文章目录
- 第16章:Hue大数据可视化分析
- Hue概述及版本下载
- Hue编译及安装
- Hue的基本配置与服务启动
- Hue与HDFS集成
- Hue与yarn集成
- Hue与MySql集成
- Hue与HBase的集成
- 对采集的数据进行可视化分析
- Hue需要注意的几个地方
- 第17章:Spark2.x环境准备/部署及运行
- Spark概述及特点
- Spark生态系统介绍
- 学习spark需要了解的几个重要网站
- spark2.2源码下载及编译
- Scala安装及环境设置
- spark2.2本地模式运行测试
- spark服务web监控页面
- 第18章:基于IDEA的spark程序开发
- 第19章:Spark集群运行模式
- 第20章:Spark2.X弹性分布式数据集
第16章:Hue大数据可视化分析
大数据,再次申明:上千万条左右的数据才能显示它的威力!
Hue概述及版本下载

备注:
- 类似于hadoop的UI系统
- Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python Web框架Django实现的。通过使用Hue我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据,例如操作HDFS上的数据,运行MapReduce Job等等。
- 版本:
Hue编译及安装
Hue的基本配置与服务启动
Hue与HDFS集成
Hue与yarn集成
Hue与MySql集成
Hue与HBase的集成
对采集的数据进行可视化分析
Hue需要注意的几个地方
考虑到个人时间原因,暂时未学习此章课程,有需要的还请自行查找资源。
第17章:Spark2.x环境准备/部署及运行

备注:
此案例使用新版spark2.2
Spark概述及特点
- Apache Spark is a fast and general engine for large-scale data processing.
