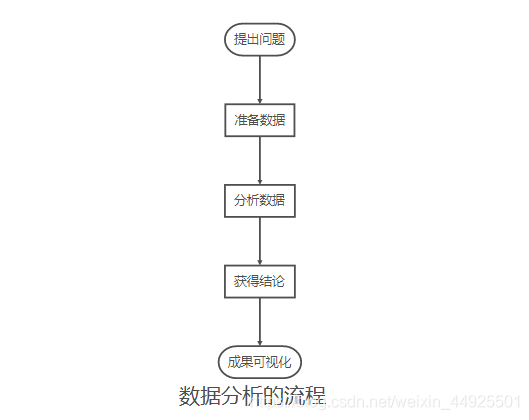
数据分析
内容多且杂,我按照自己理解的逻辑,写了三个思维导图,就在每一部分之后
一、基础概念及环境
1. 数据分析概念
- 数据分析是Python数据科学的基础,也是机器学习课程的基础
- 数据分析: 大量的数据进行分析,帮助人们作出判断,以便采取适当行动。
2. anaconda
2.3 安装
- 搜索“anaconda”镜像源
- 下载到Linux主机。可以使用wget命令下载。
- chomd +x 给下载的sh文件可执行权限,然后执行
- 一路输入yes
- 关闭终端,再打开一个新终端即生效
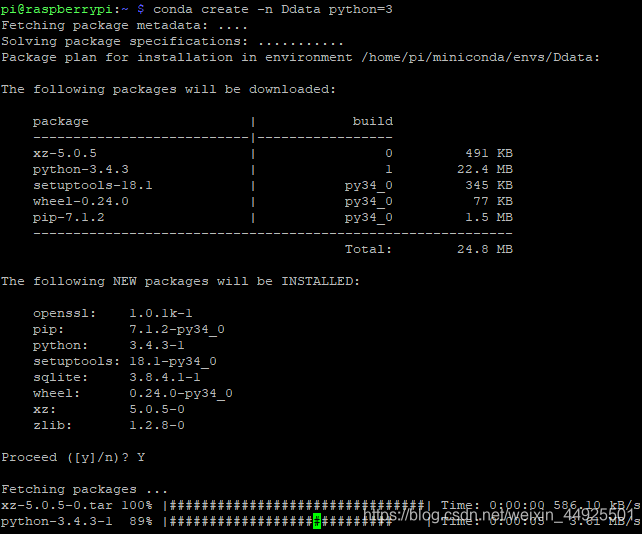
2.2 基本操作
- 创建环境:
conda create -n 取的名字 python=3
确定后,输入Y安装
- 激活环境:
source activate 环境名
- 停用环境:
source deactivate
- 安装模块:
conda install 模块名
二、matplotlib
1. 简介
- 将数据进行可视化 ,更直观
- 使数据更客观 ,更具说服力
- matplotlib: 最流行的Python底层绘图库,注意做数据可视化图表 ,名字取材于MATLAB,也是模仿其构建的。
2. 基本要点
- axis: 指x或y这种坐标轴。
- 坐标: 图上的每一个点就是一个坐标。
- 安装:(pip3 install matplotlib安装会报错。请使用以下命令。)
sudo apt-get install python3-matplotlib
3. 使用方法
- 以折线图为例
3.1 最简单形式
- 导入模块
- x,y都要是可迭代对象。并且长度相同。
- 将x、y传入plot
- 展示图形(会蹦出一个框,当然,远程看不了)
# coding=utf-8
from matplotlib import pyplot as plt
x = [0, 2, 4, 6]
y = [20, 15, 14, 13]
plt.plot(x, y) # 传入x,y通过plot绘制折线图
plt.show() # 在执行时,展示图形
- 如果想保存图片,控制刻度怎么办?
3.2 升级形式
- 我们想保存图片,就需要创建一个图形实例。figsize接收一个元组,分别是宽和高。dpi决定清晰度,意思是每英寸点个数。在绘图之后,保存即可。
- 控制刻度。
# coding=utf-8
from matplotlib import pyplot as plt
# 创建一个图形实例,后续对其进行设置操作
fig = plt.figure(figsize=(20,10), dpi=80) # (宽,高),每英寸点个数
x = range(2, 26, 2)
y = [20, 15, 14, 13, 8, 16, 14, 14, 13, 11, 10, 15]
# 绘图
plt.plot(x, y)
# 设置x轴刻度
# xtick_labels = [0.5*i for i in range(4, 49, 1) # range不接受小数步长
plt.xticks(range(2, 25, 1)) # 设置区间为2~25,步长为1
# 设置y轴刻度
plt.yticks(range(min(y), max(y)+1, 3))
# 保存
plt.savefig("./pic/t1.png") # 可以保存为svg矢量图格式
# 展示
# plt.show()
- 刻度想要使用字符串怎么办?字符串挤在一起怎么办?怎么使用中文?
3.3 刻度使用字符串
- 刻度传入一个参数,只能使用数字。传入两个参数,可以使用字符串,要一一对应。
- 刻度挤在一起,可以选择用rotation参数旋转。
- 中文:在终端用fc-list可以查看Linux中支持的字体。在用fc-list :lang=zh可以看含有的中文字体
- 改变字体有两种方式。方式2更可取。字体的地址,最好用绝对字体。
# coding=utf-8
from matplotlib import pyplot as plt
import random
from matplotlib import font_manager
# 设置字体,方式1
# font = {"family" : "MicroSoft YaHei",
# "weight" : "bold",
# "size" : "larger"}
# matplotlib.rc("font", **font)
# 设置字体,方式2(推荐)
my_font = font_manager.FontProperties(fname="/home/pi/Font/simsun.ttc")
# 创建一个图形实例,后续对其进行设置操作
fig = plt.figure(figsize=(30,25), dpi=120) # (宽,高),每英寸点个数
x = range(1, 121)
# 描绘一个增长的股票
y = [int(random.randint(15, 90)*0.03*i) for i in range(1, 121)]
# 绘图
plt.plot(x, y)
# 调整x轴刻度
_x = list(x) # 可以直接用x。转换为列表是为了方便控制步长。
_xtick_labels = ["10点{}分".format(i) for i in range(60)]
_xtick_labels += ["14点{}分".format(i) for i in range(60)]
# 一个参数时,只能传数字。要传入字符串,需要让两个参数一一对应
plt.xticks(_x[::5], _xtick_labels[::5], rotation=315, fontproperties=my_font) # rotation决定旋转的度数
# 设置y轴刻度
plt.yticks(range(min(y), max(y)+1, 7))
# 保存
plt.savefig("./pic/t2.png") # 可以保存为svg矢量图格式
# 展示
# plt.show()
3.4 添加描述信息
- 绘制网格:
plt.grid()
grid可以接受参数。
alpha=0.4 ==>设置透明度为0.4(完全透明为0,完全不透明为1,缺省为1)
- 添加描述信息:
plt.xlabel("时间", fontproperties=my_font)
plt.ylabel("股价 (单位¥)", fontproperties=my_font)
plt.title("两个时间段的股价变化", fontproperties=my_font)
3.5 同图表绘制多折线
- 绘图两次即可
# 绘图
plt.plot(x, y1)
plt.plot(x, y2)
- 给曲线添加图例(区别曲线) 用label参数,还要添加plt.legend()
# 绘图
plt.plot(x, y1, label="星期三")
plt.plot(x, y2, label="星期五")
plt.legend(prop=my_font) # 注意是prop,其它地方用字体都是fontproperties参数
图例默认在最合适的位置。要改变位置使用loc参数,可以传入字符串,也可以传入数字0~10
| best | upper right | upper left | lower left | lower right | right |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 |
| center left | center right | lower center | upper center | center | |
| 6 | 7 | 8 | 9 | 10 |
- 绘图:颜色参数color,传入颜色单词或16进制值
- 绘图:线型参数linestyle,传入字符串(网格也有这个参数哦)
| - | – | -. | : | ‘’ |
|---|---|---|---|---|
| 实线 | 虚线 | 点划线 | 点虚线 | 留空 |
- 线条粗细:linewidth=5
- 线条透明度:alpha=0.5
4. 应用场景
- 折线图: 变化。显示数据变化趋势。
- 直方图: 统计(绘制连续性的数据)展示一组或多组数据分布情况
- 条形图: 统计(绘制离散型的数据)能够一眼看出各个数据的大小,比较数据之间的差别。频率统计。
- 散点图: 分布规律(判断变量之间是否存在数量关联趋势,展示离群点)
- 其它问题:
plt.hist()直方图==>错位?错位是因为不能被整除。
可以用条形图,设置width(width默认0.8)即可。
5. 更多
百度Echarts
plotly可视化工具中的github。同时兼容matplotlib和pandas
seaborn比matplotlib简单,但没有交互效果

