本节是cs231n笔记:最优化,并介绍了梯度下降方法,然后应用到逻辑回归中。
引言
在上一节线性分类器中提到,分类方法主要有两部分组成:
1. 基于参数的评分函数。能够将样本映射到类别的分值。
2. 损失函数。用来衡量预测标签和真实标签的一致性程度。
这一节介绍第三个重要部分:最优化(optimization)。损失函数能够让我们定量的评估得到的权重w的好坏,而最优化的目标就是找到一个w,使得损失函数的值最小。工作流程如下图:
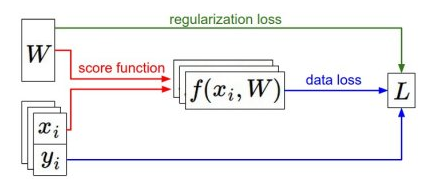
(x,y)是给定的数据集,w是权重矩阵,通过初始化得到。向前传递到评分函数中得到类别的评分值并存储在向量f中。损失函数计算评分函数值f与类标签y的差值,正则化损失只是一个关于权重的函数。在梯度下降过程中,我们计算权重的梯度,然后使用梯度更新权重。一旦理解了这三个部分的关系,我们可以使用更加复杂的评分函数来代替线性映射,比如神经网络、甚至卷积神经网络等,而损失函数和优化过程这两部分则相对保持不变。
梯度下降
梯度下降的思想是,要寻找某函数的最值,最好的方法是沿着函数的梯度方向寻找,移动量的大小称为步长。梯度下降的公式如下:

我们常常听说过梯度上升、梯度下降,那么两者的区别又是什么呢?其实这两者是一样的,只是公式中的减法变成加法,因此公式是:
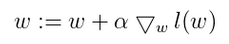
梯度上升是用来求函数的最大值,而梯度下降是用来求最小值。普通的梯度下降版本如下:
# 普通的梯度下降
while True:
weights_grad = evaluate_gradient(loss_fun, data, weights)
weights += =step_size * weights_grad # 进行梯度更新
其中,evaluate_gradient是用来计算梯度的,data是训练样本集,weights是权重,step_size是下降的步长。梯度下降方法是对神经网络的损失函数优化中最常用的方法,核心思想就是一直沿着梯度方向走,知道结果不变为止。梯度下降每次更新权重w时都需要遍历整个数据集,当训练数据大道百万级别的时候,上面的方法将会十分耗时,一种改进的方法是:
小批量数据梯度下降(Mini-batch gradient descent):这中方法一次仅用一个或一部分数据来更新权重,例如在目前最先进的卷积神经网络中,训练集有一百多万,一个小批量中包含256个样本。小批量梯度下降的版本:
# 普通的小批量数据下降
while True:
data_batch = sample_training_data(data, 256) # 256个数据
weights_grad = evaluate_gradient(loss_fun, data_batch, weights)
weights += -step_size * weights_grad # 参数更新
这种方法之所以效果不错,是因为训练集中存在相关的样本。要理解这一点,可以想想一种极端情况,在ILSVRC中,120W个图像是1000张不同的图片,每张复制1200份得到,对比这120W张图像的损失均值应该和1000张子集损失一样。实际数据集中,不会包含这么多重复图像,所以小批量梯度下降方法是对整个数据集梯度的一个近似。因此小批量梯度下降方法能够更快的收敛,并更加频繁的更新参数。
小批量数据梯度下降方法有一个极端情况,那就是小批量中只有一个数据样本,这种方法被称作随机梯度下降(SGD)或者被称为在线(on-line)梯度下降,这种方法在实际操作中使用的并不多,因为使用向量化的代码计算包含100个样本的梯度效率要比计算100次1个样本梯度的效率高得多。但SGD常常被用来指代MGD,或者当看到“使用SGD”,我们就假定使用的是MGD。小批量数据集的大小是一个超参数,但是不需要通过交叉验证来调参,依赖存储器的大小。