-

-

备注:
- MLLib–基于spark
- Mahout——基于MapReduce
Spark生态系统介绍

备注:
- spark SQL+DataFrame:包括RDD、Dataframe、Dataset;Structed Streaming结构流(spark2.2之后正式)
- spark streaming:同类型的还有storm。但是相比之下spark针对数据源、数据处理、数据输出一体化做得更好。
- MLLib:和spark中的其他组件一样,都是基于内存。
- Graphx
- Spark Core API:
- R
- SQL:解析、编译、优化……
- python
- scala
- java
学习spark需要了解的几个重要网站
1) https://databricks.com/spark/about 论坛
2)http://spark.apache.org/ spark官网
3)https://github.com/apache/spark spark的github地址
spark2.2源码下载及编译
步骤:
1.自行下载spark2.2源码进行编译
问:为什么需要在机器上编译spark?
答:因为只有编译了hadoop2.6和2.7的版本,没有hadoop2.5的版本,所以需要自己编译。

注意官网上提醒的maven和jdk版本
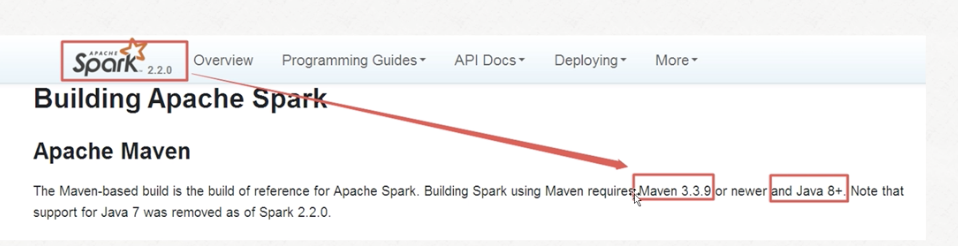
2.下载并解压maven
注意maven的版本,此例中使用3.3.9
tar -zxf apache-maven-3.3.9-bin.tar.gz -C /opt/modules
配置环境变量MAVEN_HOME:
在/etc/profile中添加
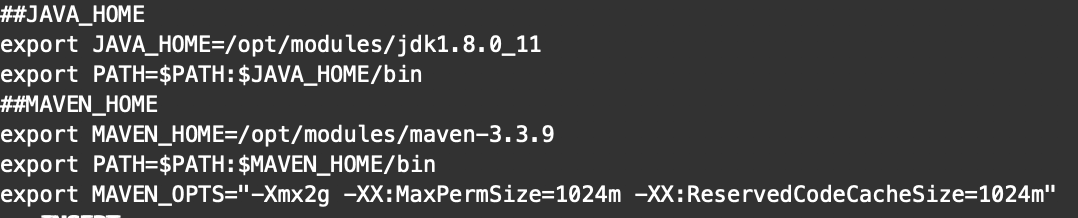
使配置生效
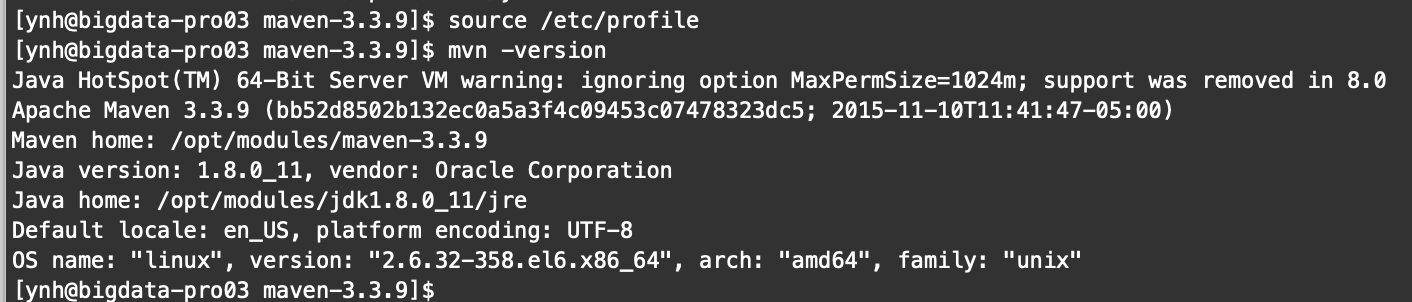
