描述
发放优惠券是各大公司一种重要的营销手段,如电商平台、打车平台、线下门店等等,几乎所有涉及到客户消费的行业都有优惠券的发放,那么如何精准定位发送优惠券,保证发送的优惠券是真正想使用优惠券的人呢,或者我能预测出来每个客户是不是用优惠券,这样一是可以计算营销成本,二是可以留住用户提升品牌竞争力,对企业营销有着重要意义。
思路流程
我们说这篇将介绍下如何通过机器学习方法来分析预测,在给客户发券后在指定时间内用户是否使用该券,
我们拥有某电商用户2017年6月份的优惠券发放和使用记录,利用这些数据来预测7月份用户使用的概率。
- 理解数据
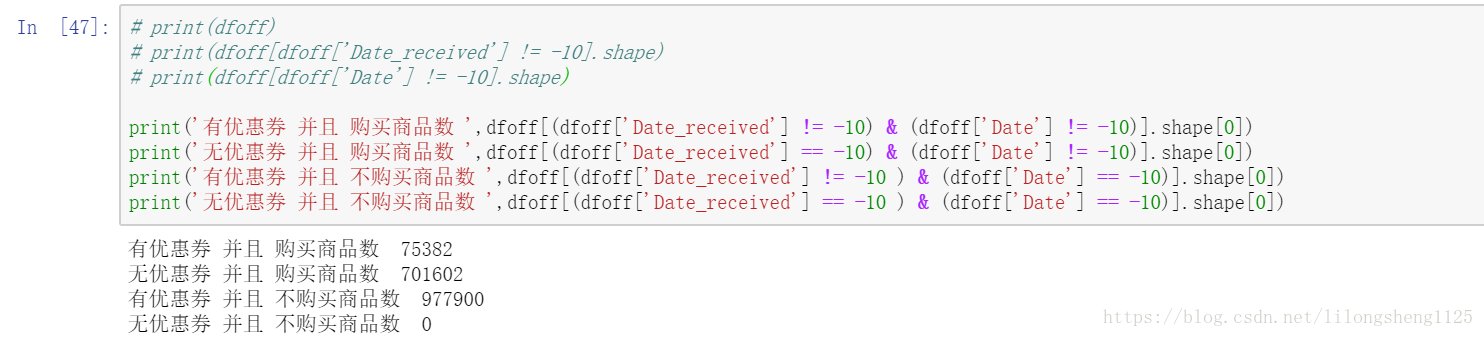
感觉理解数据非常重要,在这个场景中显然用户何时领取的优惠券、何时使用的是两个比较重要特征,这两个特征需要我们理解了数据,才能转化为数字的方式表达出来,对数据理解的越深刻,以后我们可以挖掘的特征越多,我们的模型当然训练出来就越好,如下图:
我统一将NaN值替换为-10了,方便处理,上面即通过优惠券接受日期判断用户是否收到优惠券,再通过是否购买上面商品来判断用户是否真正使用了券,这些信息提取出来可以当做标签,他们都是我们从数据中提取出来的信息,可见有价值的信息很多。
- 数据清洗
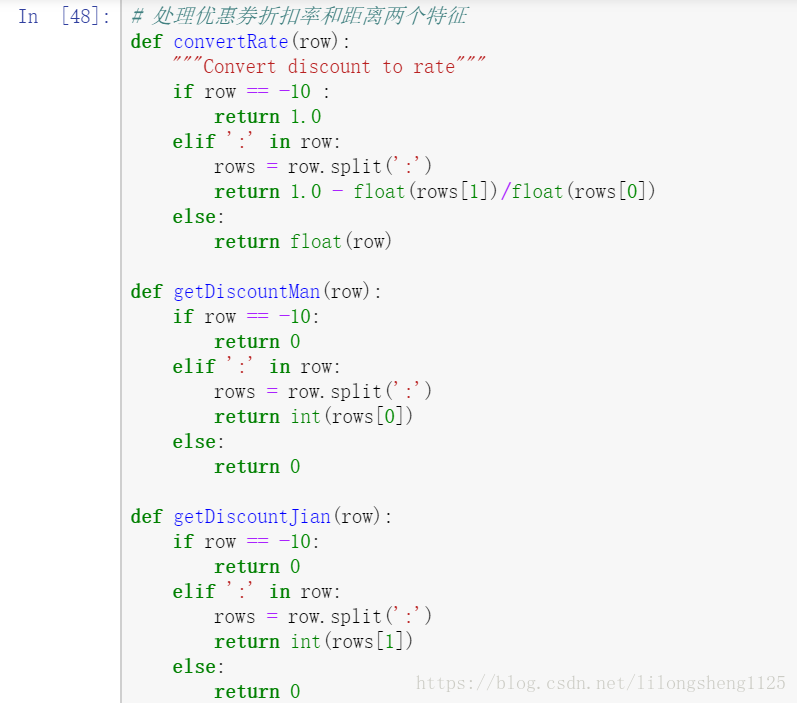
已经存在的数据需要清洗加工为统一的数据样式,可以让算法直接处理的数据格式,如在处理折扣率、满X减Y这种优惠时,将它们处理为统一值:
上面处理是将满X减Y转为了折扣率一样的格式,方便后面进行模型训练。

- 特征提取
在原始数据中优惠券发放都是按着日历来的,想一想可否将这个日期转化为周期,也是可以的,比如:
这些特征都是我们自己来从数据中提取,提取特征需要充分理解原始数据才能提取出来有价值的特征。


- 开始训练
在第一次训练时先只结合了用户的两个分析特征,满减折扣率特征,我们拆分为了0-1之间的折扣率discount_rate,并且把满X(discount_man)减Y(discount_jian),以及折扣类型(discount_type)等列,其次是接收优惠券的日期转为了日期类型,并将日期枚举值转为了one-hot类型字段方便分析,这两字段也算是我们进行了扩展分析。
所有训练属性如下:

模型分析
在这部分涉及到sklearn中工具类,有必要了解下原理,方便我们今后使用SGDClassifier、Pipeline、GridSearchCV。
模型选择:
在确定并清洗完训练特征后,下一步即选择啥模型进行数据训练,这里我们目标是分类,那么KNN、贝叶斯、SVM、LR等分类器是否都可以用呢,都是可以的,sklearn支持常用的分类器实现,可以直接用很方便,避免了重复造轮子,不过我们一定要理解它们的实现原理,这样才能再上面不断优化,创造新的学习器。