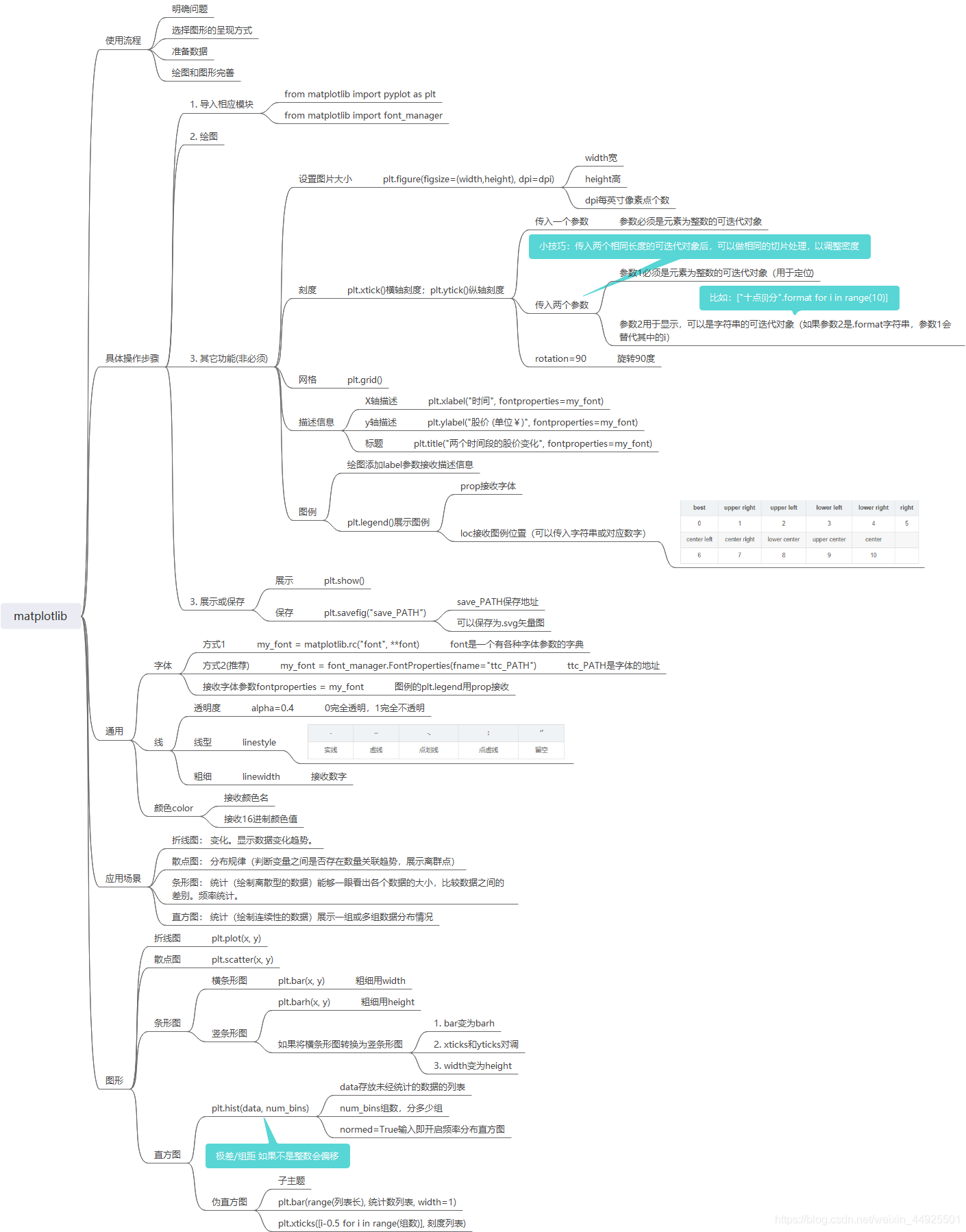
6. 思维导图
三、numpy
- Python中的一个科学计算 基础库。重在数值计算 。
1. 创建数组&数据类型
- 创建数组
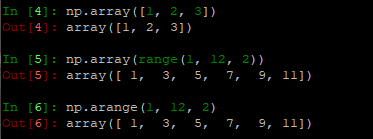
import numpy as np
# 以下都是一维数组
np.array([5])
np.array(range(1, 12, 2))
np.arange(1, 12, 2)
- 数据类型
# 指定创建的数组的数据类型
t1 = np.array([1, 0], dtype=np.bool)
t1 = np.array([1, 0], dtype="?")
# 查看t1数组里的数据类型
t1.dtype
# 修改数据类型
t2 = t1.astype("i1")
# 修改小数位数
t3 = np.array([0.233333, 0.666666])
t4 = np.round(t3, 2) # [0.23, 0.67],和Python中round方法类似
| 类型 | 类型代码 | 说明 |
|---|---|---|
| int8 | i1 | 有符号8位(1字节)整形 |
| uint8 | u1 | 无符号8位(1字节)整形 |
| int16/32/64 | i2/i3/i4 | 以此类推 |
| float16 | f2 | 半精度浮点数 |
| float32 | f4或f | 标准单精度浮点数。兼容C的float |
| float64 | f8或d | 标准的双精度浮点数。兼容C的double和Python的float |
| float128 | f16或g | 扩展精度浮点数 |
| complex256 | c32 | 复数 |
| bool | ? | 布尔值 |
2. 数组的形状
- 一维数组
array([0, 1, 2, 3, 4, 5])
- 二维数组
array([
[1, 2, 3],
[4, 5, 6]
])
- 三维数组
array([
[
[1, 2, 3],
[4, 5, 6]
],
[6, 5, 4],
[3, 2, 1]
])
- 让t1接收上面那个一维数组,t2接收2维,t3接收3维。
- 形状 shape可以知道数组的形状。
t1.shape ==> (5,)
t2.shape ==> (2,3)
t3.shape ==> (2,3,3)
- 改变形状有返回值,不会改变数组本身。
t4 = np.arange(12)
t4.reshape((3, 4)) ==>array([
[0, 1, 2, 3],
[4, 5, 6, 7],
[8, 9, 10, 11]
])
- 展开(变1维) 有返回值,不会改变数组本身。
t4.flatten()
3. 数组计算
3.1 数组计算(与数字)
- 做加减乘除法会让每一个值都加减乘除上这个数(广播机制)
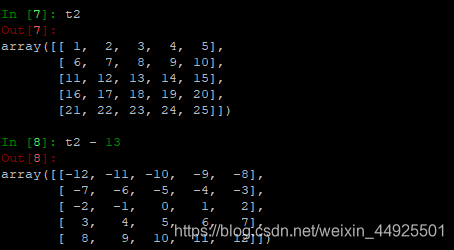
- 除0
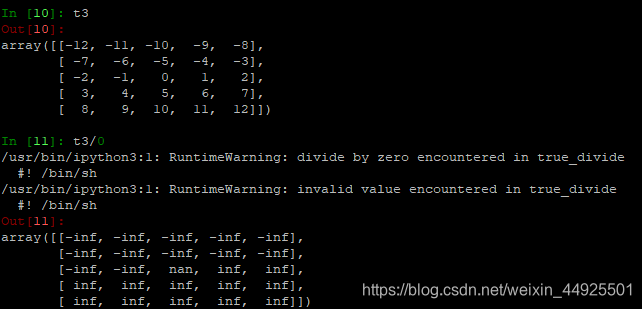
nan,全称not a number,表示不是一个数字,是一种特殊的数据类型。
inf, 全称infinity表示无穷。
任何非零数除以零=无穷。0除以0不是一个数字。
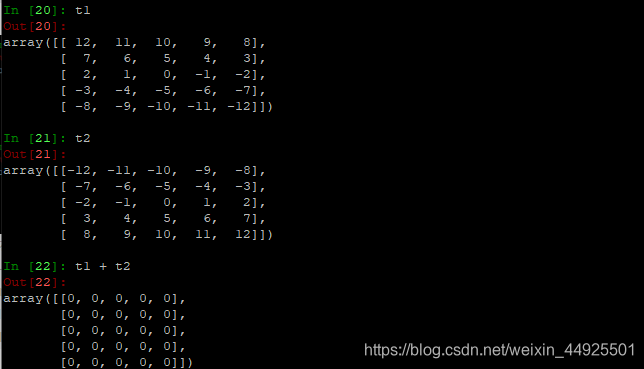
3.2 数组计算(与数组)
- 加减乘除都是对应位置进行加减乘除(形状完全相同时)
- 加减乘除都是对应位置进行加减乘除(某一维度形状相同时)
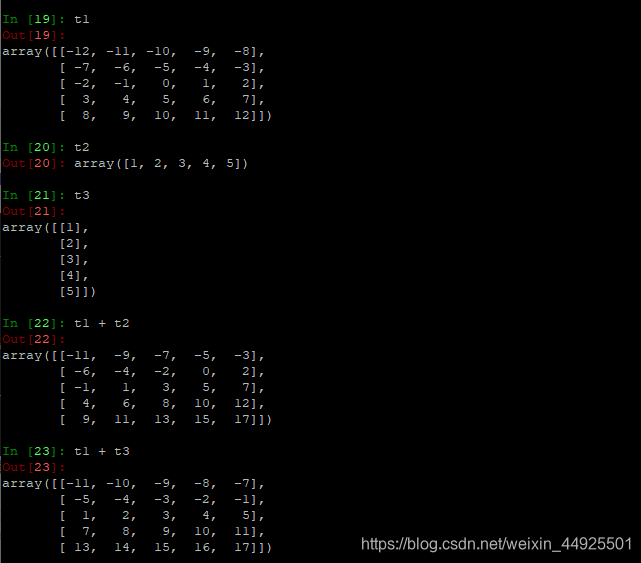
会发现同一维度进行计算
- 广播原则: 如果两个数组的后缘维度(即从末尾开始算的维度) 的轴长度相符,或其中一方长度是1 ,则认为他们是广播兼容的。广播会在缺失和(或)长度为1的维度上进行。
shape为(3, 3, 2)能与(3, 2)进行计算。也能和(3, 1)进行计算。
二维的很好理解。三维的,把第一个维度看作区块,就好理解了。可以参考下面轴图。
4. 轴
- 在numpy中可以理解为方向。一维数组只有一个0轴。二维数组有0轴和1轴。以此类推。(我画的多维维数组轴和一般画法不一致,因为我的理解是最前面的维度最高。所以axis=0应该是最高维度轴。)
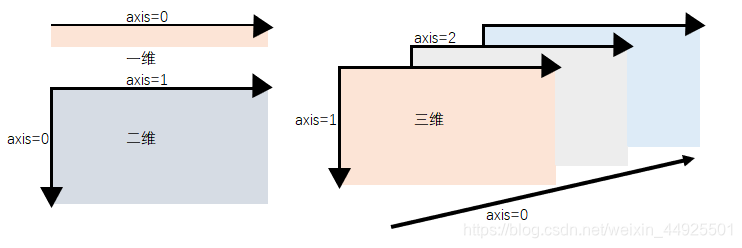
- 有了轴的概念后,计算会更加方便。比如计算平均值,必须指定是哪个方向上的平均值。
5. numpy从文件读取数据
np.loadtxt(frame, dtype=np.float, delimiter=None, skiprows=0, usecols=None, unpack=False)
| 参数 | 含义 |
|---|---|
| frame | 文件、字符串或产生器的路径。可以是.gz或bz2压缩文件 |
| dtype | 数据类型,可选。默认np.float |
| delimiter | 分隔字符串,默认是任何空格 |
| skiprows | 跳过前X行 |
| usecols | 读取指定列 |
| unpack | 表示转置。True:读入属性将分别写入不同数组变量。False:只写入一个数组变量,默认False。 |
DEMO
- 准备四个CSV文件。
CSV中的数据都是以逗号分隔开的。
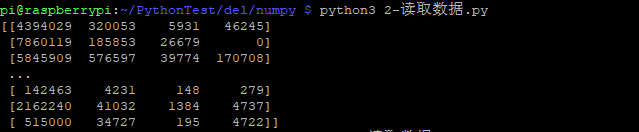
- 看一个最基础示例:
import numpy as np
file_PATH_1 = "./data_1.csv"
datas_1 = np.loadtxt(file_PATH_1, dtype="int", delimiter=",", skiprows=1)
print(datas_1)
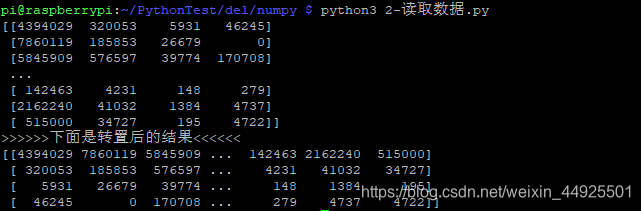
- 看一下转置的效果:
import numpy as np
file_PATH_1 = "./data_1.csv"
datas_1 = np.loadtxt(file_PATH_1, dtype="int", delimiter=",", skiprows=1)
datas_1_u = np.loadtxt(file_PATH_1, dtype="int", delimiter=",", skiprows=1, unpack=True)
print(datas_1)
print(">>>>>>下面是转置后的结果<<<<<<")
print(datas_1_u)
- 转置有非常多的方法:
t2 = t1.transpose()
t2 = t1.T
t2 = t2.swapaxes(1, 0) # 把0轴和1轴交换
6. numpy索引和切片
6.1 索引与切片的一般形式
- 取行的方法: (注意第三个特殊用法)
# 取datas第1行
print("-" * 50)
print(datas_1[0])
# 取第1行-->第6行
print("-" * 50)
print(datas_1[0:6])
# 取1、5、7行
print("-" * 50)
print(datas_1[[0, 4, 6]]) # 这是个特殊用法
- 通用方法: datas_1[axis0, axis1] axis0和axis1都可以进行切片等操作
- 取列、行和列及某处值:
# 取第1列
print("-" * 50)
print(datas_1[:, 0])
# 取前5行,1、3列
print("-" * 50)
print(datas_1[:5, [0, 2]])
- 取一个特定值:
返回一个numpy.int值
# 取3行,4列
print("-" * 50)
print(datas_1[2, 3])
print("它的类型是%s" % type(datas_1[2, 3])) # numpy.int型
- 取多个特定点:
行和列一一对应,如果是二维的,返回一个一维数组
# 取(1,2)和(3,4)点
print("-" * 50)
print(datas_1[[0,2], [1,3]])
6.2 numpy索引进阶
- 修改某一处的值使用赋值语句: (可以让一堆数据等于同一个值)
# 修改(2, 3)的值
print("-" * 50)
print(datas_1[:3]) # 打印一下原始数组前三行
print()
datas_1[:3][1,2] = 1314 # 使用赋值语句修改
print(datas_1[:3]) # 再次打印,查看结果
# 修改(1, 1)、(1, 3)和后两行
print("-" * 50)
print(datas_1[:3]) # 打印一下原始数组前三行
print()
datas_1[:3][[0,0],[0,2]] = 520 # 使用赋值语句修改
datas_1[:3][1:] = 520 # 使用赋值语句修改
print(datas_1[:3]) # 再次打印,查看结果
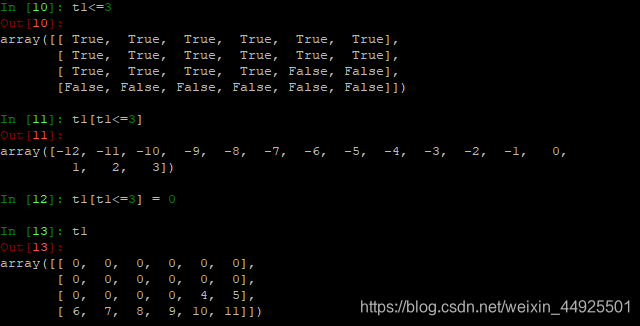
- numpy中布尔索引:
(怎样把满足条件的值替换?)
在交互式解释器中试验,发现是布尔值。
把布尔值列表套进去,发现是为True的部分
- numpy中三目运算符:
(然后同时执行if和else?)
np.where()用法同Excel中if。直接返回,不会修改原数组。
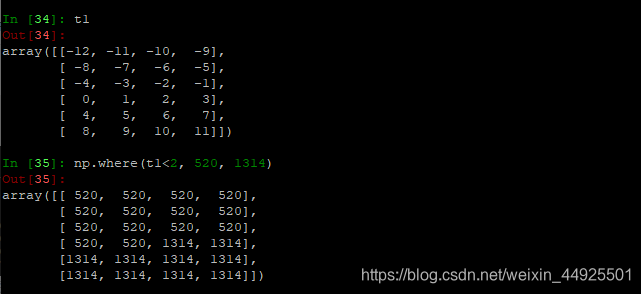
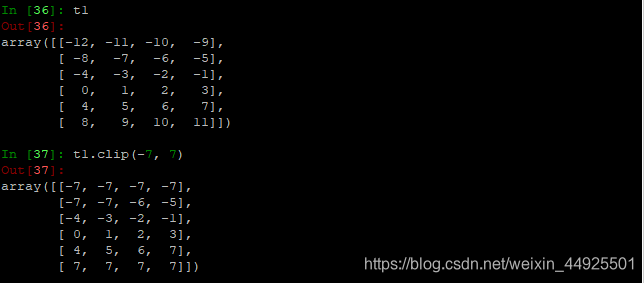
- clip剪切: (将大于某数的,全替换为此数,将小于某数的,全部替换为此数。保持中间的数不变。)
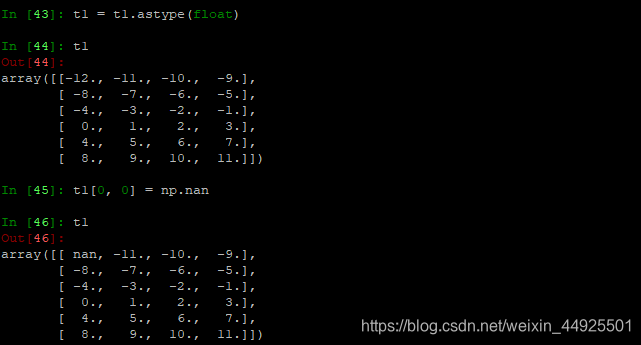
- 修改值为nan:
nan属于非整形,如果原数组中都是整数,那么需要先将数据类型转化为float(使用t1.astype(float)方法),才可以使用赋值语句,使其等于np.nan。

