前言:
即上篇理论的学习之后,我们来实践一个天池上面的比赛:o2o优惠券的使用预测(目前第一名auc:0.81,本篇:0.786,待优化)
首先解题思路来源于原第一名wepe:https://github.com/wepe/O2O-Coupon-Usage-Forecast
笔者这里对其进行了进一步的归并总结,本文分为两大部分第一部分就是特征提取,第二部分是模型训练,即参照上篇理论的讲解,第二部分会介绍Xgboost的重要超参数。由于上篇已经介绍过部分参数含义,所以本篇不会累述,凡是讲解过得,这里会以#号标识,如不懂请看理论部分,笔者还是建议在用Xgboost之前,还是要对其原理有一定的了解,不要随大流拿过来就是用,随便训练训练,其实这样学习到的东西非常有限,而且对其模型参数也没有一个深刻的认识,可能只是随便百度一下看了看其表面意思,具体含义并不是很清楚,所以还是希望看一下原理,网上已经有很多Xgboost的文章都很好,自己也是从中学到很多,这里就顺便安利一下自己写过的:
https://blog.csdn.net/weixin_42001089/article/details/84965333
其实Xgboost是集成学习这一大家族中的一员,所以希望从下面这篇看起,相信会对机器学习集成学习这一大分支有一个整体系统的认识,对以后深入该领域都会有些许的帮助。
https://blog.csdn.net/weixin_42001089/article/details/84935462
当然啦,这里只是推荐一下,网上还有很多更好的关于Xgboost讲解,笔者只是想表达一个意思:先原理,后实践。
本篇接下来的全部代码和比赛数据:
https://github.com/Mryangkaitong/python-Machine-learning/tree/master/Xgboost
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
数据集介绍:
github 中,笔者在Data下面有两个数据集即:
其中data_origin下面是原始数据,data_preprocessed下面是经过了特征提取后的预处理数据
data_origin中包含三个文件
第一个是要提交比赛的测试数据,字段含义如下:

第二个是供我们使用的训练数据,线下数据,其实原比赛数据还提供了线上数据,因为本文没有使用,所以就没上传,后续想要进 一步优化使用该数据的可以当天池官网进行下载,其字段含义如下:

第三个是要提交数据,即最终要提交的数据形式,其字段含义如下:

本赛题提供用户在2016年1月1日至2016年6月30日之间真实线上线下消费行为,预测用户在2016年7月领取优惠券后15天以内的使用情况。
注意: 为了保护用户和商家的隐私,所有数据均作匿名处理,同时采用了有偏采样和必要过滤。
评价方式:
本赛题目标是预测投放的优惠券是否核销。针对此任务及一些相关背景知识,使用优惠券核销预测的平均AUC(ROC曲线下面积)作为评价标准。 即对每个优惠券coupon_id单独计算核销预测的AUC值,再对所有优惠券的AUC值求平均作为最终的评价标准。 关于AUC的含义与具体计算方法,可参考维基百科
data_preprocessed中也包含了三个数据集:

其实通过特征提取data_origin数据后得到的三个数据集,我们使用模型训练以及最终预测的时候就是直接利用该三个数据集,当然了,这三个数据集不是必须要下载的,可以通过运行体征提取部分的代码进行得到。
------------------------------------------------------------------------------------------------------------------------------------------------------------------
提取体征:
该部分代码位于code下的ofoFeature.ipynb

这部分最大的亮点在于采用滑窗的方法对数据集进行了划分

对于为什么要这样做,很多人感到了困惑,其实很好理解。跟着笔者思路一步步来:
首先通过数据集部分的介绍我们知道可以利用的信息非常有限即就这7个字段:

为此我们想到要进行特征提取,获得尽可能多的额外信息。都可以提取哪些信息呢?一句话竟可能多的想吧:
wepe大神将其归纳成了五种类型信息:





有了上面的想法,我们去看看我们最终要预测的字段:

你会发现没有Date这个字段,这是肯定的嘛!如果都给了那还预测个啥,哈哈是吧。
同时会发现上面归纳出的种种待提取的信息,相当一部分信息是要用到Date即消费日期这一字段的。
那么问题来了,我们在给训练数据提取特征的时候是没有任何问题的,但是当要给最后的预测数据即2016年7月后的数据提取体征时怎么办呢?其根本就没有Date。
于是可以这样想,其实最后提取出来的特征信息代表的是一种习惯或者叫做固有属性,比如个人的一些消费习惯啦,商家的受欢迎程度啦等等,这些其实是不会随着月份改变而改变的,那我们就用7月份的前三个月来提取这些特征,然后默认为7月份也是这种特征信息,依照这种规则方法,我们在给训练集提取特征的时候也都是统一用前三个月的特征来默认为本月的特征,于是就出现了开始那样采用滑窗的方法对数据集进行了划分,进而会发现在上面归纳特征部分的《其他特征》和《优惠券相关》中提取的信息中不需要用到Date这一字段,于是在提取这两部分特征的时候就没有使用前三个月,而就是使用本月,在接下来的代码中也可以清晰看到,当然了这部分信息其实在真真实践的时候其实是得不到的对吧,假设现在来了一个客户要让我们预测,我们总不能说,现在不能预测,等这个月过完吧,我们再统计一下他的信息,进行预测是吧!从这个角度来讲,其实也刚好印证了为什么要采用滑窗的方法,比喻着总结为一句话那就是:评估一个人时,我们所能用到的信息就是根据其以前的所作所为,而不能也得不到其将来的言行。
展开联想:假如我们要给12月份提取特征,其实是不能默认用11月份的信息的,为什么呢?因为有个双11,即11月份购物欲望很强,这是某个时间点的特殊,不是普遍的,不能将其视为一贯的行为强加给12月份。
下面就来简单看一下代码:

首先定义两个路径,一个是源数据一个是预处理后数据存放的路径
接下来就是加载数据,划分数据集,提取特征,笔者这里将代码重写为了函数,这样更加简洁便于理解。
这里有一个小点需要注意:
off_train = pd.read_csv(os.path.join(DataPath,'ccf_offline_stage1_train.csv'),header=0,keep_default_na=False)
off_train.columns=['user_id','merchant_id','coupon_id','discount_rate','distance','date_received','date']
off_test = pd.read_csv(os.path.join(DataPath,'ccf_offline_stage1_test_revised.csv'),header=0,keep_default_na=False)
off_test.columns = ['user_id','merchant_id','coupon_id','discount_rate','distance','date_received']看到keep_default_na=False部分了吧
当使用了改参数,那么加载后数据中如果有缺省值那么其默认是null,大部分是数字字段的数据类似是object即可以看做是字符串,当不写这句话时默认缺省值NAN,即大部分是数字字段是float,这也直接导致了怎么判断缺省值的问题:
当是null时很好说,比如判断date字段时是否是空省值就可用
off_train.date=='null'当是NAN时可是使用:
off_train.date==off_train.date当其为真时,是非空值,当其为假时是空值。更多该方面探讨(https://blog.csdn.net/weixin_42001089/article/details/83715484)
本文采用的是第一种加载方式,即空省值是null的方式如下:

主函数是位于一个叫做 DataProcess中
里面对应着上面归纳的五种信息:
GetOtherFeature:其它特征
GetMerchantRelatedFeature:商家相关特征
GetUserRelatedFeature:商户相关特征
GetUserAndMerchantRelatedFeature:商户-商家交互特征
GetCouponRelatedFeature:优惠券相关特征
如下:
def DataProcess(dataset,feature,TrainFlag):
other_feature = GetOtherFeature(dataset)
merchant = GetMerchantRelatedFeature(feature)
user = GetUserRelatedFeature(feature)
user_merchant = GetUserAndMerchantRelatedFeature(feature)
coupon = GetCouponRelatedFeature(dataset,feature)
dataset = pd.merge(coupon,merchant,on='merchant_id',how='left')
dataset = pd.merge(dataset,user,on='user_id',how='left')
dataset = pd.merge(dataset,user_merchant,on=['user_id','merchant_id'],how='left')
dataset = pd.merge(dataset,other_feature,on=['user_id','coupon_id','date_received'],how='left')
dataset.drop_duplicates(inplace=True)
dataset.user_merchant_buy_total = dataset.user_merchant_buy_total.replace(np.nan,0)
dataset.user_merchant_any = dataset.user_merchant_any.replace(np.nan,0)
dataset.user_merchant_received = dataset.user_merchant_received.replace(np.nan,0)
dataset['is_weekend'] = dataset.day_of_week.apply(lambda x:1 if x in (6,7) else 0)
weekday_dummies = pd.get_dummies(dataset.day_of_week)
weekday_dummies.columns = ['weekday'+str(i+1) for i in range(weekday_dummies.shape[1])]
dataset = pd.concat([dataset,weekday_dummies],axis=1)
if TrainFlag:
dataset['date'] = dataset['date'].fillna('null');
dataset['label'] = dataset.date.astype('str') + ':' + dataset.date_received.astype('str')
dataset.label = dataset.label.apply(get_label)
dataset.drop(['merchant_id','day_of_week','date','date_received','coupon_count'],axis=1,inplace=True)
else:
dataset.drop(['merchant_id','day_of_week','coupon_count'],axis=1,inplace=True)
dataset = dataset.replace('null',np.nan)
return dataset从这里也可以清晰看到:
GetMerchantRelatedFeature
GetUserRelatedFeature
GetUserAndMerchantRelatedFeature
利用的都是feature即本月的特征其实是前三个月提取的特征信息
GetOtherFeature
GetCouponRelatedFeature
利用的是dataset即就是当前本月提取的信息(再次说明:实际生产中不可用)
有人可能质疑道:GetCouponRelatedFeature中不是也利用feature信息了吗?我都看到了,不要骗我,哈哈,好的好的,这里解释一下:
在GetCouponRelatedFeature函数中有一个字段:
dataset['days_distance']假设我们现在在提取20160515~20160615区间的信息
它的含义是当前领取优惠券时间距离5月15号已有多少天了,只不过去看原代码中这里应该是5月14,即其选取特征区间的最大值,同理当我们提取20160701~20160731区间信息时,源代码中是6月30日,所以这里只是利用了划分日期的分界线,并不是利用了前三个月的信息来当做本月的特征信息,对应到代码中是:
t = feature[feature['date']!='null']['date'].unique()
t = max(t)
可以看到只是提取了各自feature取得最大时间即t,而且t也仅仅是在‘days_distance’字段时使用,GetCouponRelatedFeature函数下其它地方根本就没有t即没有feature。所以本质来讲GetCouponRelatedFeature函数利用的还是dataset即本月数据。
我们利用DataProcess这个批处理函数,最后就得到了数据集介绍部分data_preprocessed下的三个数据集
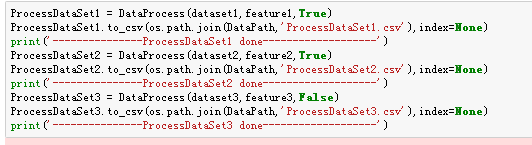
其中
ProcessDataSet1.csv对应的是图片中的训练集2
ProcessDataSet2.csv对应的是图片中的训练集1
ProcessDataSet3.csv对应的是图片中的测试集
具体到每一个提取特征的函数细节,这里笔者就不再累述了,代码中笔者都加了大量的注释,对比着那五种特性信息下的每一条再结合代码相信都能看懂。
说明:特征工程是非常重要的,也是一个难点,但是有套路,大家可以看一下:https://tianchi.aliyun.com/mas-notebook/preview/36434/bffd10b0-18d3-11e9-bace-61d7df7cd8c1.ipynb/-1?lang=zh-cn
------------------------------------------------------------------------------------------------------------------------------------------------------------------
模型训练
毫无疑问我们使用的是Xgboost
注意审题,题目中的评价方式是对每个优惠券coupon_id单独计算核销预测的AUC值,再对所有优惠券的AUC值求平均作为最终的评价标准。而不是我们平时简单的auc。
于是我们定义了一下相应的评价函数用来性能评价:
#性能评价函数
def myauc(test):
testgroup = test.groupby(['coupon_id'])