说得更专业一点,模型不管多复杂最终出来的是一个函数,根据函数的定义函数的重点是映射关系,如A到B可以通过各种函数来映射,则我们的模型即从输入到输出的一种映射关系,也可以这么理解在数学领域映射叫函数,在机器学习领域叫模型,在李航老师的书中称这个映射集合为假设空间(Hypothesis space),其实是为了方便理解那么多情况而创造出来了一个名词而已。
有很多种、确定了哪类模型后还需要调节各种参数不同参数还对应不同模型,首先我们来用LR分类器梯度上升求解。
参数调优:
sklearn同时页为我们提供了调试参数的方法grid_search,可以输入参数列表和模型、评分函数,它会选择出来得分最优的参数,如果不适用这个调参我们自己一个参数一个参数实验也可以求出最优参数。
官网文档说明:http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html#sklearn.model_selection.GridSearchCV
SGDClassifier类主要采用梯度下降的方法实现了LR和SVM,也就是我们如果要使用逻辑回归和SVM进行预测分类时,该类时一个很好的选择,官网文档如下:
http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.SGDClassifier.html
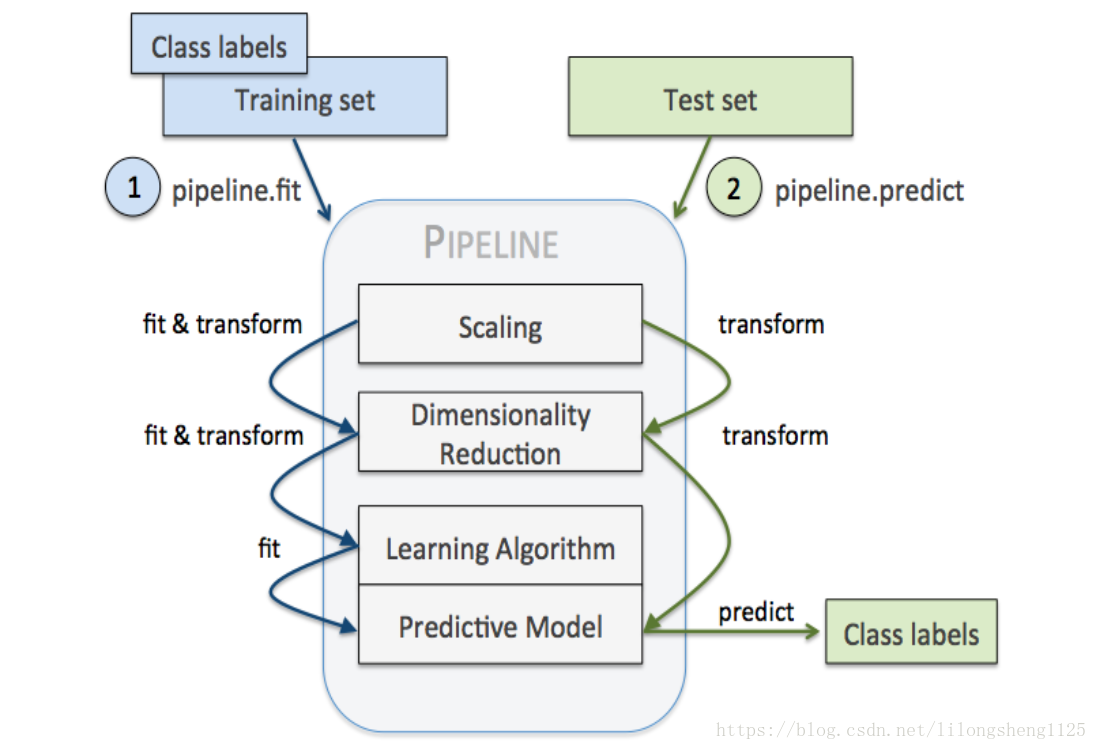
Pipeline机制在机器学习中也比较常见,就如管道含义一样,他可以让我们把好几步流程串联起来一起执行,使得代码简介,类似于java中的链式编程写法,像是一种编程技巧,经常放在管道中的步骤是标准化、降维、学习器三种类型的步骤,在管道中他们会依次执行,每两个衔接地方有抓换适配器,如下图:
代码如下:
def check_model(data, predictors):
classifier = lambda: SGDClassifier(
loss='log', //对数损失函数 逻辑回归
penalty='elasticnet', //l1 l2结合
fit_intercept=True, //截距
max_iter=100, //迭代次数
shuffle=True, //打散样本
n_jobs=1,
class_weight=None)//样本权重一样
model = Pipeline(steps=[
('ss', StandardScaler()),
('en', classifier())
])
parameters = {
'en__alpha': [ 0.001, 0.01, 0.1],
'en__l1_ratio': [ 0.001, 0.01, 0.1]
}
folder = StratifiedKFold(n_splits=3, shuffle=True)
grid_search = GridSearchCV(
model, //分类器
parameters, //参数列表
cv=folder, //交叉验证folder数量