3.在/etc/resolv.conf文件中添加:
nameserver 8.8.8.8
nameserver 8.8.4.4
4.编辑/opt/modules/spark2.2.0/dev/make-distribution.sh文件:

5.此机器的网络设置切换为外网连接(网络连接设置为DHCP自动获取),保证此机的镜像源配置没有问题。
6.编译
./dev/make-distribution.sh --name custom-spark --tgz -Phadoop-2.5 -Phive -Phive-thriftserver -Pyarn
最后编译成功之后spark下会有一个包:spark-2.2.0-bin-custom-spark.tgz
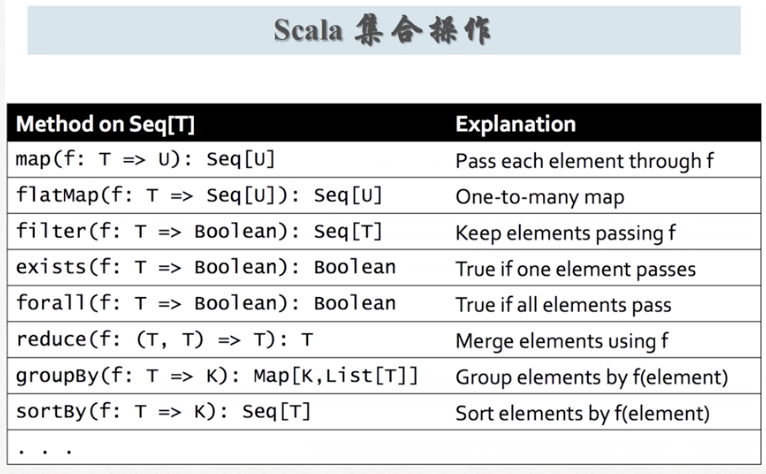
Scala安装及环境设置

Scala介绍:


spark2.2本地模式运行测试
1.本地模式启动一个spark应用(参考spark官网)