aucs = []
for i in testgroup:
tmpdf = i[1]
if len(tmpdf['label'].unique()) != 2:
continue
fpr, tpr, thresholds = roc_curve(tmpdf['label'], tmpdf['pred'], pos_label=1)
aucs.append(auc(fpr,tpr))
return np.average(aucs)
接着就是加载我们预处理过得数据集,这里讲ProcessDataSet1和ProcessDataSet2合并为一个更大的数据集dataset12
并且抛弃了一些训练过程中不必要的字段,并删除了重复项
dataset1 = pd.read_csv('D:/MachineLearning/ofo/ofoOptimization/ProcessDataSet1.csv')
dataset1.label.replace(-1,0,inplace=True)
dataset2 = pd.read_csv('D:/MachineLearning/ofo/ofoOptimization/ProcessDataSet2.csv')
dataset2.label.replace(-1,0,inplace=True)
dataset3 = pd.read_csv('D:/MachineLearning/ofo/ofoOptimization/ProcessDataSet3.csv')
dataset1.drop_duplicates(inplace=True)
dataset2.drop_duplicates(inplace=True)
dataset12 = pd.concat([dataset1,dataset2],axis=0)
dataset12_y = dataset12.label
dataset12_x = dataset12.drop(['user_id','label','day_gap_before','coupon_id','day_gap_after'],axis=1)
dataset3.drop_duplicates(inplace=True)
dataset3_preds = dataset3[['user_id','coupon_id','date_received']]
dataset3_x = dataset3.drop(['user_id','coupon_id','date_received','day_gap_before','day_gap_after'],axis=1)
dataTrain = xgb.DMatrix(dataset12_x,label=dataset12_y)
dataTest = xgb.DMatrix(dataset3_x)注意Xgboost训练的数据必须要使用xgb.DMatrix()转化后的形式,这里就转化了一下。
接下来就是训练模型,保存模型
params={'booster':'gbtree',
'objective': 'rank:pairwise',
'eval_metric':'auc',
'gamma':0.1,
'min_child_weight':1.1,
'max_depth':5,
'lambda':10,
'subsample':0.7,
'colsample_bytree':0.7,
'colsample_bylevel':0.7,
'eta': 0.01,
'tree_method':'exact',
'seed':0,
'nthread':12
}
watchlist = [(dataTrain,'train')]
model = xgb.train(params,dataTrain,num_boost_round=3500,evals=watchlist)
model.save_model('D:/MachineLearning/ofo/ofoOptimization/xgbmodel')下面来说一下各个参数的含义,注意就像前面说过的理论部分介绍过的参数,这里会标记#,不再累述,请看理论部分
https://blog.csdn.net/weixin_42001089/article/details/84935462
开始:
'booster':#
'objective':可选的目标函数
- 定义学习任务及相应的学习目标,可选的目标函数如下:
- “reg:linear” –线性回归。
- “reg:logistic” –逻辑回归。
- “binary:logistic” –二分类的逻辑回归问题,输出为概率。
- “binary:logitraw” –二分类的逻辑回归问题,输出的结果为wTx。
- “count:poisson” –计数问题的poisson回归,输出结果为poisson分布。
- 在poisson回归中,max_delta_step的缺省值为0.7。(used to safeguard optimization)
- “multi:softmax” –让XGBoost采用softmax目标函数处理多分类问题,同时需要设置参数num_class(类别个数)
- “multi:softprob” –和softmax一样,但是输出的是ndata * nclass的向量,可以将该向量reshape成ndata行nclass列的矩阵。每行数据表示样本所属于每个类别的概率。
- “rank:pairwise” –set XGBoost to do ranking task by minimizing the pairwise loss
一般二分类问题就用“binary:logistic”和“rank:pairwise”,其它的都很好理解,而且网上的介绍资料也是一大把,但是介绍“rank:pairwise”的博客却很少,而且当使用“rank:pairwise”时,直接用训练好的模型预测的时候结果有时候令人费解甚至出现否值,为止笔者这里专门有一篇文章对其进行了探究:
https://blog.csdn.net/weixin_42001089/article/details/84146238
希望对大家有所帮助
本篇采用的就是“rank:pairwise”目标函数。
'eval_metric':评价函数,用户是可以自己定义自己的评价函数的,这里采用了auc,对了其实我们在一开头是定义了自己评价函数 的
'gamma':#默认0
'min_child_weight':#
'max_depth':这个很好理解,就是每个基分类树的最大深度
'lambda':#
'subsample':这个参数控制每棵树随机采样的比例:减小该值,算法会更加保守,避免过拟合。但是,过小,它可能会导致欠拟合。
一般:0.5-1
'colsample_bytree':用来控制每棵随机采样的列数的占比
'colsample_bylevel':用来控制树的每一级的每一次分裂,对列数的采样的占比。
'eta': #
'seed':复现随机数据的结果,也可以用于调整参数
'nthread':进行多线程控制,应当输入系统的核数。
num_boost_round:多少颗基分类树
evals:显示的训练过程,这里的watchlist可以是:
watchlist = [(Train,'train'),(Test,'test')]
这样就可以同时显示当前训练下训练集和测试集的auc,只不过笔者这里只有训练集没有测试集,澄清一下:
不是没有训练集,我们代码中的dataTest中是要我们预测的,提交的,其中并没有l真实的abel,而watchlist中的Test其实就是我们通常的将样本划分为训练集和测试集中的测试集,对应到我们代码中应该是将dataTrain划分一下,但是笔者这里并没有这么做,相当于将全部样本作为了训练集。
