Hyperparameter Optimization
第一步
选择相当分散的数值,用几个epoch的迭代去学习。
经过几个epoch可以很好地知道哪些值好或不好,然后做出相应调整,得到一个较好的调参区间。
第二步
(或许需要较长的时间)在上一步骤得到的区间内进行进一步的精确搜索。
在训练循环中,有一个类似于寻找NaN这样的技巧,开始训练一些参数,在每个迭代或epoch观察cost,如果出现一个远大于初始cost的值,比如超过初始cost的3倍,就可以认为这不是一个正确的调参方向。
随机搜索 vs. 网格搜索
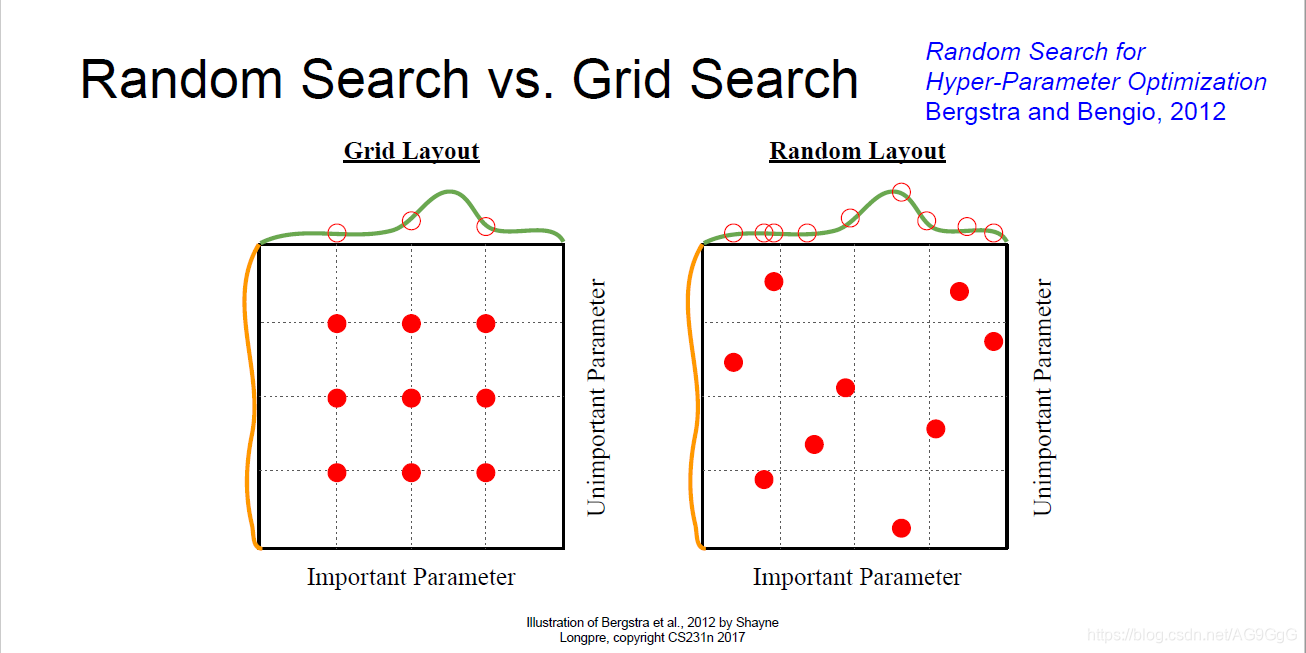
使用网格搜索对不同超参数进行采样,对每个超参数的一组固定值采样。
实际上,对这些值采用网格的方式采样不如用一种随机排列的方式对每个超参数在一定范围内进行随机采样。
随机采样是基于对超过一个变量的函数而言,随机更加真实的考虑。
一些技巧
- Adam的参数配置: , ,学习率=1e-3/5e-4
- 模型集成(Model Ensembles):当我们已经很擅长优化目标函数,希望减少训练和测试之间的误差差距时,可以考虑模型集成的方法。从不同的随机初始值上训练多个不同的模型,测试时,在各个模型上运行测试数据,平均各个模型的预测结果。
- Polyak平均:在训练模型的时候,对不同时刻的每个模型参数求指数衰减平均,从而得到网络训练中一个比较平滑的集成模型,之后使用这些平滑衰减的平均之后的模型参数,而不是截至某一时刻的模型参数。