记得把网络切换为内网
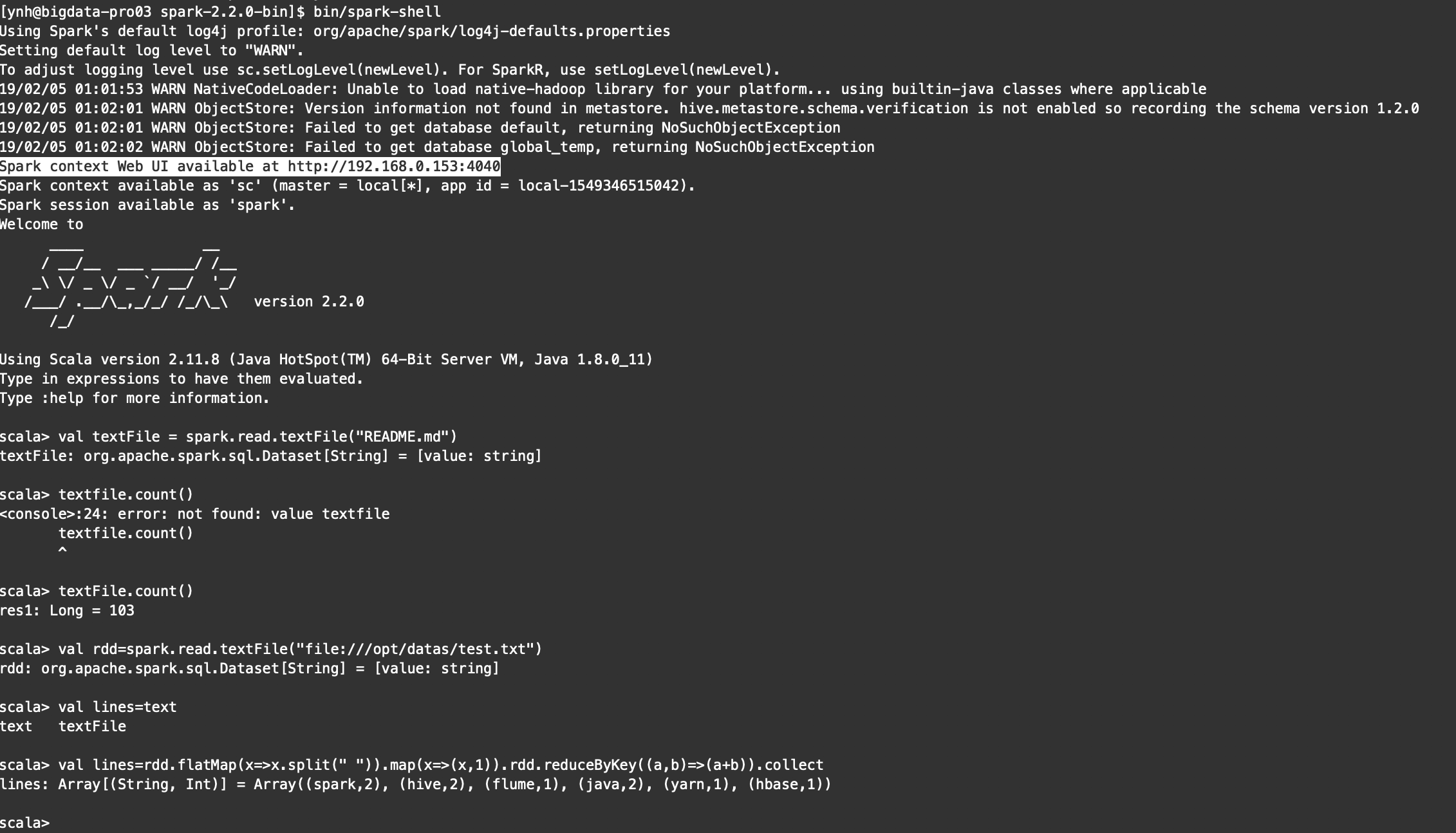
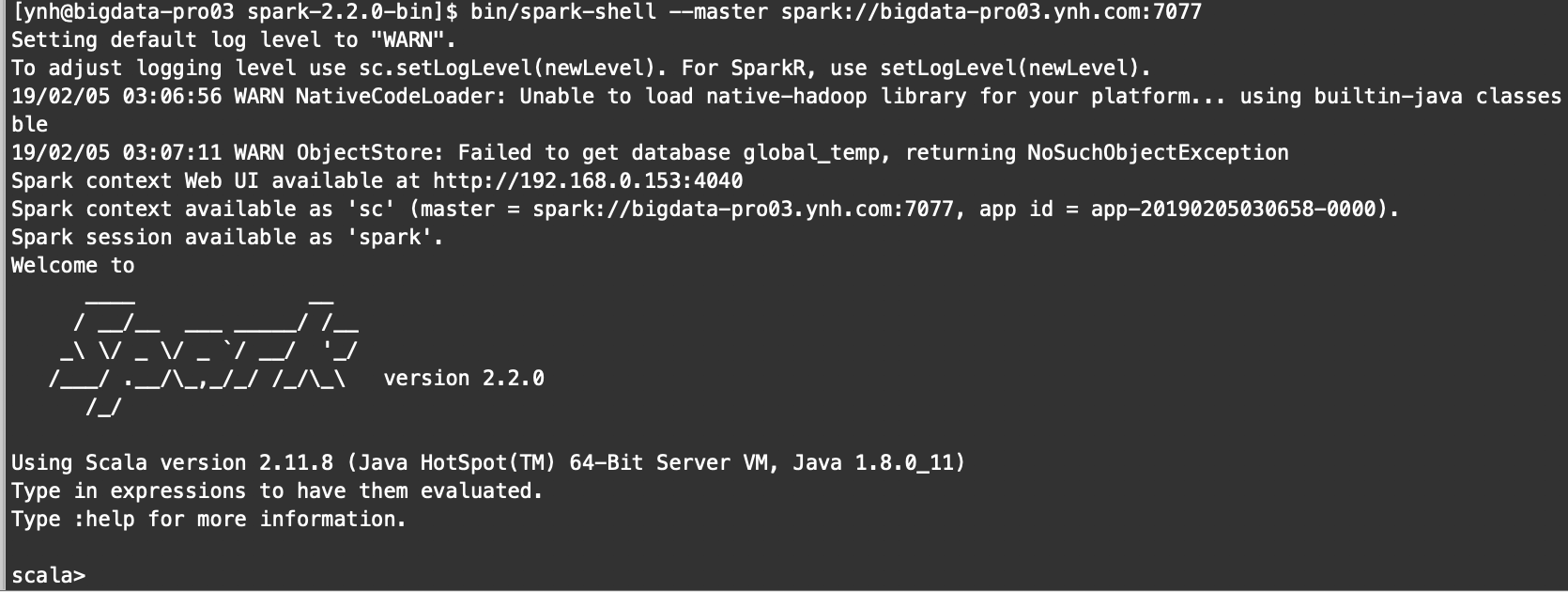
bin/spark-shell
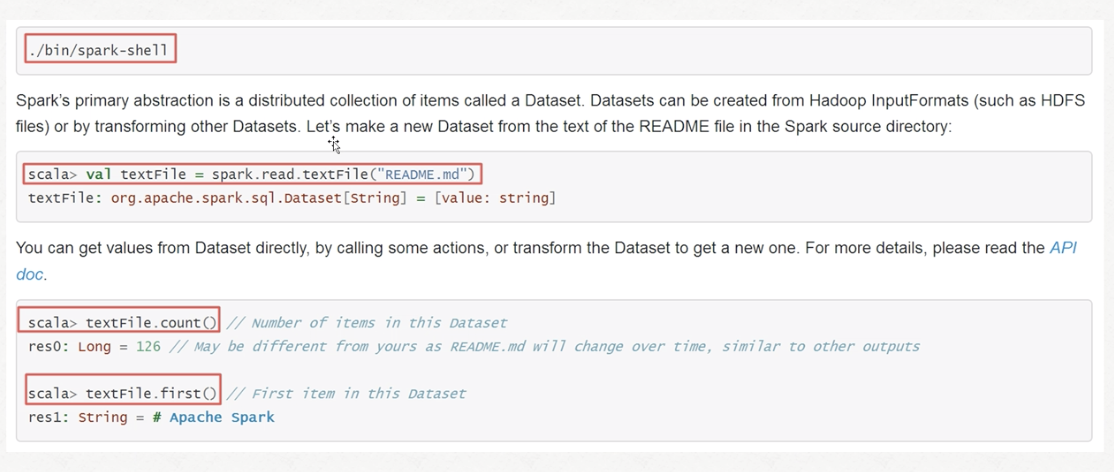

结果:
spark服务web监控页面
第18章:基于IDEA的spark程序开发
Windows下的配置与安装
- 下载Idea(破解)
- 安装Scala for Idea插件:法1-内置下载入口;法2-手动下载放到包内
(我的版本:Idea 2016.2.4;scala 2016.2.1) - 本机安装jdk1.8
- 本机下载安装maven3.3.9
- 本机环境变量配置:
- JAVA_HOME
- MAVEN_HOME
Idea Maven工程创建与配置

- scalaSDK导入
- pom文件编辑