我们看一下训练过程:这里仅仅截取了最后一部分
oots, 62 extra nodes, 0 pruned nodes, max_depth=5
[3495] train-auc:0.907827
[17:43:58] C:\Users\Administrator\Desktop\xgboost\src\tree\updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=5
[3496] train-auc:0.90783
[17:43:59] C:\Users\Administrator\Desktop\xgboost\src\tree\updater_prune.cc:74: tree pruning end, 1 roots, 62 extra nodes, 0 pruned nodes, max_depth=5
[3497] train-auc:0.907834
[17:43:59] C:\Users\Administrator\Desktop\xgboost\src\tree\updater_prune.cc:74: tree pruning end, 1 roots, 62 extra nodes, 0 pruned nodes, max_depth=5
[3498] train-auc:0.907838
[17:44:00] C:\Users\Administrator\Desktop\xgboost\src\tree\updater_prune.cc:74: tree pruning end, 1 roots, 60 extra nodes, 0 pruned nodes, max_depth=5
[3499] train-auc:0.907843可以看到,随着训练次数的增多训练集的auc也在不断增大,那么用我们自行定义的auc去在训练样本上测一下性能把:
model=xgb.Booster()
model.load_model('D:/MachineLearning/ofo/ofoOptimization/xgbmodel')
temp = dataset12[['coupon_id','label']].copy()
temp['pred'] =model.predict(xgb.DMatrix(dataset12_x))
temp.pred = MinMaxScaler(copy=True,feature_range=(0,1)).fit_transform(temp['pred'].values.reshape(-1,1))
print(myauc(temp))结果:
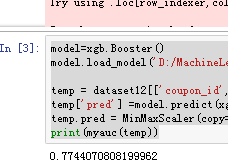
看到是0.77,然后我们就用该模型去预测并提交比赛官网
#predict test set
dataset3_preds1 = dataset3_preds
dataset3_preds1['label'] = model.predict(dataTest)
#标签归一化在[0,1]原作者代码这里有错
#修改前
#dataset3_preds.label = MinMaxScaler(copy=True,feature_range=(0,1)).fit_transform(dataset3_preds.label)
#修改后
dataset3_preds1.label = MinMaxScaler(copy=True,feature_range=(0,1)).fit_transform(dataset3_preds1.label.reshape(-1,1))
dataset3_preds1.sort_values(by=['coupon_id','label'],inplace=True)
dataset3_preds1.to_csv("D:/MachineLearning/ofo/ofoOptimization/xgb_preds.csv",index=None,header=None)
print(dataset3_preds1.describe())这个结果在天池上面的得分便是0.78
![]()
调优:
一般Xgboost调优的顺序可以参考如下:
确定一个学习速率0.1
num_boost_round调优
max_depth 和 min_weight 参数调优
gamma参数调优
正则化参数调优
降低学习速率
关于num_boost_round的调优,一般有两种可选的方法:
第一种就是使用xgb.train+watchlist的形式,首先将num_boost_round设的足够大,然后在运行的过程中我们看训练集和测试集的auc变化,一般来说训练集上面的auc会一直增加,但是测试集上面的auc会随着num_boost_round增大因为过拟合而下降,这样我们就会在训练过程中找到测试集的一个峰值,一旦找到,我们就可以结束训练了。
第二种就是使用其内置的xgb.cv函数,它的好处在于不用我们实时去人工观察,而是直接会得到最佳的num_boost_round值,同理我们还是直接给一个足够大的初始值让其去训练,然后就美滋滋的等待其返回最佳结果值把。
这里就来演示一下第二种方法:
params={'booster':'gbtree',
'objective': 'rank:pairwise',
'eval_metric':'auc',
'gamma':0.1,
'min_child_weight':1.1,
'max_depth':5,
'lambda':10,
'subsample':0.7,
'colsample_bytree':0.7,
'colsample_bylevel':0.7,
'eta': 0.01,
'tree_method':'exact',
'seed':0,
'nthread':12
}
cvresult = xgb.cv(params, dataTrain, num_boost_round=20000, nfold=5, metrics='auc', seed=0, callbacks=[
xgb.callback.print_evaluation(show_stdv=False),
xgb.callback.early_stop(50)
])
num_round_best = cvresult.shape[0] - 1
print('Best round num: ', num_round_best)
watchlist = [(dataTrain,'train')]
model1 = xgb.train(params,dataTrain,num_boost_round=num_round_best,evals=watchlist)
model1.save_model('D:/MachineLearning/ofo/ofoOptimization/xgbmodel1')
print('------------------------train done------------------------------')其中xgb.cv中的nfold代表的就是交叉验证的份数, xgb.callback.early_stop 是在多少次迭代 metrics 没有变好的情况下提前结束,这个函数可以找到此参数组下最佳的迭代次数(n_estimators)。
其返回DataFrame型的n折交叉验证的平均结果,cvresult.shape[0]即为其最佳迭代次数(代码中这里减不减一并无大碍)
看一下结果:

