数据采集:selenium爬取美团全国酒店信息(一):https://blog.csdn.net/eighttoes/article/details/87364011
数据采集:selenium爬取美团全国酒店信息(二):https://blog.csdn.net/eighttoes/article/details/87377488
数据采集:selenium爬取美团全国酒店信息(三):https://blog.csdn.net/eighttoes/article/details/87396924
现在需要爬取得城市有800个,每个城市有1-50页不等,按每个城市30页算,需要向美团发起2万4千次的请求,而美团必定会封禁IP。
面对这种情况,如果通过放慢爬取速度来处理的话很不现实,因为利用selenium来做爬虫,速度本来就已经很慢了,远远没有分析Ajax,然后请求页面来得快,这时如果再放慢爬取速度的话,那效率就低的可怕。
所以,可以通过使用代理IP来处理。(以下的代理分析,我使用的是付费代理)
现在先回头看看在第一篇当中的请求函数:
from selenium import webdriver
import time
def get_driver():
driver = webdriver.Chrome()
return driver
def get_page_source(driver, url):
driver.get(url)
##函数睡眠1秒,等待网页响应和渲染
time.sleep(1)
page_source = driver.page_source
return page_source
先把webdriver.Chrome加入代理(具体方法参考 https://blog.csdn.net/eighttoes/article/details/87404781)
from selenium import webdriver
import time
## co是chrome_options参数
from auth_proxy import co
def get_driver(co):
driver = webdriver.Chrome(chrome_options=co)
return driver
一般来说,爬虫用的是动态IP比较多。
再结合这次爬取的实际情况来看,利用动态IP来爬取面临以下3个问题:
- 动态IP有部分不能发起请求(连接不到网络)
- 部分动态IP请求速度过慢(有的甚至差不多10秒都不能接收到响应)
- 部分动态IP被美团封过。(我猜想应该是被美团列入了黑名单)
面对以上这3个问题,可以通过重新发起请求来解决(一般重新发起请求的话,动态IP就会切换成另外一个IP)
当美团认为一个IP所发起的请求有可能是爬虫的时候,会响应如下的页面
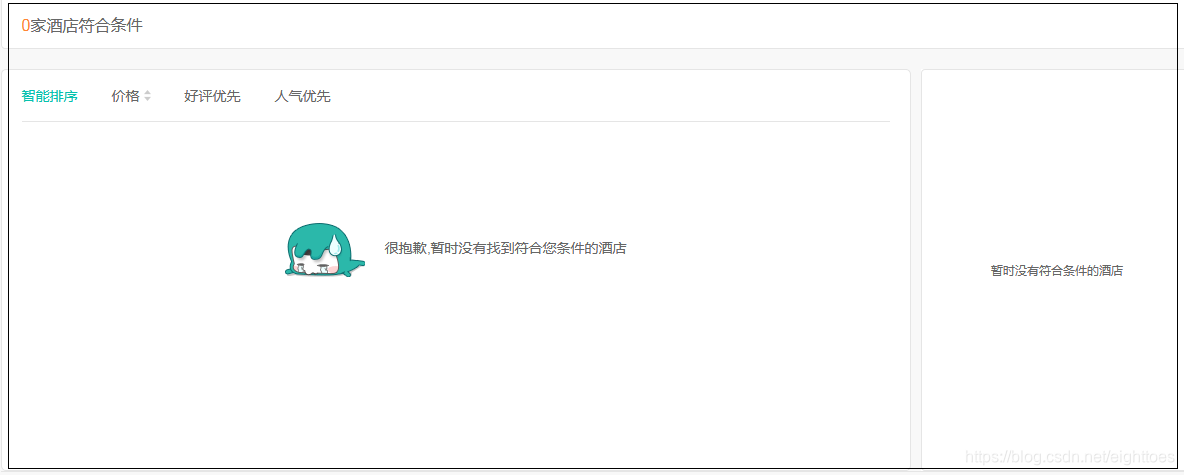
那么下面可以这样来修改请求函数
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def get_page_source(driver, url):
try:
driver.get(url)
WebDriverWait(driver, 3, 0.5).until(EC.presence_of_element_located((By.CLASS_NAME, 'page-link')))
except:
get_page_source(driver, url)
##函数睡眠1秒,等待网页响应和渲染
time.sleep(1)
page_source = driver.page_source
if '很抱歉,暂时没有找到符合您条件的酒店' in page_soure:
get_page_source(driver, url)
return page_source
通过try语句来判断IP是否能够连接,(解决问题1)
WebDriverWait是selenium当中的元素显式等待,如果超过3秒都不能定位到‘page-link’就会抛出异常。(解决问题2)
if语句判断IP是否被美团封禁过。(解决问题3)
最后通过递归的方式来处理。
接下来,结合本次爬虫的具体实现方式,又出现了另外一个问题。
下面文字描述的情况鉴于本人的语文水平有限,可能说得很抽象,先举一个例子。
现在有这样一种情况,假设爬取的城市为广州:https://hotel.meituan.com/guangzhou/ ,酒店的信息一共有51页,需要点击50次箭头按钮。

如果在点击到第30次的时候,出现了动态IP被封禁,上述重写之后的请求函数其实是不能用的。