(首先可以参考官方github上的pom文件,然后参考spark官网给出的maven依赖详细添加)
开发Spark Application程序并进行本地测试
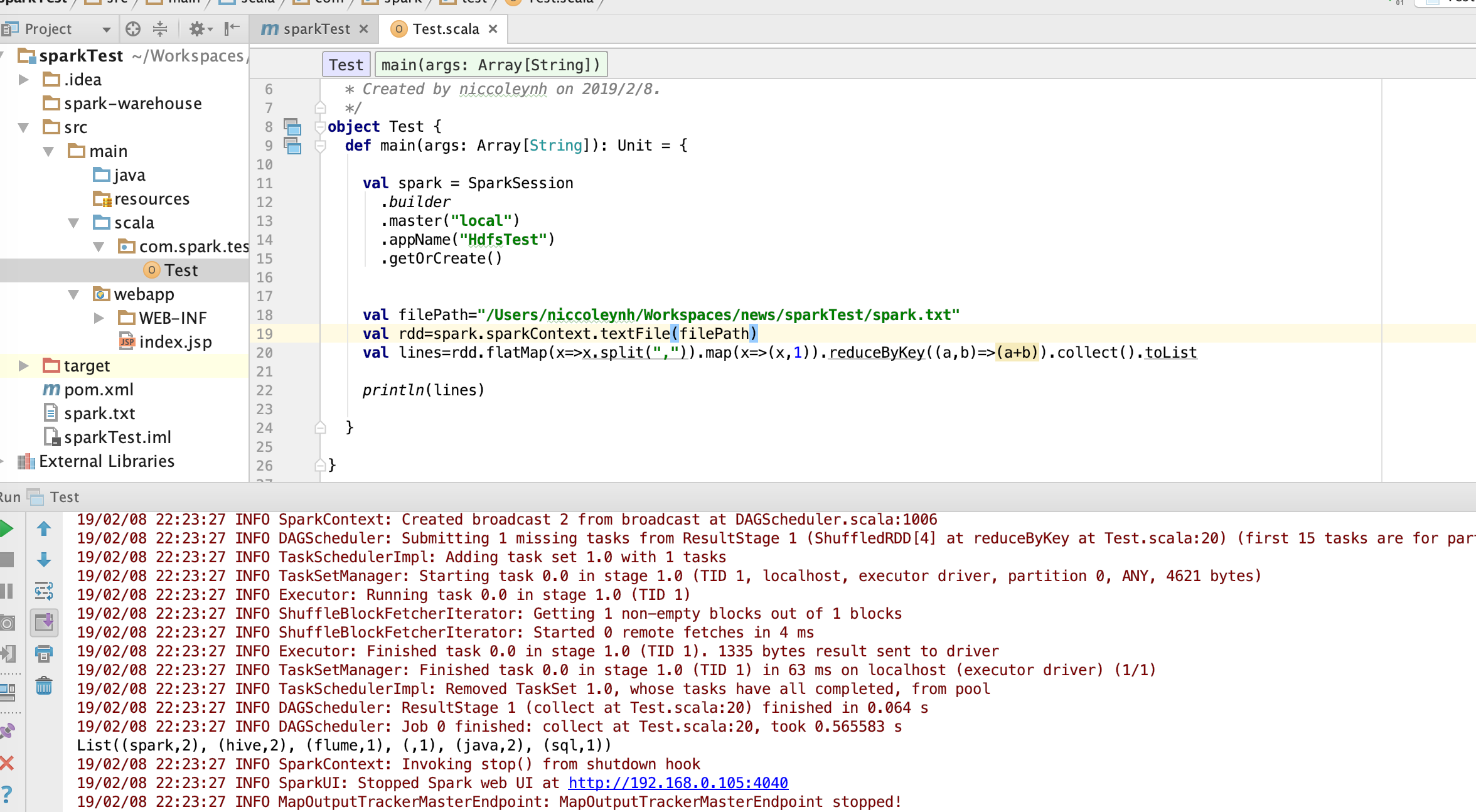
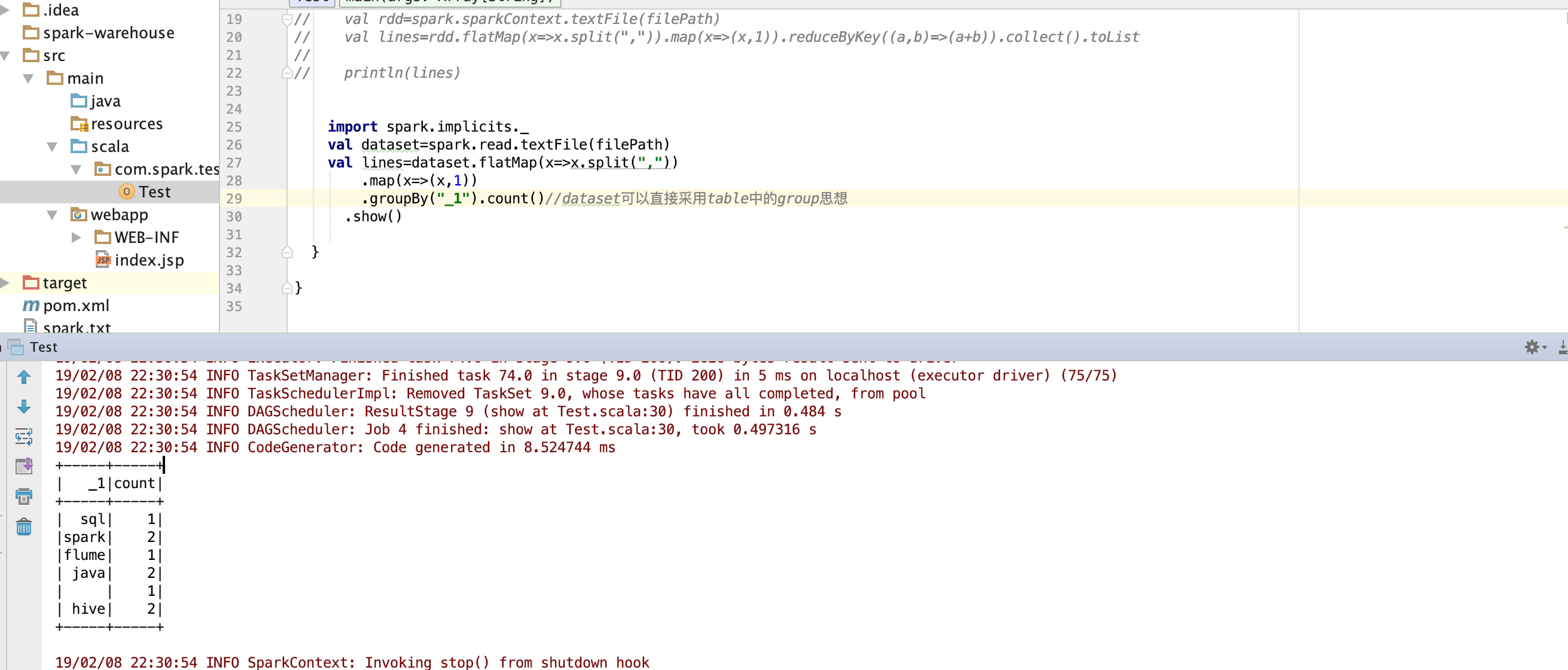
生成jar包并提交spark-submit
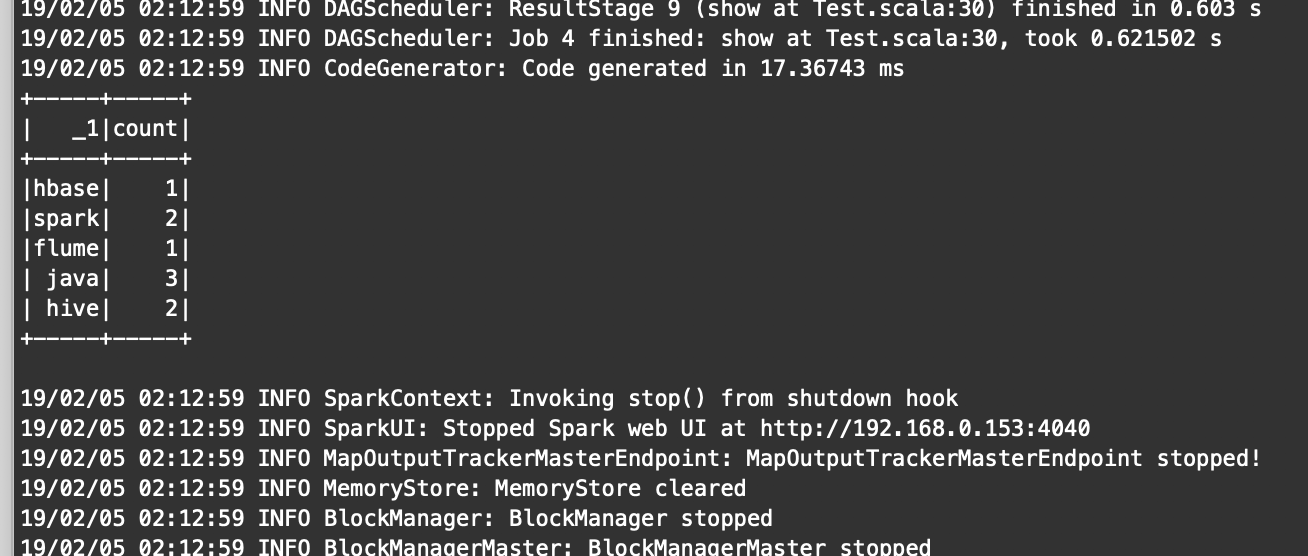
bin/spark-submit --master local[2] /opt/jars/sparkTest.jar hdfs://bigdata-pro01.ynh.com:9000/user/datas/test.txt
结果:
第19章:Spark集群运行模式
Spark几种运行模式介绍
- spark几种运行模式
- 1.Local
- 2.Standalone(spark自己的集群管理)
- 3.yarn