7. 数组拼接与拆分
7.1 数组拼接
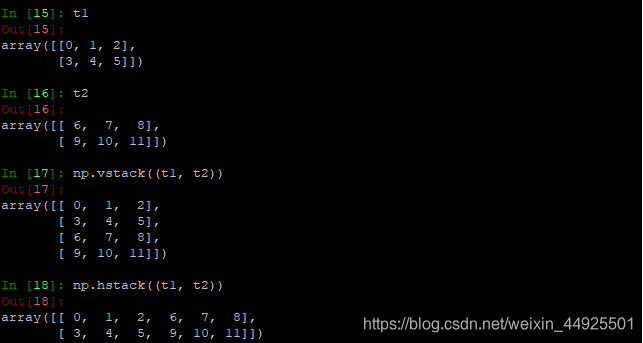
- np.vstack((,))竖直拼接。
- np.hstack((,))水平拼接。
7.2 数组分割
- np.vsplit()竖直方向的均等分割。
- np.hsplit()水平方向的均等分割。
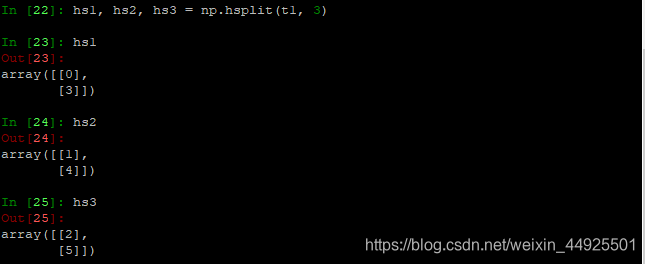

