数据采集:selenium爬取美团全国酒店信息(一):https://blog.csdn.net/eighttoes/article/details/87364011
数据采集:selenium爬取美团全国酒店信息(三):https://blog.csdn.net/eighttoes/article/details/87396924
数据采集:selenium爬取美团全国酒店信息(四)使用代理:https://blog.csdn.net/eighttoes/article/details/87408709
接着上一篇,现在开始尝试翻页的操作,把一整个城市的酒店信息爬取下来。
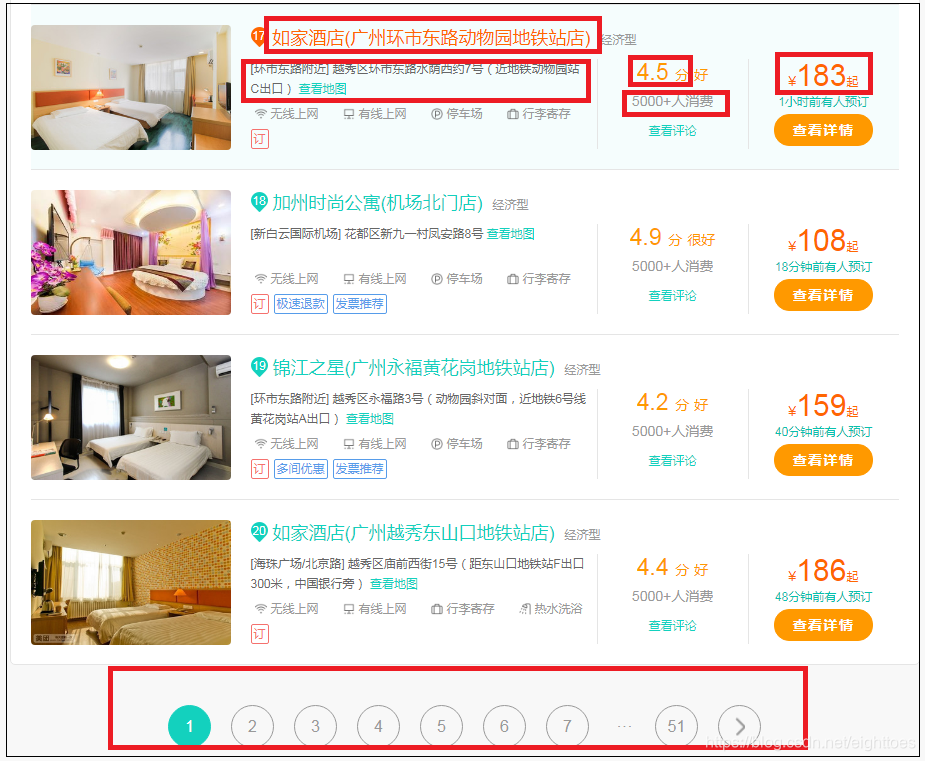
一边翻页一边观察URL,翻页的方式有两个。
一是点击下面的数字按钮

另一个是最右边的箭头按钮

通过不断的点击,会发现,美团的URL根本不会发生变化,注意观察下图红色方框这里,浏览器不能进行前进或者后退的操作,URL也没用变化,这种情况下,首先想到的解决办法是利用selenium.Chrome中的模拟点击来获取下一页。

这里通过点击右边的箭头按钮来获取下一页
next_elem = driver.find_element_by_xpath('//li[@class=" next"]/a')
next_elem.click()
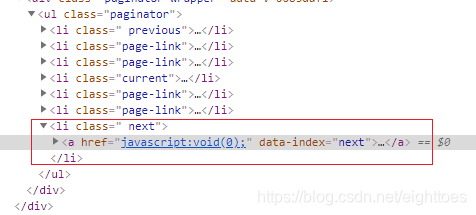
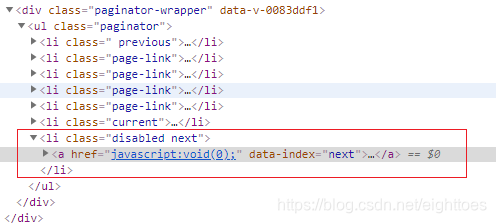
当翻到最后一页的时候,最后一个 <li 标签中的class属性会多了一个disabled,该标签同时拥有了两个属性disabled和next
所有,click_next函数增加一个判定是否为最后一页的条件
if 'disabled next' in page_source:
## 伪代码 stop find next page element
pass
结合上一篇博文,现在为爬虫增加一个翻页功能,代码如下:
if __name__ == '__main__':
city = '富顺'
url = 'https://hotel.meituan.com/fushunxian/'
##打开浏览器
driver = get_driver()
##爬取该城市的第一页酒店数据
page_source = get_page_source(driver, url)
xhtml = get_xhtml(page_source)
datas = parse_datas(xhtml ,city)
save_datas(datas)
## 假如该城市只有1页的酒店数据,下面的while循环不执行
if 'disabled next' in page_source:
flag = False
else:
flag = True
while flag:
next_elem = driver.find_element_by_xpath('//li[@class=" next"]/a')
next_elem.click()
##睡眠一秒,等待下一页加载
time.sleep(1)
page_source = driver.page_source
xhtml = get_xhtml(page_source)
datas = parse_datas(xhtml ,city)
save_datas(datas)
##这个是判定条件,判断时候还存在下一页
if 'disabled next' in page_source:
break
##关闭浏览器
driver.quit()
把翻页功能封装在一个函数里面,(并且增加一个局部变量n,显示爬取进度)函数名为click_next
def click_next(driver, page_source, city):
## 变量n表示爬取进度
n = 1
print('正在爬取', city, '酒店信息', '第%d页' % n)
## 假如该城市只有1页的酒店数据,下面的while循环不执行
if 'disabled next' in page_source:
flag = False
else:
flag = True
while flag:
next_elem = driver.find_element_by_xpath('//li[@class=" next"]/a')
next_elem.click()
##睡眠一秒,等待下一页加载
time.sleep(1)
page_source = driver.page_source
xhtml = get_xhtml(page_source)
datas = parse_datas(xhtml, city)
save_datas(datas)
n += 1
print('正在爬取', city, '酒店信息', '第%d页' % n)
##这个是判定条件,判断时候还存在下一页
if 'disabled next' in page_source:
break
print(city, '爬取完成', '共%d页' % n)
driver.quit()
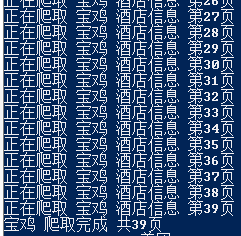