n_jobs=-1, //并行数
verbose=1)//日志长度,不输出训练过程
//运行搜索
grid_search = grid_search.fit(data[predictors],
data['label'])
return grid_search
model = check_model(train, predictors)
print(model.best_score_)//运行过程中观察到的最好评分
print(model.best_params_)//取得最佳结果的参数组合
# valid predict
y_valid_pred = model.predict_proba(valid[predictors])
valid1 = valid.copy()
valid1['pred_prob'] = y_valid_pred[:, 1]
valid1.head(2)
# avgAUC calculation
vg = valid1.groupby(['Coupon_id'])
aucs = []
for i in vg:
tmpdf = i[1]
if len(tmpdf['label'].unique()) != 2:
continue
fpr, tpr, thresholds = roc_curve(tmpdf['label'], tmpdf['pred_prob'], pos_label=1)
aucs.append(auc(fpr, tpr))
print(np.average(aucs))
# test prediction for submission
y_test_pred = model.predict_proba(dftest[predictors])
dftest1 = dftest[['User_id','Coupon_id','Date_received']].copy()
dftest1['label'] = y_test_pred[:,1]
dftest1.to_csv('submit1.csv', index=False, header=False)
dftest1.head()
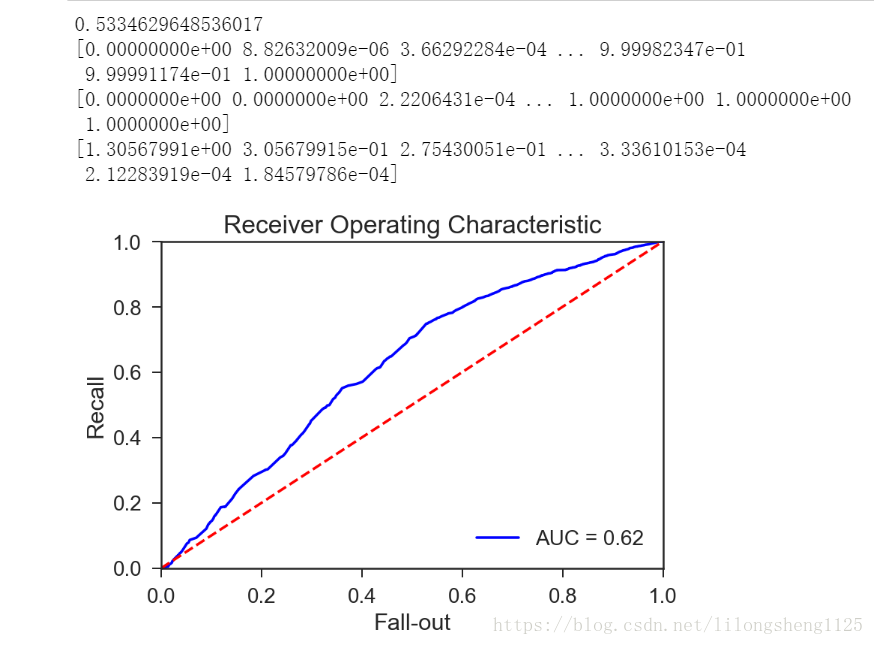
ROC曲线表示的是模型灵敏度,横坐标为FPR ,纵坐标为TPR 即纵坐标表示真正预测为正样本的个数除以正样本个数的比值,横坐标为预测为正的负样本个数除以负样本个数,我们想要的结果是TPR越高越好,但有时FPR也会升高。
第一个参数为标签、第二个为预测概率值,第三个为指定哪类为正类,它的原理也很简单是根据不同的阈值来计算不同的点,然后在连接起来即形成曲线。
from sklearn.metrics import auc
# import matplotlib as plt
plt.rcParams['axes.unicode_minus'] = False
roc_auc = auc(fpr_total, tpr_total)