7.3 交换行列
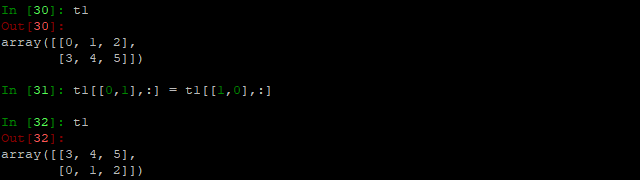
- 交换行:
原理类似于:
a, b = 1, 0 # 交换a, b的值
b, a = a, b

DEMO:将多个文件中数据组合
- np.zeros((形状)).astype(int) 生成一块数组,值为0
- np.ones((形状 )).astype(int) 生成一块数组,值为1
- 形状可以理解为行列
- 需求: 有两个文件的数据,需要添加一列,来自于第一个文件的,该数为0,。来自第二个文件的,该数为1。
import numpy as np
# 构造来自第一个文件数据
file_PATH_1 = "./data_1.csv"
datas_1 = np.loadtxt(file_PATH_1, dtype="int", delimiter=",", skiprows=0)
add_v_1 = np.zeros((datas_1.shape[0],1)) # 生成一列0的数组
final_data_1 = np.hstack((add_v_1, datas_1)).astype("int") # 不转会是科学计算法
# 构造来自第二个文件数据
file_PATH_2 = "./data_2.csv"
datas_2 = np.loadtxt(file_PATH_2, dtype="int", delimiter=",", skiprows=0)
add_v_2 = np.ones((datas_2.shape[0],1)) # 生成一列0的数组
final_data_2 = np.hstack((add_v_2, datas_2)).astype("int") # 不转会是科学计算法
# >>>>>>>>>>组合起来<<<<<<<<<<
final_data = np.vstack((final_data_1, final_data_2))
print(final_data)
8. 更多
8.1 正方形数组、某条轴计算
- 创建一个对象为1的正方形数组(方阵):
np.eye(3)

8.2 随机值
- numpy中有许多随机数方法
| 方法 | 功能 |
|---|---|
| .rand(d0, d1, …dn) | 创建d0~dn维度的均匀分布的随机数数组(0~1之间,浮点数) |
| .randn(d0, d1, …dn) | 创建d0~dn维度的标准正态分布随机数数组(0~1之间,浮点数,平均数0,标准差1) |
| .randint(low,high,(shape)) | 给定上下限范围选取随机数。形状shape |
| .uniform(low,high,(size)) | 和上面的那个一样,不过产生的是浮点数 |
| .normal(loc, scale, (size)) | 从指定正态分布中随机抽取样本,分布中心是loc(概率分布均值),标准差是scale,形状是size |
| .seed(s) | 随机数种子,s是给定的种子值(放一个数)。(因为计算机是伪随机,所以在使用同一个种子后,再执行以上的任一随机方法可以得到相同的随机数) |
seed和randint是最常用的。
8.3 copy和view
- a = b 完全不复制,a和b指向同一个内存空间。是浅拷贝。
- a = b[:] 视图 的操作,一种切片,会创建新的对象a,但是a的数据完全由b保管 ,两者数据变化一致。也是一种浅拷贝。
- a = b.copy() 深拷贝。
8.4 nan和inf
- nan表示不是一个数字
- 出现nan的两种情况:
- 读取数据有缺失时。
- 当做了一个不合适的计算时。
- ifn表示无穷。除0,python中会直接报错,数组会显示inf。
- nan和inf都是float类型的。
8.4.1 nan
- 两个nan不相等
利用这一个特性。可以产生特殊用途
t1 != t1
所有地方都是False。而nan因为不相等,所以它所在的位置会变为True。
np.count_nonzero(t1)可以统计出t1中非0的个数。False会被识别为零,所以np.count_nonzero(t1 != t1)可以计算出nan的个数。
t1 != t1有一个代替的方法:np.isnan(t1)
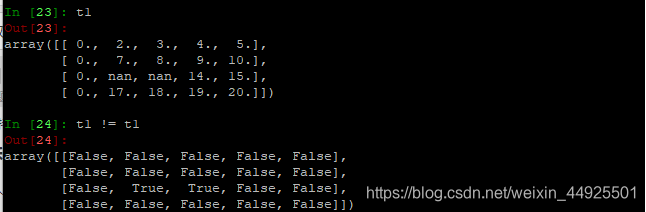
- nan和任何值进行计算都为nan
可以
t1[isnan(t1)] = 0来进行一个赋值的操作,不然很多计算无法进行
但是能用0吗?求和是无影响,求积应该用1,求平均值就应该先算出其它不为nan的数据的平均值赋予它。也可以替换为中值,或干脆删了那一行。

8.4.2 常用统计方法:
8.4.2.1 以max和min来说明轴和全体的计算方法:
t1.max()
t1.min()

- 行(列)方向上最大(最小):
返回一个数组
t1.max(axis=0) # 0轴上最大值
t1.min(axis=1) # 1轴上最小值

- 获取最大值(最小值的位置):
t1.argmax(axis=0)
t1.argmin(axis=1)
np.argmax(t1, axis=0) # 效果同上,写法不同

8.4.2.2 更多统计方法
t1.sum()求和t1.mean()求均值np.median( t1 )求中值np.ptp(t)极差t.std()标准差
8.4.3 替换nan
- 怎样把nan替换为平均数之类的数呢?
- 准备一个数组t1
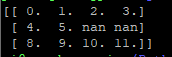
import numpy as np
def del_nan(t1):
for i in range(t1.shape[1]): # 遍历每一列
temp_col = t1[:,i] # 当前的一列
nan_num = np.count_nonzero(np.isnan(temp_col))
if nan_num != 0: # 不为0,说明当前这一列中有nan
temp_unan_col = temp_col[temp_col==temp_col] # 当前一列不为nan的array
temp_col[np.isnan(temp_col)] = temp_unan_col.mean() # 选中nan的位置,给其赋值
return t1
if __name__ == "__main__":
# 准备一个供操作的数组
t1 = np.arange(12).reshape((3, 4)).astype("float")
t1[1, 2:] = np.nan
print(t1)
t1 = del_nan(t1)
print(t1)
- 有几个要点:
- 用shape来获取多少列。然后搭配range遍历。
- temp_col = t1[:,i] 取出当前的一列
- 当t为一维数组时,t[t==t]会返回不为nan的array。
8.5 numpy 与 matplotlib合作
- 准备一个numpy文件处理数据
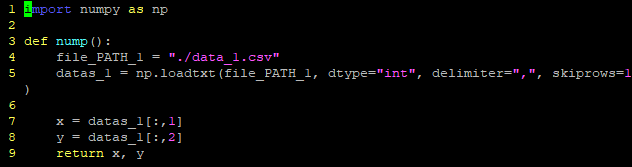
- 准备一个matplotlib文件接收数据并画图

