数据采集:selenium爬取美团全国酒店信息(二):https://blog.csdn.net/eighttoes/article/details/87377488
数据采集:selenium爬取美团全国酒店信息(三):https://blog.csdn.net/eighttoes/article/details/87396924
数据采集:selenium爬取美团全国酒店信息(四)使用代理:https://blog.csdn.net/eighttoes/article/details/87408709
需求分析:
目标URL: https://hotel.meituan.com/guangzhou/
目标是搜集美团上全国所有城市就酒店基本信息。具体的信息字段有如图红色方框内的5个。
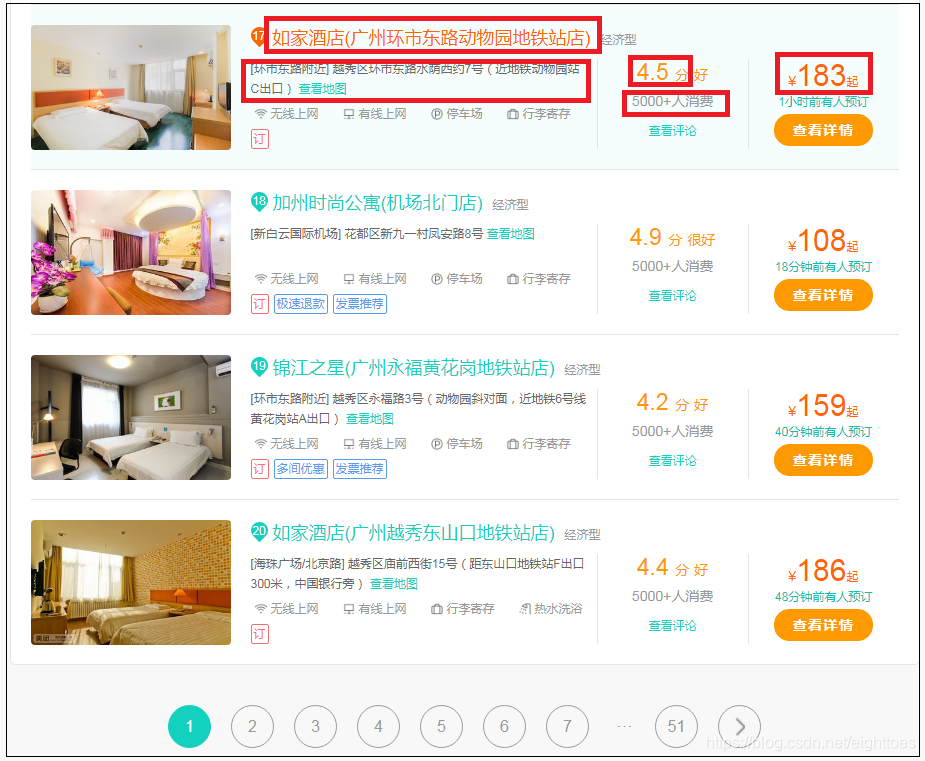
如图五个字段,另外加上酒店所属城市,例如“广州”,一共六个字段:
- city ##酒店所属城市
- hotel ##酒店名称
- price ##价格
- grade ##评分
- consumer ##消费人数
- address ##地址
美团网站的加载方式为动态加载,这次不分析其加载参数,直接使用selenium自动化工具,利用chrome渲染页面,获取渲染后的HTML源码,从中解析字段数据。
首先,获取一个driver
from selenium import webdriver
def get_driver():
driver = webdriver.Chrome()
return driver
获取浏览器渲染后的源码
import time
def get_page_source(driver, url):
driver.get(url)
##函数睡眠1秒,等待网页响应和渲染
time.sleep(1)
page_source = driver.page_source
return page_source
解析库使用lxml,
获取hotel,price,grade,consumer,address五个字段,因为后续需要爬取全国所有的城市,所以city字段作为参数,自行传入
from lxml import etree
def get_xhtml(page_source):
xhtml = etree.HTML(page_source)
return xhtml
## 这是一个生成器函数
def parse_datas(xhtml, city):
datas = {}
items = xhtml.xpath('//article[@class="poi-item"]')
for item in items:
datas['city'] = city
datas['hotel'] = item.xpath('.//a[@class="poi-title"]/text()')[0].strip()
datas['price'] = item.xpath('.//div[@class="poi-price"]/em/text()')[0].strip()
datas['grade'] = item.xpath('.//div[@class="poi-grade"]/text()')[0].strip()
## 部分酒店没有消费人数的信息,如果没有,返回空字符串
try:
datas['consumer'] = item.xpath('.//div[@class="poi-buy-num"]/text()')[0].strip()
except IndexError:
datas['consumer'] = ''
datas['address'] = item.xpath('.//div[@class="poi-address"]/text()')[0].strip()
yield datas
然后保存数据到csv文件中
import csv
def save_datas(datas):