现在这个翻页功能看起来很正常,大部分的城市都能成功爬取。
但是,当爬取一些酒店比较多的城市的时候,譬如广州,成都,北京,这个click_next函数就出现问题了,它会陷入一个死循环中,不会退出,而美团网站会返回这样一个东西,如下图。
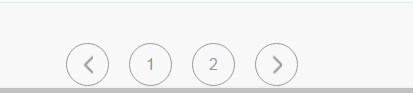
明明到了最后一页,本不应该出现的箭头按钮,又出现了。再查看一下HTML源码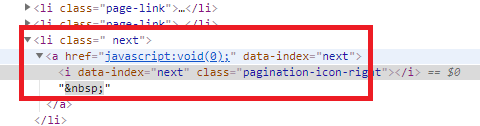
也就是说,之前的 if ‘disabled next’ in page_source: 这个判断条件不起作用了。
后来我把美团所有的热门城市翻了一遍,
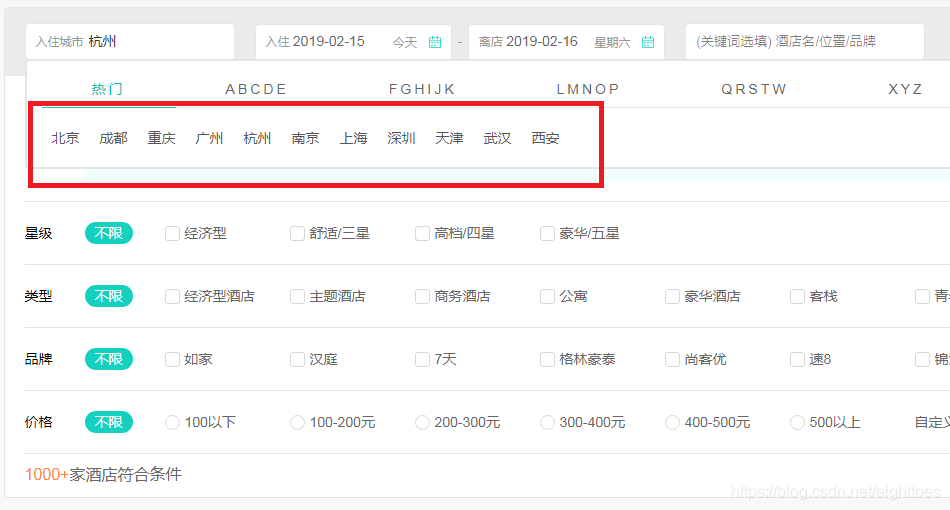
发现美团最多也只有显示51页,也就是说,更多的酒店,美团也不会显示出来,或者说可能根据客户的筛选条件才会显示出来,如杭州所有的3星级酒店这样。
既然这样,也就是说,在不分类酒店的情况下,通过点击翻页按钮,最多只能翻到51页。

翻页函数click_next现在需要再增加一个判定条件:超过51页,退出while循环。
这时可以利用刚刚增加的局部变量n
下面代码是翻页函数click_next的完整代码
def click_next(driver, page_source, city):
## 变量n表示爬取进度
n = 1
print('正在爬取', city, '酒店信息', '第%d页' % n)
## 假如该城市只有1页的酒店数据,下面的while循环不执行
if 'disabled next' in page_source:
flag = False
else:
flag = True
while flag:
next_elem = driver.find_element_by_xpath('//li[@class=" next"]/a')
next_elem.click()
##睡眠一秒,等待下一页加载
time.sleep(1)
page_source = driver.page_source
xhtml = get_xhtml(page_source)
datas = parse_datas(xhtml, city)
save_datas(datas)
n += 1
print('正在爬取', city, '酒店信息', '第%d页' % n)
##这个是判定条件,判断时候还存在下一页
if 'disabled next' in page_source:
break
elif n >= 51:
break
print(city, '爬取完成', '共%d页' % n)
driver.quit()
if __name__ == '__main__':
city = '广州'
url = 'https://hotel.meituan.com/guangzhou/'
##打开浏览器
driver = get_driver()
##爬取该城市的第一页酒店数据
page_source = get_page_source(driver, url)
xhtml = get_xhtml(page_source)
datas = parse_datas(xhtml ,city)
save_datas(datas)
## 翻页
click_next(driver, page_source, city)

现在单独每一个城市的酒店信息都能爬取进来了。
再把整个爬取功能封装起来
city = '富顺'
url = 'https://hotel.meituan.com/fushunxian/'
def spider(city, url):
##打开浏览器
driver = get_driver()
##爬取该城市的第一页酒店数据
page_source = get_page_source(driver, url)
xhtml = get_xhtml(page_source)
datas = parse_datas(xhtml ,city)
save_datas(datas)
click_next(driver, page_source, city)