- 画出来的图是这样的:
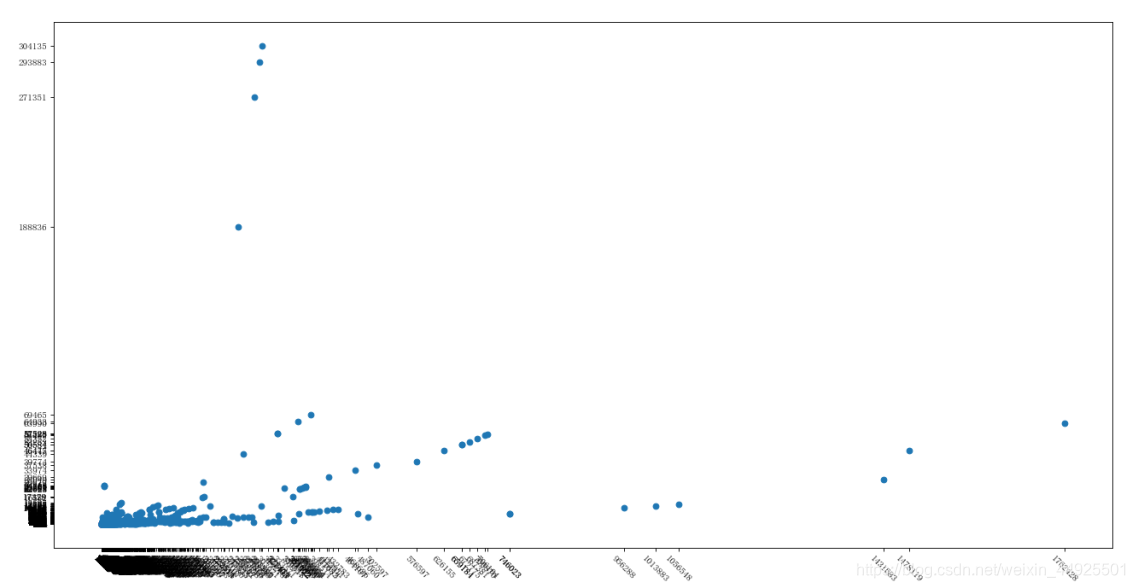
我们会发现有离群点,怎么剔除离群点呢?必定是数据方面的问题
通过观察,我们剔除y>10万的,x>55万的
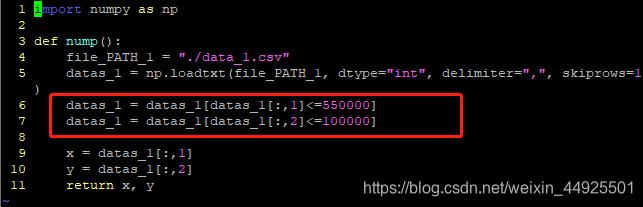
这里我们利用布尔索引改变原始数组(不能直接改x或y)
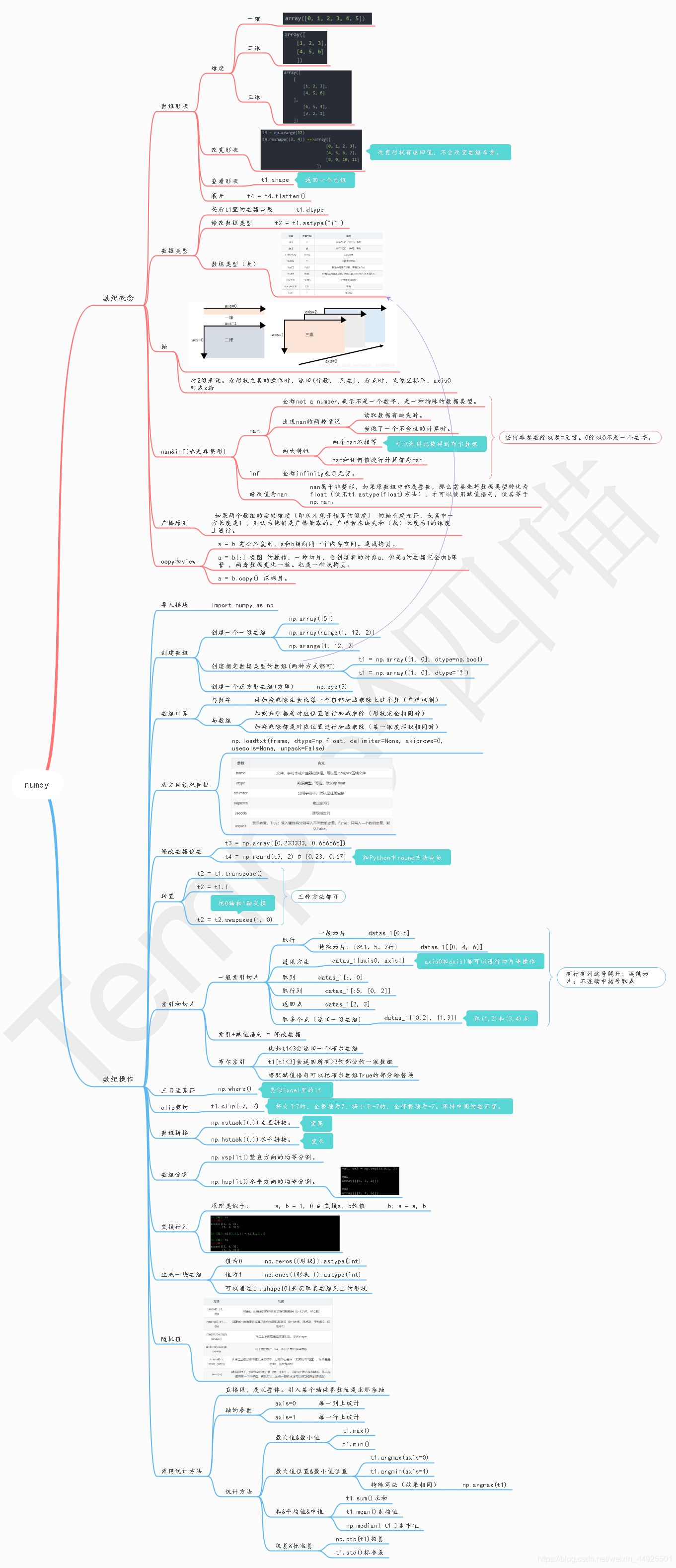
9. 思维导图
三、pandas
- pandas除了处理数值外(基于numpy),还能够帮助我们处理其他类型的数据
- 常用数据类型:
- Series一维,带标签数组
- DataFrame二维,Series容器
1. Series
1.1 Series基础
- Series一维,带标签数组。那么,什么是标签呢?
import pandas as pd
t1 = pd.Series([1, 5, 7])

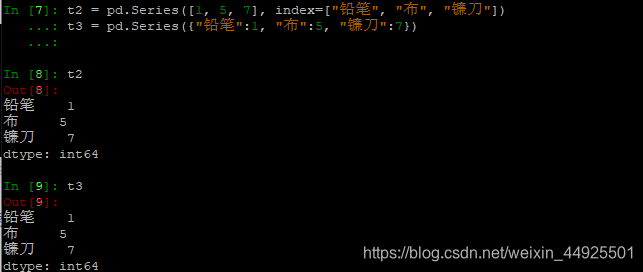
- 标签就是索引。索引可以指定,必须和数组一样长。(以下两种方式都可)
t2 = pd.Series([1, 5, 7], index=["铅笔", "布", "镰刀"])
t3 = pd.Series({"铅笔":1, "布":5, "镰刀":7})
- 类字典的这种也可以重新赋予索引。
- 而且变成浮点了
a = {"铅笔":1, "布":5, "镰刀":7}
t3 = pd.Series(a, index = {"电线杆", "布", "旗帜"})
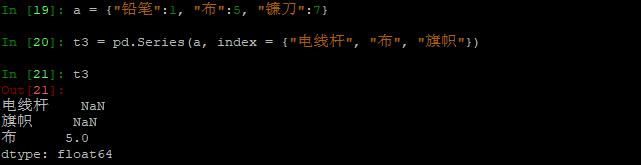
行为类似:小张有铅笔,布和镰刀;你向其要了电线杆,布和旗帜;小张就告诉你,他只有布(这个布有5种颜色:5可以理解为属性,描述),其它就是nan。
- 修改dtype(和numpy一样操作)

- 切片和索引
像列表和字典那样操作。对于像字典的类型,也可以通过位置来取。

- 取不连续点和布尔索引(同numpy)

- 取出所有键、值(返回的结果是可迭代的)
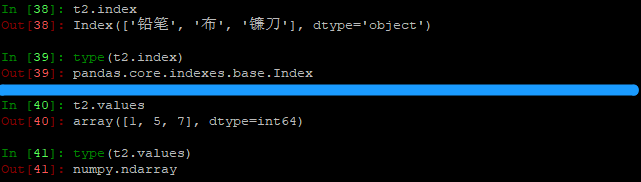
字符串类型就会显示为object。t2是int64类型的,由此可见t2的dtype是由value决定的。
t2.index是pandas.indexes.base.Index类型。t2.values是数组类型。
- 可见,Series是由“标签”+“数组”组成的,再品味一下,带标签的一维数组是什么意思。
- ndarray的很多方法可以运用与Series类型,比如argmax,clip等
- Series的where方法和ndarray不同:

读取外部数据
| 方法 | 读取 |
|---|---|
| read_csv | 读取csv |
| read_cliboard | 读取剪切板 |
| read_excel | 读取Excel |
| read_html | 读取html |
| read_json | 读取json |
| read_sql | 从数据库 |
a = pd.read_csv("./文件名.csv")
pd.read_sql(sql语句, connection链接)
TODO:这是链接MongoDB的用法
from pymongo import MongoClient
import pandas as pd
client = MongoClient()
collection = client["douban"]["tv1"]
data = list(collection.find())
a = pd.read_sql(sql语句, connection链接)
3. DataFrame
- Series一维,带标签数组
- Dataframe二维,Series容器

竖着的这一列称为index (行索引),横着的这一列称为columns (列索引)。

- 只看index列和A列,会发现这是一个Series。只看columns行和1列…这就是为什么DataFrame被称为Series容器
- 传入字典: 会发现键是列索引,很像我之前提到的升维(值里面的列表,就是一个Series)
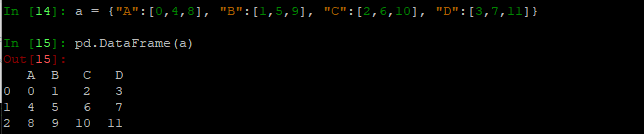
- 传入列表: (如果有缺失的,会呈现nan)
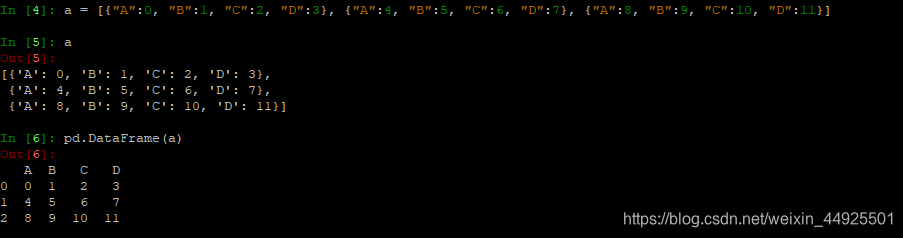
基础属性查询
- 查看索引、值
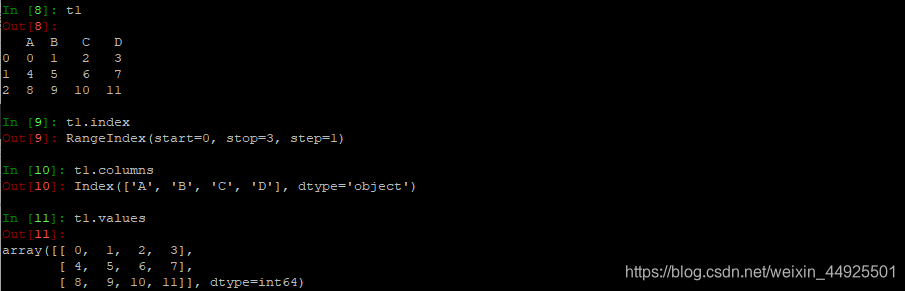
会发现,值是数组类型的
- 查看形状&列数据类型

- 查看数据维度

整体情况查询
- head显示头部几行(默认5),tail显示末尾几行(默认5)

- info相关信息概览:
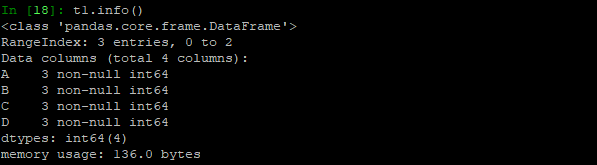
由DataFrame创建。行索引3个,从0~2。列索引,总共四个:A,3个非空值,列类型int64,内存占用136bytes。
- describe快速综合统计结果(只会统计含数字的):
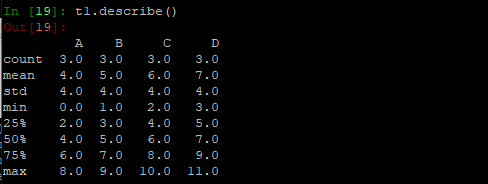
计数、平均、标准差、最小值、分位点、最大值
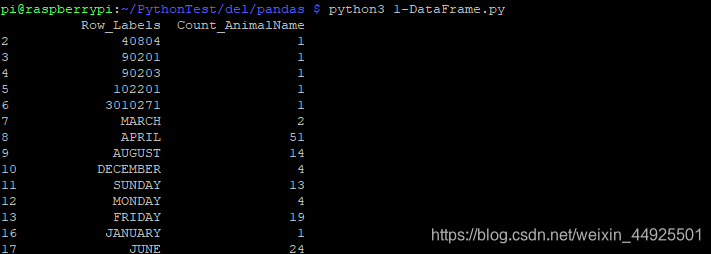
DEMO:按照统计次数进行排序
- 准备一个csv文件,Count_AnimalName就是统计次数,现在要从大到小排序
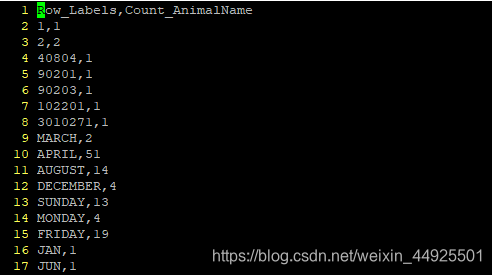
- 先看一下情况:

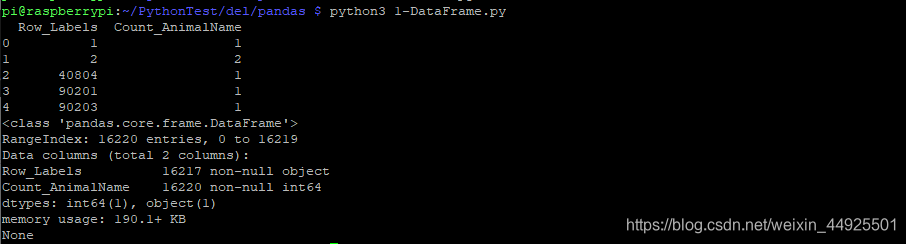
可以发现,Row_Labels少了三个数据
- 进行排序:
# 按某一列进行排序。False表降序,不填默认升序。
t1.sort_values(by="排序的字段", ascending=False)
- 最终代码:
import pandas as pd
datas = pd.read_csv("./dogNames2.csv")
# print(datas.head())
# print(datas.info())
del_datas = datas.sort_values(by="Count_AnimalName", ascending=False)
print(del_datas.head())

切片
- 取前10行,第一列
del_datas[:10]["Row_Labels"]
pandas中,方括号取数字,表示对行进行操作。去字段名,表示对字段进行操作。
loc
- t1.loc通过标签索引行数据

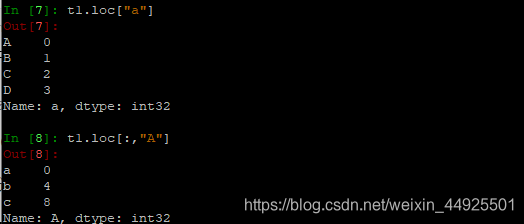

和数组切片方式类似。
下面这种方法比较特殊(因为是键表示索引,所以比较特殊,右边也会被选中)

t1.loc通过位置获取行数据(这种方法就跟数组切片索引完全一致)


- 这里居然可以直接赋值nan(不用先转化为float类型),并且可以进行统计(排除nan之后的其它数据进行统计)
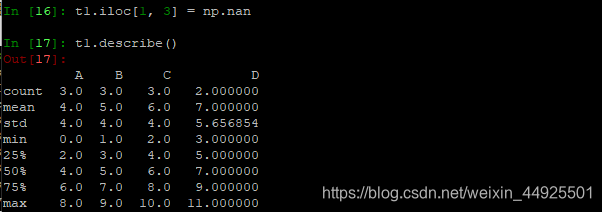
布尔索引
- 一个条件时
del_datas = datas[datas["Count_AnimalName"]>777]
- 多个条件时,用括号包起条件,再用&连接
del_datas = datas[(datas["Count_AnimalName"]>777)&(datas["Count_AnimalName"]<1024)]
&表示且;|表示或
pandas之字符串方法
- to_list()可以将单字段转变为一个大列表
| 方法 | 说明 |
|---|---|
| cat | 元素级的字符串连接操作,可指定分隔符 |
| contains | 返回表示各字符串是否含有指定模式的布尔型数组 |
| count | 模式出现的次数 |
| endswith/startswith | 相当于对每个元素执行x.endswith(pattern)或x.startswith(pattern) |
| findall | 计算各字符串的模式列表 |
| get | 获取各元素的第i个字符 |
| join | 根据指定的分隔符,将Series中各元素的字符串连接起来 |
| len | 计算各字符串的长度 |
| lower/upper | 转换大小写。相当于对各个元素执行x.lower()或x.upper() |
| match | 根据指定的正则表达式对各个元素执行re.match |
| pad | 在字符串的左、右或左右添加空白符 |
| center | 相当于pad(side=“both”) |
| repeat | 重复值。s.str.repeat(3)相当于对各个字符串执行x*3 |
| replace | 用指定字符串替换找到的模式 |
| slice | 对Series中各个字符串进行子串截取 |
| split | 根据分隔符或正则表达式对字符串进行拆分 |
| strip/rstrip/lstrip | 取出空白符,包括换行符。相当于对各个元素执行x.strip()/x.rstrip()/x.lstrip() |
- 比如选出字符串长大于3的:
del_datas = datas[datas["Row_Labels"].str.len()>3]
缺失数据处理
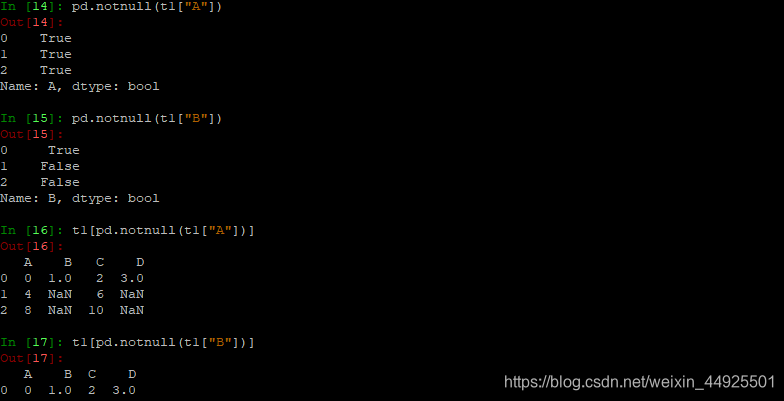
- pd.isnull(t1)返回一个布尔df。是nan的地方就为True。还有一个notnull方法,正好相反。