with open('hotel.csv', 'a', encoding='GB18030', newline='') as c:
fieldnames = ['city', 'hotel', 'price', 'grade', 'consumer', 'address']
writer = csv.DictWriter(c, fieldnames=fieldnames)
for data in datas:
writer.writerow(data)
现在运行脚本,得到广州市,第一页的酒店信息。
if __name__ == '__main__':
city = '广州'
url = 'https://hotel.meituan.com/guangzhou/'
driver = get_driver()
page_source = get_page_source(driver, url)
xhtml = get_xhtml(page_source)
datas = parse_datas(xhtml ,city)
save_datas(datas)
driver.quit()
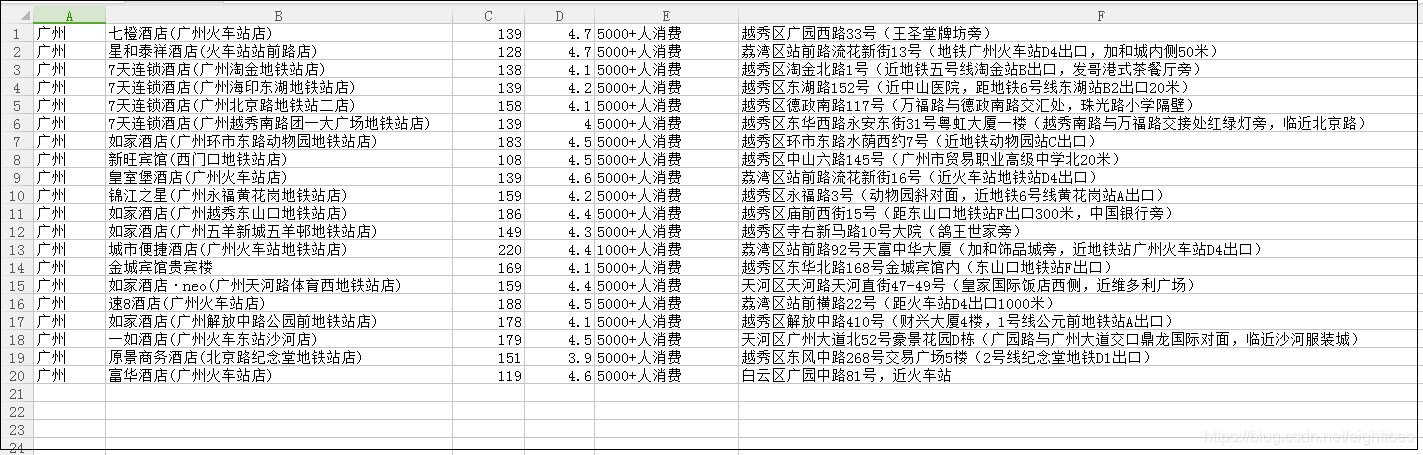
暂时一切看起来都很顺利。
但是其实中间有很多坑。例如,美团会封IP,美团响应的页面不规律,长时间的爬取浏览器会崩溃等等。
譬如,请看上面的parse_datas函数
try:
datas[‘consumer’] = item.xpath(’.//div[@class=“poi-buy-num”]/text()’)[0].strip()
except IndexError:
datas[‘consumer’] = ‘’
如果不是大量爬取,根本发现不了美团的这个消费人数信息标签(’.//div[@class=“poi-buy-num”)
有可能会为空,更加保险的方法,应该是为每一个字段变量都加上try except语句。
def parse_datas(xhtml, city):
datas = {}
items = xhtml.xpath('//article[@class="poi-item"]')
for item in items:
datas['city'] = city
try:
datas['hotel'] = item.xpath('.//a[@class="poi-title"]/text()')[0].strip()
except IndexError:
datas['hotel'] = ''
try:
datas['price'] = item.xpath('.//div[@class="poi-price"]/em/text()')[0].strip()
except IndexError:
datas['price'] = ''
try:
datas['grade'] = item.xpath('.//div[@class="poi-grade"]/text()')[0].strip()
except IndexError:
datas['grade'] = ''
## 部分酒店没有消费人数的信息,如果没有,返回空字符串
try:
datas['consumer'] = item.xpath('.//div[@class="poi-buy-num"]/text()')[0].strip()
except IndexError:
datas['consumer'] = ''
try:
datas['address'] = item.xpath('.//div[@class="poi-address"]/text()')[0].strip()
except IndexError:
datas['address'] = ''
yield datas
为每一个字段都加上了try语句,现在这个函数就变得很臃肿了。但是我水平有限,如果有更好的写法,请告诉我。