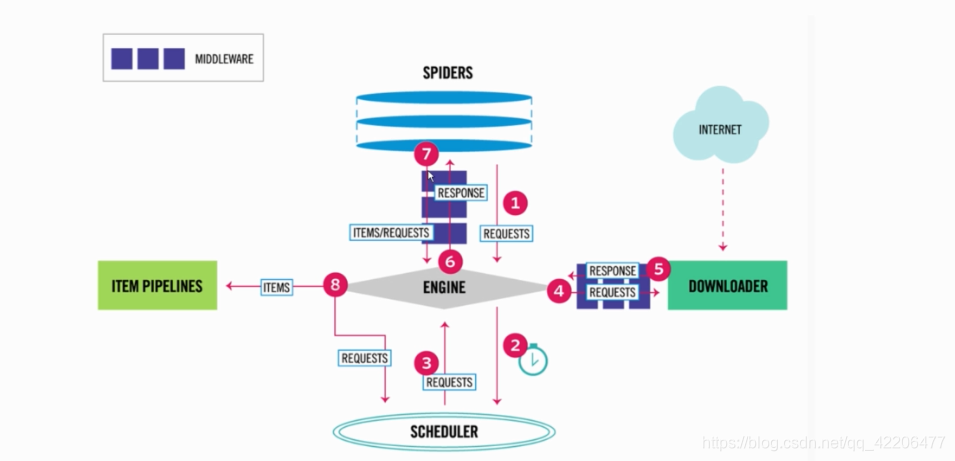
运作流程:
通过downloadmiddleware随机更换user-agent
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等
查看scrapy中useragent源码:
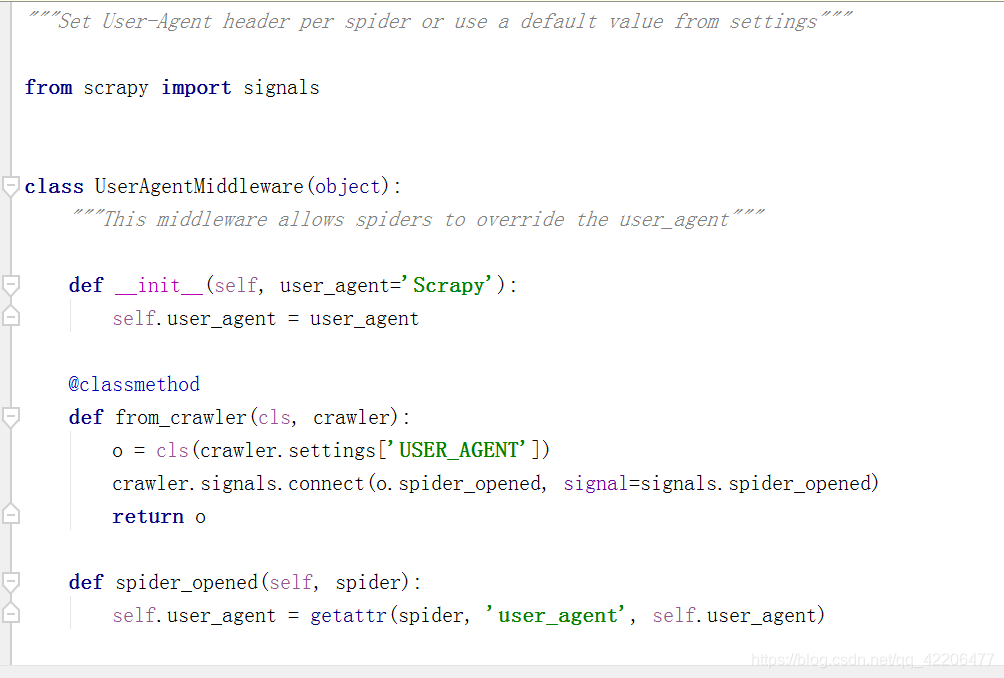
可以发现,默认的user_agent是Scrapy,如果我们不重新设置,很容易被识别为爬虫。
这里我们用到的是fake-useragent,随机获取UA。
github地址:https://github.com/hellysmile/fake-useragent

from fake_useragent import UserAgent
ua = UserAgent()
ua.random #获取随机UA
就这么几行简单的代码,我们就可以获取随机的UA。
下面我们就开始在下载器中间件中实现随机更换user-agent
首先安装fake-useragent:
pip install fake-useragent
在middlewares中新建一个RandomUserAgentMiddlware:
class RandomUserAgentMiddlware(object):
#随机更换user-agent
def __init__(self,crawler):
super(RandomUserAgentMiddlware, self).__init__()
self.ua = UserAgent()
self.ua_type = crawler.settings.get("RANDOM_UA_TYPE","random")#获取值,默认为random
@classmethod
def from_crawler(cls,crawler):
return cls(crawler)
def process_request(self,request,spider):
def get_ua():
ua = getattr(self.ua,self.ua_type)
return getattr(self.ua,self.ua_type) #类似于self.ua.self.ua_type
request.headers.setdefault('User-Agent',get_ua())
同时在settings中设置(一定要将默认的UserAgentMiddleware设置为None):
DOWNLOADER_MIDDLEWARES = {
'JobSpider.middlewares.RandomUserAgentMiddlware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
RANDOM_UA_TYPE = "random"
运行一下,发现请求头中成功的带上了随机UA:

Scrapy实现IP代理池
爬虫在爬取过快时,ip就可能被服务器禁止,ip是一种重要的资源,那么如何更换IP呢?
对于阿里云服务器ip地址是固定的。
对于小区或者公司的网络,ip地址是动态分配的。所以在某些情况下,重启路由器,可能会更换ip地址。
这里我们引入ip代理:
如果不使用代理服务器,目标网站就会清楚的知道我们的本机IP,如何我们爬取过于频繁,就会屏蔽掉我们的IP。
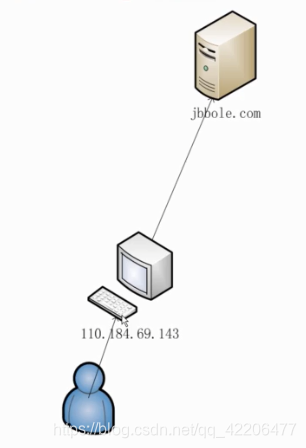
有了代理服务器,和目标网站交互的就是代理服务器,那么我们的本机IP就隐藏了。
从安全性的角度,代理IP的分类:
- 高度匿名代理:不改变客户机的请求,这样在服务器看来就像有个真正的客户浏览器在访问它,这时客户的真实IP是隐藏的,服务器端不会认为我们使用了代理;
- 普通匿名代理:能隐藏客户机的真实IP,但会改编我们的请求信息,服务器端有可能会认为我们使用了代理;
- 透明代理:它不但改变我们的请求信息,还会传送真实的IP地址。

但是只拥有一个IP代理是不够的,我们需要维护一个IP代理池。
关于维护IP代理池,可以参考这篇文章:https://blog.csdn.net/qq_42206477/article/details/85551939
这样我们就可以通过接口 http://127.0.0.1:5000/random 随机获取IP代理。
同样的,在middlewares中新建一个RandomProxyMiddleware类来动态获取IP代理:
class RandomProxyMiddleware(object):
#动态设置ip代理
def process_request(self,request,spider):
self.proxy = requests.get("http://127.0.0.1:5000/random").content.decode("utf-8")
request.meta["proxy"] = self.proxy
并在settings中配置:
DOWNLOADER_MIDDLEWARES = {
'JobSpider.middlewares.RandomProxyMiddleware': 544
}
如此一来,我们就完成了动态更换IP了。
但是,免费的IP代理十分不稳定,建议大家使用收费的代理IP。(不过最稳定的还是自己的IP,所以我们使用自己的IP时,要做好限速,不要无休止的爬取)
这里再介绍几个设置动态IP代理的方法:
- scrapy-proxies 是一款比较强大的proxies插件
github地址:https://github.com/aivarsk/scrapy-proxies
- Scrapy给我们提供了一个收费工具—Crawlera,使用非常简单并且可靠完善。
- tor洋葱网络,tor对我们的网络进行多层包装,最终达到匿名的效果。比较安全和稳定。

Cookie禁用
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
把这个参数设为False,Request就不会带着cookies了。
但是,有些网站(比如知乎)必须登录才可以访问,此时,我们就需要将参数值设为True了。
自动限速
使得用户不用调整下载延迟及并发请求数来找到优化值,用户只需指定允许的最大并发请求数,剩下的交给扩展完成。
下载器在下载同一个网站下一个页面前需要等待的时间:
DOWNLOAD_DELAY = 3
自动限速(AutoThrottle)扩展:
#是否启用AutoThrottle
AUTOTHROTTLE_ENABLED = True
# The initial download delay 设置初始延迟时间
AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#在高延迟情况下最大的下载延迟(单位秒)
AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#起用AutoThrottle调试(debug)模式,展示每个接收到的response。 可以通过此来查看限速参数是如何实时被调整的
AUTOTHROTTLE_DEBUG = False
自定义spider的settings
一个Scrapy工程中,可能有许多个spider,但是只有一个settings文件。
那么如何根据不同的spider需求设置不同的settings呢?
其实我们只需要在spider中设置:
custom_settings = {
"COOKIES_ENABLED" : True
}
custom_settings就会覆盖默认的settings文件。