- 使用布尔嵌套
删除数据
- dropna删除含nan的。dropna(axis=指定轴, how=“删除方式”, inplace=False)
- axis=0表示删除行。
- 删除方式默认为any,表示只要有nan就把整行/列删了。也可以指定为all,表示该行/列只有全部为nan,才会删除。
- inplace是很多方法都有的,表示是否进行原地替换,默认为False。下面两种方法效果是一致的:


填充数据
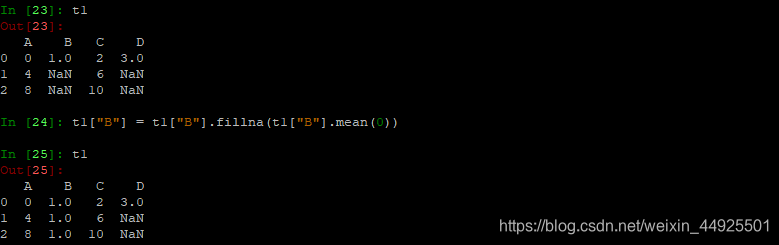
- fillna,填充nan

可以用t1.mean()来获取平均值。再填充进去。
- 有时候,数据中的0是表示数据缺失的,这时候,先将其变为nan,再进行操作。
t1[t1==0]=np.nan
pandas常用统计方法
获取个数
# 取一维
len(set(df["需要获取个数的索引"].tolist()))
# 相当于下面,unique是唯一的意思
df["需要获取个数的索引"].unique()
# 取二维
temp = df["需要获取个数的索引"].str.split(",").tolist() # 变成一个列表
alist = [i for j in temp for i in j] # 展开就变为一维了,再用len(set(list就可以了
字符串离散化的案例
- 这里有一堆电影类型,要统计
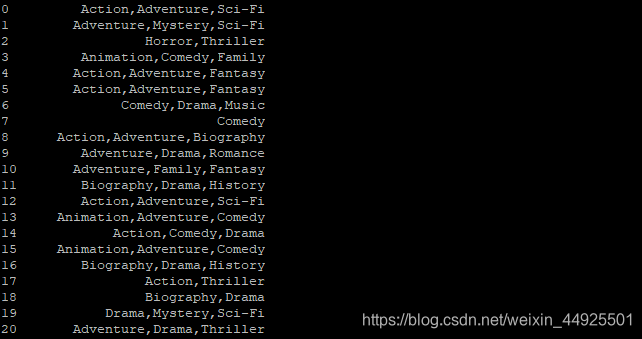
- 原理参考下面
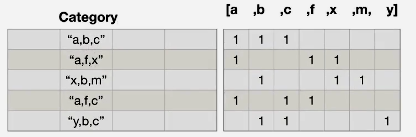
- 代码:
import pandas as pd
import numpy as np
file_path = "./IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
genre = df["Genre"]
# 1. 构建不重复的电影类型列表
genre_list_in_list = genre.str.split(",").tolist() # 嵌套列表
genre_list = list(set([i for j in genre_list_in_list for i in j]))
# 2. 构建全为0的数组
zeros_df = pd.DataFrame(np.zeros((df.shape[0], len(genre_list))), columns=genre_list)
# 3. 给每个电影出现的类型,赋值1
for i in range(df.shape[0]):
# zeros_df.loc[0, ["恐怖片", "喜剧片"]] = 1
zeros_df.loc[i, genre_list_in_list[i]] = 1
# print(zeros_df)
# 4. 统计每个分类的个数
count_df = zeros_df.sum(axis=0)
# print(count_df)
# 5.排序
# count_df是一个Series
rank_s = count_df.sort_values()
# print(rank_s)
# 6.制图
x = rank_s.index
y = rank_s.values.astype(int)
bar.bar(x, y)
from matplotlib import pyplot as plt
from matplotlib import font_manager
from random import randint
def bar(x, y):
# 数据
x = x
y = y
# 设置图形实例
plt.figure(figsize=(20,10), dpi=80)
# 设置字体
my_font = font_manager.FontProperties(fname="/home/pi/Font/simsun.ttc")
# 绘图
plt.barh(x, y, height=0.3)
# 刻度
max_y = max(y)
min_y = min(y)
plt.yticks(x, fontproperties=my_font, rotation=330)
plt.xticks(range(min_y, max_y, 50), fontproperties=my_font)
# 保存
plt.savefig("./s1.png")
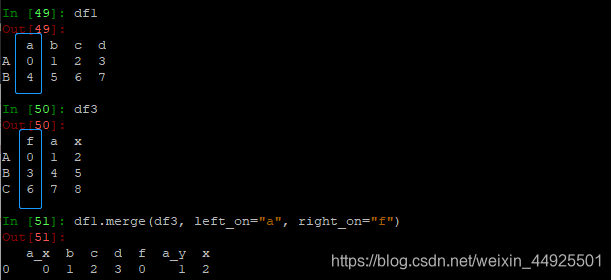
数据合并join
- 以df1的行为准,合并列
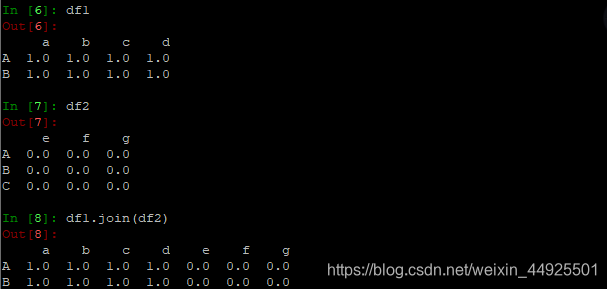
- merge方法就是mysql里的关联表的操作:
- 按“a”列左连接
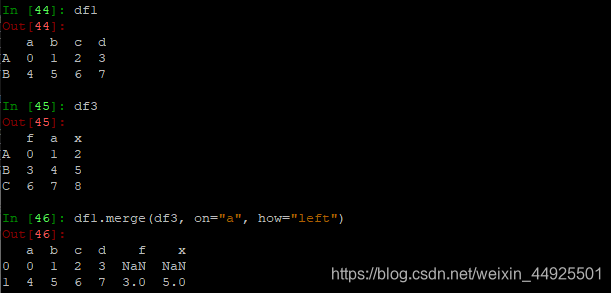
- 按“a”列取并集(外连接),合并行列
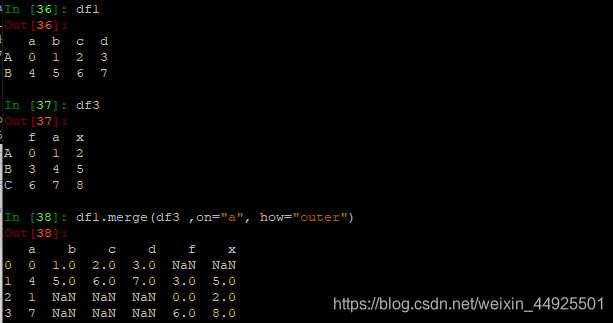
- 按"a"列取交集,合并行(其实是内连接,省略了how="inner"参数)

- 以左表的"f",和右表的"a"
数据分组聚合
- 这里有一张表“星巴克在各地门店数表”,想知道在中国各个城市的门店数量
分组聚合方法
import pandas as pd
file_path = "starbucks_store_worldwide.csv"
df =pd.read_csv(file_path)
# print(df.info())
# 1.调用分组方法
groups = df.groupby(by="Country")
- 它为DataFrameGroupBy对象
- 该对象可以进行遍历、调用聚合方法
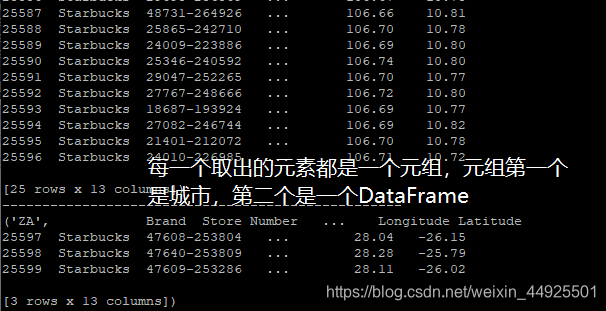
- 查看美国所有星巴克门店详细信息表
df[df["Country"] == "US"]
- 统计每个国家有多少家
print(groups["City"].count())