plt.title('Receiver Operating Characteristic')
plt.plot(fpr_total, tpr_total, 'b', label='AUC = %0.2f' % roc_auc)
plt.legend(loc='lower right')
plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.ylabel('Recall')
plt.xlabel('Fall-out')
plt.show()
如下图我画出来的ROC曲线
ROC曲线评价统计量计算。ROC曲线下的面积值在1.0和0.5之间。在AUC>0.5的情况下,AUC越接近于1,说明诊断效果越好。AUC在 0.5~0.7时有较低准确性,AUC在0.7~0.9时有一定准确性,AUC在0.9以上时有较高准确性。AUC=0.5时,说明诊断方法完全不起作用,无诊断价值。AUC<0.5不符合真实情况,在实际中极少出现。根据经验我们的AUC值为0.62说明模型预测准确率较低,因此还需要继续优化,下篇我们继续优化模型。
问题思考
-除了AUC曲线还有啥有效的方法来分析模型效果?
-我们计算出来AUC值为0.62,那么如何优化模型?提取更有效的特征还是模型上下功夫?
-AUC值是每一个样本点的还是整个数据集的?
题外思考
耶鲁大学的精神
耶鲁大学是美国一所老牌有名的大学,很多国内外争先恐后的进入,它也是唯一一所靠文科出名的大学,可见它将文学思想发扬光大,想一下世界各个大学办学各有各自的特色,将每一种特色做到极致就会脱颖而出成为有名的大学,麻省理工等大学是在于理科研究和教学等方面非常优秀,其实大部分学校都注重理科教学质量,很少有大学拿文科来当做自己的强项,因为啥呢?是不是感觉文科是很虚的科目、是容易出来被骂专业软文的学科,然而耶鲁却把文科的思想做的了极致,在创造新思想新文化、培养人作为未来领袖方面做到了极致。
举个简单的例子如果某个学生家乡遇到困难,那么它是鼓励学习为之多做出一些力量,不是尽些绵薄之力而是尽全力,要有一种为家乡、为祖国奉献的责任感,将故乡、社会、国家的责任当做自己的事情来做的责任感,与不在其位不谋其政思想正好相背离,有时感觉这种思想有点消极影响,它这所学校在于培养学生的责任感。
当然,我们伟大的祖国也不乏这种责任感,很久以前的唐朝就有诗人李贺 提笔 ,如下:
李 贺
男儿何不带吴钩,
收取关山五十州?
请君暂上凌烟阁,
若个书生万户侯?
李贺作为一个文弱书生,想拿起宝剑去收复五十州失地,这首诗被流传千古是因为有社会责任感在里面,有文化精髓在传承,这些都是前任留下的宝贵财富,需要我们去静静品味。
参考文章
Pipeline机制
https://blog.csdn.net/lanchunhui/article/details/50521648
https://www.jianshu.com/p/9c2c8c8ef42d