在关于selenium爬取美团全国酒店信息(二) https://blog.csdn.net/eighttoes/article/details/87377488 当中,爬虫的翻页方式是用过点击箭头按钮实现的,当点击之后,页面的URL并没有改变。然后直接采用driver.page_source来获取网页源码。
所以上述的请求函数对于翻页功能来说是完全没有作用的,如果在某个城市爬取到一半的时候,某个动态IP是不能用的,这时,就需要把整个城市重新爬取了。
如果不想重新爬取的话,就要改变翻页的规则,并且记录到哪一页的时候发生了请求失败,然后再从该页重新发起请求。
这时一个可行的办法(缺点是脚本需要改写的地方多了很多,复杂程度会高了很多)
另一个办法就是,整个城市的所有酒店信息全部重新爬取,最后在所得数据中去重(这样爬虫脚本就不用修改),去重所花费的时间也远比网络IO耗时要短得多。
那么,现在确定下来的规则有以下3点:
- 使用代理IP来爬取
- 不改写翻页规则,如果在爬取某个城市的中途(如广州有50页,在第23页IP被封),IP被封,则整个城市的数据都重新爬取(从第一页重新开始)
- 最后在爬取完成之后对数据作去重处理
另外一点:
这里不采用动态代理IP,而是采用静态代理IP,动态代理IP出现问题的频率比静态IP高太多了。如果频频在爬取中途出现IP不能用(如广州有50页,在第23页IP被封),那么基本上整个爬虫都是废的。
静态IP面临的问题主要是,在面对美团封禁之后,直接切换就可以了。
上面说了一大堆,总结一下现在的情况:就是使用静态IP来爬取,当IP被封禁之后,切换静态IP
那么本文一开始,使用的递归的方式改写的请求函数就是多余的了(那是适用于动态IP的情况)
现在需要增加2个函数:
1.在使用某个静态IP爬取之前,检查该IP是否能用,以及是否被美团封禁了。
2.在爬取的过程中,检测静态IP是否被封,(被封之后切换IP)。
from selenium import webdriver
import time
## co是chrome_options参数
from auth_proxy import co
def get_driver(co):
driver = webdriver.Chrome(chrome_options=co)
## url是检查代理是否被美团封禁
url = 'https://hotel.meituan.com/guangzhou/'
driver.get(url)
page_source = driver.page_source
if '很抱歉,暂时没有找到符合您条件的酒店' in page_soure:
driver.quit()
get_driver(co)
return driver
然后是,在爬取过程中,检查静态IP是否被封,需要修改翻页的函数,(关于selenium爬取美团全国酒店信息(二) https://blog.csdn.net/eighttoes/article/details/87377488 )
## 翻页函数需要增加一个url参数
def click_next(driver, page_source, city, url):
## 变量n表示爬取进度
n = 1
print('正在爬取', city, '酒店信息', '第%d页' % n)
## 假如该城市只有1页的酒店数据,下面的while循环不执行
if 'disabled next' in page_source:
flag = False
else:
flag = True
while flag:
next_elem = driver.find_element_by_xpath('//li[@class=" next"]/a')
next_elem.click()
##睡眠一秒,等待下一页加载
time.sleep(1)
page_source = driver.page_source
##在这里检测IP是否被封
if '很抱歉,暂时没有找到符合您条件的酒店' in page_soure:
driver.quit()
print('IP被封,' city, '重新爬取')
## 如果爬虫被封,就重新爬取该城市的所有酒店信息
return spider(city, url)
xhtml = get_xhtml(page_source)
datas = parse_datas(xhtml, city)
save_datas(datas)
n += 1
print('正在爬取', city, '酒店信息', '第%d页' % n)
##这个是判定条件,判断时候还存在下一页
if 'disabled next' in page_source:
break
print(city, '爬取完成', '共%d页' % n)
driver.quit()
至此,现在整个爬虫就完成了。