- 查看中国有多少家(上面那个相当于一个Series,对其直接取索引即可)
country_count = groups["Brand"].count() # Brand是随便选的字段
print(country_count["CN"]) # 打印中国店铺数量
DEMO:找出中国每个省份的店铺数量
china_data = df[df["Country"] == "CN"] # 利用布尔索引,找出中国的数据
groups = china_data.groupby(by="State/Province").count()["Brand"] # 按所在地分组,随便取一个字段来统计(这里选了Brand)
print(groups)
- 聚合方法:
| 函数名 | 说明 |
|---|---|
| count | 统计分组中非NA的数量 |
| sum | 非NA的和 |
| mean | 非NA的平均值 |
| median | 非NA的算术中位数 |
| std/var | 无偏(分母为n-1)标准差/方差 |
| min/max | 求非NA的最大/最小 |
多条件分组
groups = df.groupby(by= ["Country", "State/Province"]).count()
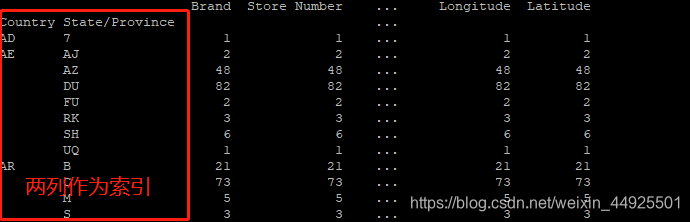
前面的两列作为索引
- 假如要取出Brand列,有两种方法:
# 方式1。因为Brand里没有Country字段,所以需要使用特殊形式
groups = df["Brand"].groupby(by= [df["Country"], df["State/Province"]]).count()
# 方式2
groups = df.groupby(by= [df["Country"], df["State/Province"]]).count()["Brand"]
# 方式3,就是方式2换了顺序
groups = df.groupby(by= [df["Country"], df["State/Province"]])["Brand"].count()
 - 一处小语法细节: 对比一下两者区别(提示:类型)
- 一处小语法细节: 对比一下两者区别(提示:类型)
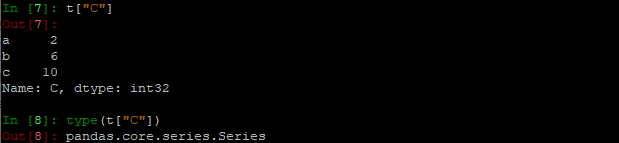

索引
- 把上面的索引方法打印一下:
print(groups.index)
# 只打印部分数据
MultiIndex(levels=[['AD', 'AE', 'AR'], ['0', '1', '10']],
labels=[[0, 1, 1]],
names=['Country', 'State/Province'])
levels包含索引(包括索引Country和索引State/Province),labels包含索引的值,names包含索引字段名
index可以用来赋值
- 重新设置index
df.index = ["a", "b"]
- 从df里取两行(如果某行不存在,那么会那行会返回nan)
df.reindex(["a", "不存在的行"])
- 把当前某一列作为索引 (重点)
df.set_index("Countre", drop=False) # drop参数默认为True,表示作为索引后是否要保留该列


- 查看一下其索引返回的结果:
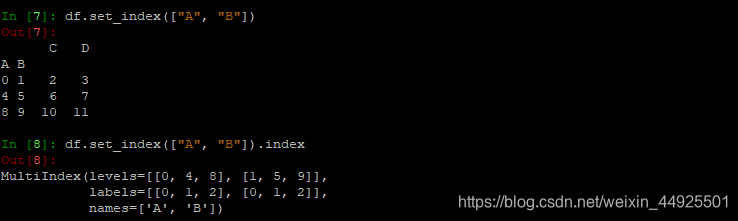
- 返回index的唯一值:df.index.unique()
- index是一个可迭代对象
Series复合索引
- 分组后如何取值: (先取列索引,行索引一级一级取)

- 交换列索引:
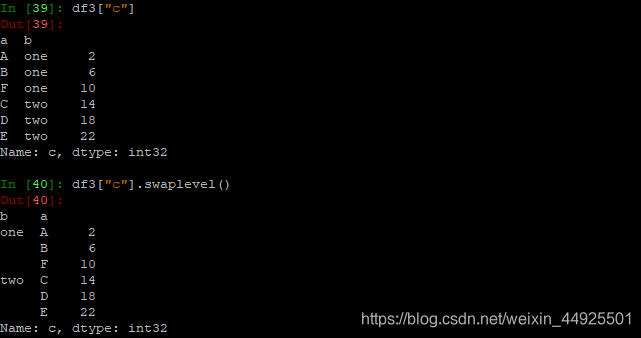
- 分组后取值的方法2:

- 然后从字段中取某一部分的思路:
如果某个信息藏在某个字段中。比如姓名字段中,我们只需要前面的姓氏。可以先读出所有姓名的字段,再通过新建一个姓氏字段:
df["新建的姓氏字段"] = pd.DataFrame(取得的姓氏)
最后再依据此字段,分组即可
时间序列
时间戳DatetimeIndex
pd.data_range(start=None, end=None, periods=None, freq=“D”)
- 参数说明:
start、end决定时间序列的始终
periods表示生成个数
freq表示频率,D表示以天为间隔
一般是start和end在一起使用,或者start和periods一起使用,不会同时使用
| 缩写 | 单词 | 含义 |
|---|---|---|
| D | Day | 日历日 |
| B | BusinessDay | 工作日 |
| H | Hour | 小时 |
| T或min | Minute | 分 |
| S | Second | 秒 |
| L或ms | Milli | 毫秒(千分之一秒) |
| U | Micro | 微秒(百万分之一秒) |
| M | MonthEnd | 每月最后一个日历日 |
| BM | BusinessMonthEnd | 每月最后一个工作日 |
| MS | MonthBegin | 每月第一个日历日 |
| BMS | BusinessMonthBegin | 每月第一个工作日 |
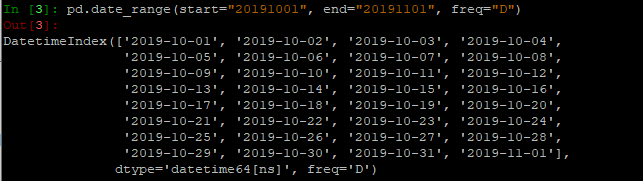


- 类型是Index类,一般也用做生成时传入Index
- 把时间戳转化成DF时间序列
df[“时间所在字段”] = pd.to_datetime(df[“timeStamo”], format="")
当时间所在字段里的时间,不符合时间序列格式规范时,用format把其格式传入(格式化)
20191001符合规范,2019/10/01符合规范,2019-10-01符合规范…
时间格式化
- 重采样: 将时间序列从一个频率转化为了一个频率进行处理的过程 , 将高频率转化为低频率为降采样 ,反之为升采样 。
t.resample(“M”).mean()按月取平均数
# 把时间戳转化为DF时间类型
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
df.set_index("timeStamp", inplace=True)
# 统计不同月份的数据
count_by_month = df.resample("M").count()
# 上述会得到一个DF,再取数据没有缺失的那一列即可
- 如果绘图时,出现了时分秒,又不需要:
-x = [i.strftime("%Y%m%d") for i in x_original_list]
时间段PeriodIndex
periods = pd.PeriodIndex(year=df["year"], month=df["month"], day=df["day"], hour=df["hour"], freq="H")
# 给时间段采样
data = df.set_index(periods).resample("10D").mean()
- DEMO:测算PM2.5随小时变化
import pandas as pd
file_path = "./BeijingPM20100101_20151231.csv"
df = pd.read_csv(file_path)
periods = pd.PeriodIndex(year=df["year"], month=df["month"], day=df["day"], hour=df["hour"], freq="H")
# 增加一列,把分开的时间字符串,组合
df["datatime"] = period
# 把datatime设置为索引
df.set_index("datatime", inplace=True)
# 处理缺失数据,删除缺失数据。返回一个Series,Index是时间,值是PM2.5
data = df["PM_US Post"].dropna()
- DEMO:测算PM2.5随10天变化
import pandas as pd
file_path = "./BeijingPM20100101_20151231.csv"
df = pd.read_csv(file_path)
periods = pd.PeriodIndex(year=df["year"], month=df["month"], day=df["day"], hour=df["hour"], freq="H")
# 增加一列,把分开的时间字符串,组合
df["datatime"] = period
# 把datatime设置为索引
df.set_index("datatime", inplace=True)
# 进行降采样
df = df.resample("10D").mean()
# 返回一个Series,Index是时间,值是PM2.5
data = df["PM_US Post"]
