(作者:陈玓玏)
这个比赛我参加的时间稍微有点久远了,有些思路可能都不是特别清楚了,可以自己再好好细化、补充一下。
赛题中一共有四个文件,分别是线下测试集数据,线下训练集数据,线上训练集数据,以及最后需要提交的结果的格式。我其实在比赛时候只用了线下训练集的数据,已经是够用的了。
那么建模肯定需要确定几个大的方向点:1、label怎么定义?2、时间窗口怎么划分?3、变量怎么延伸?4、用什么算法?5、过拟合了怎么办?
1、label怎么定义?
因为题目已经要求过了,需要预测的是客户在15天内的优惠券使用率,所以我们把领取优惠券以后15内使用定为1,即我们要寻找的正样本,15内不使用的定为0,即负样本。
2、时间窗口怎么划分?
原始数据集中包括的数据是2016年1月1日到2016年6月30日的样本,那么在这几个月内,x值和y值我们都是已知的,然后要通过这之前的行为预测出七月份的y,但是没有七月的数据,所以我们需要给七月留出一个观察窗口,也就是造x变量的窗口。最后划分窗口的结果如下:
——————————————————————————————————————————————————
训练样本
x值产生区间:2016.01~2016.03,y值产生区间:2016.04
预测样本
x值产生区间:2016.04~2016.06,y值产生区间:无,是我们最终需要预测的结果
———————————————————————————————————————————————————
正好就是用三个月来预测一个月,因为这里也不去考虑模型稳定性的问题,因为只预测一个月嘛,不是长期使用这个模型,所以我们也就不会去考虑这些,也就没有通过客户表现的稳定性来确定时间窗口,而是选择了一个可以充分利用样本数据,又能够尽可能长地拉升观察窗口的划分方法。
3、变量怎么延伸?
初始数据其实就只有几列嘛,如下图所示:
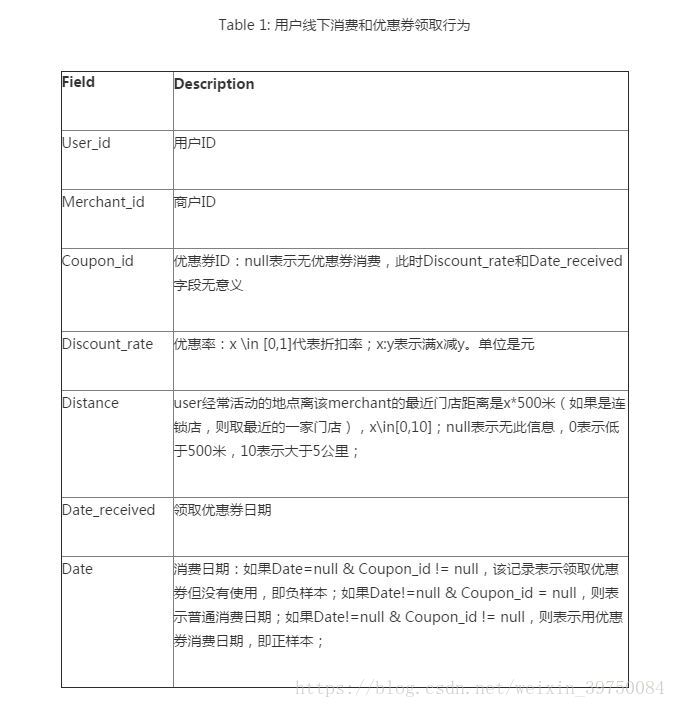
但是这几个变量可用度实在太低,比如用户id和商户id这种变量根本就无效嘛,所以必须要延伸变量,分模块来细化变量,其实就是在细化用户的行为,初期延伸变量的时候肯定是分析得越细越好的。
那么我的思路是比较傻的方法,就是先单变量延伸,再组合延伸。
1、先延伸用户相关的变量,比如通过用户的消费频率、消费最大距离、最小距离、平均距离等来刻画用户的消费习惯;
2、再延伸商户变量,比如商家发布优惠券的频率、商家发布优惠券的最大、最小、平均折扣率等等,而且要区分是满减还是直接打折;
3、再延伸优惠券的变量,比如优惠券的折扣率;
4、接着延伸交叉变量,比如用户在每个商家的消费频率、使用优惠券的消费频率、使用优惠券的比例等等。
感觉延伸变量反正是一个比较恶心的过程,但是也比较有意思,恶心是因为它既感性又理性,可能还要凭一些经验,有意思是因为它其实就是一个刻画行为的过程,值得玩味。
4、用什么算法?
这就是一个二分类问题,可以用的算法多了去了,逻辑回归、决策树、SVM、XGBoost、随机森林,blahblahblah……最后用的是XGBoost,因为它很省心啊,又可以自己灵活抽样,又可以很方便地调参来防止过拟合,而且是集成学习,预测精度高,还能帮你选特征。
5、怎么防止过拟合?
很多方法了,调参啦,控制树深、树的分裂条件,叶子节点权重等,还可以自己选变量,把那些不重要的变量都筛掉。最后我的结果AUC是在0.799的样子,因为我电脑比较挫,跑不了所有的数据,只能跑一部分,不然肯定能到0.8以上,然后当季排名是15,现在大家更牛了,第一名已经到0.81+了。