可以看到最好的是11689,同时我们可以观察到每一轮的train-auc和test-auc
最后当我们知道了最佳的迭代树,便依次训练即可:得到模型model1
然后我们测试一下该模型:
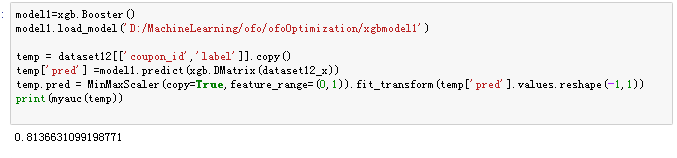
可以看到现在就是0.81啦,其它参数怎么调优呢?
很简单使用sklearn中的网格训练工具GridSearchCV吧。
但是我们以上使用的都是原生态的Xgboost,怎么和sklearn中的GridSearchCV结合呢?
其实sklearn中也有Xgboost的接口即
from xgboost.sklearn import XGBClassifier关于两者怎么结合调优等细节问题,这里有一篇很好的文章也推荐给大家供参考:
https://blog.csdn.net/han_xiaoyang/article/details/52665396
最后对着我们理论篇讲的Xgboost特征筛选功能我们来看一下get_fscore()函数:
feature_score = model1.get_fscore()
feature_score = sorted(feature_score.items(), key=lambda x:x[1],reverse=True)#value逆序排序
fs = []
for (key,value) in feature_score:
fs.append("{0},{1}\n".format(key,value))
with open('D:/MachineLearning/ofo/ofoOptimization/xgb_feature_score.csv','w') as f:
f.writelines("feature,score\n")
f.writelines(fs)看一下结果:
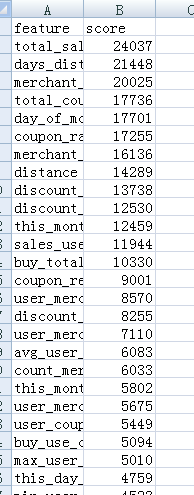
说明一下:笔者再将num_boost_round从3500提到11689后,虽然训练集上面得到了大幅度提高,但是提交结果在测试集上面却没有提升,反而下降了,同时需要说明的是这里其它超参数采用的值都是wepe中给出的,相信也是经过多次尝试优化的结果,关于更多优化方法或细节方法欢迎多多交流,嘻嘻。
------------------------------------------------------------------------------------------------------------------------------------------------------------------
收获总结和感悟:
1)希望通过实践篇后能够对Xgboost有更加深刻的认识
2)特征划分部分滑窗的方法值得学习。
3)最后得分的高低,其实很大部分在于特征提取,其决定了最佳值,模型的调优只不过是在不断向该值逼近。
4)Xgboost的调优过程及方法。
5)遇到问题一定要想办法搞懂,蒙混自己终究还是不会,迟早问题还是会暴露,会花更多的时间去解决!亏。