- 4.Mesos(Spark初期支持),一般企业中涉及到需要对hadoop进行升级有风险的时候可以采用Mesos。
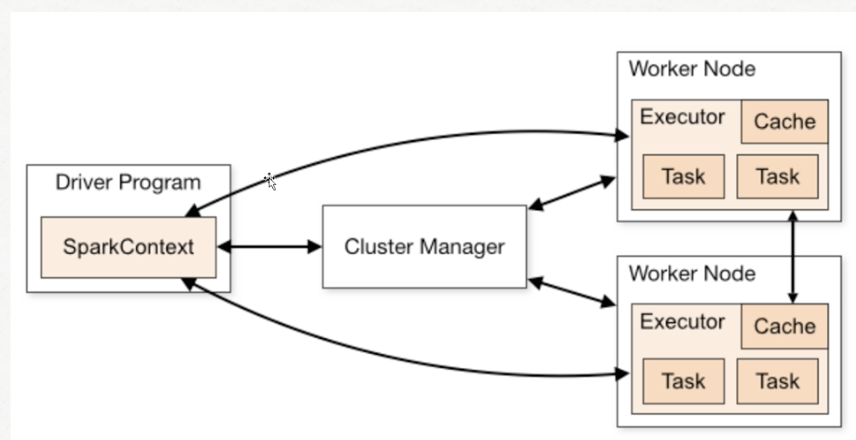
Spark Standalone集群模式配置与运行

- standalone架构图:
- 执行步骤:

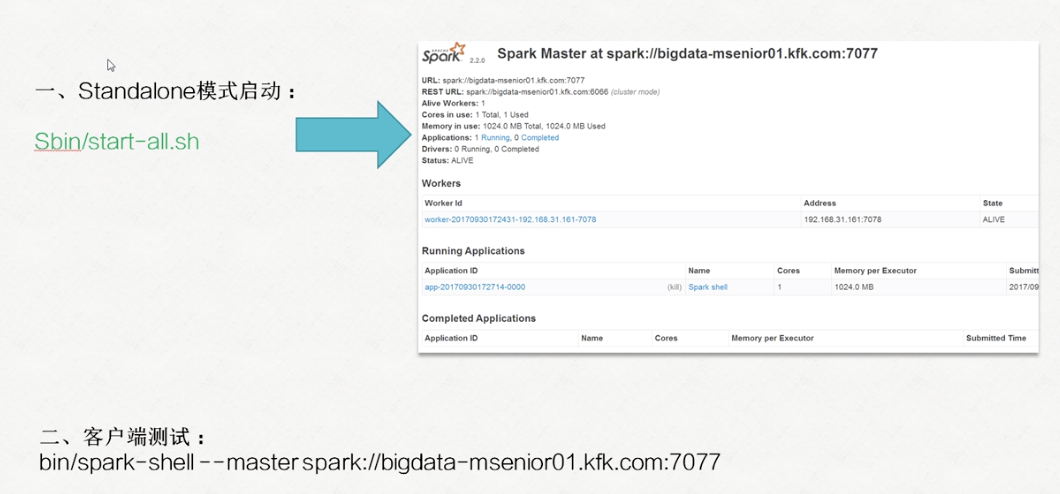
结果:
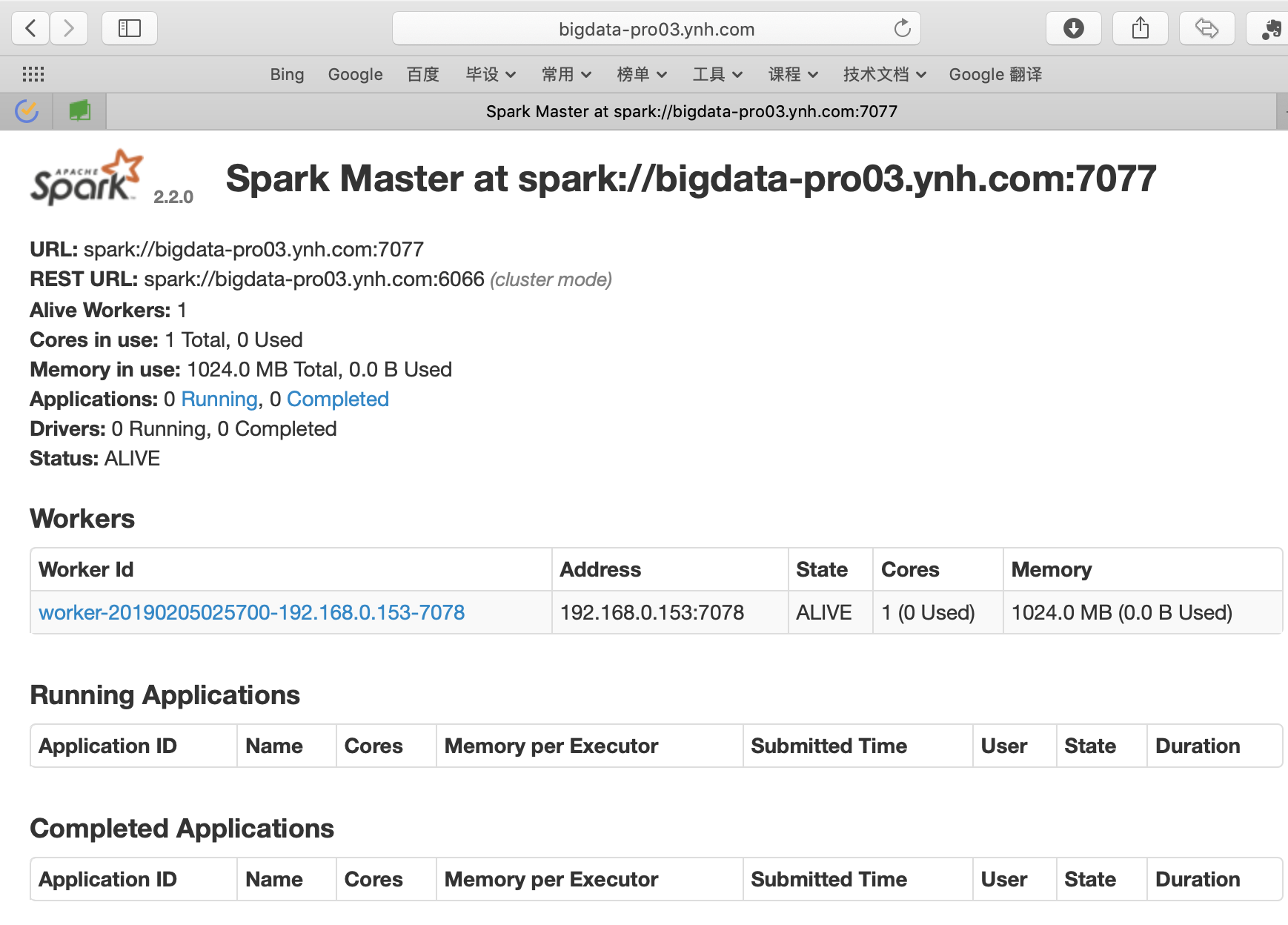
- 集群运行:
bin/spark-submit --master spark://bigdata-pro03.ynh.com:7077 --deploy-mode cluster /opt/jars/XXX.jar file:///opt/datas/weblog.log
Spark on Yarn集群模式配置
- 启动yarn
bin/spark-shell --master yarn --deploy-mode client
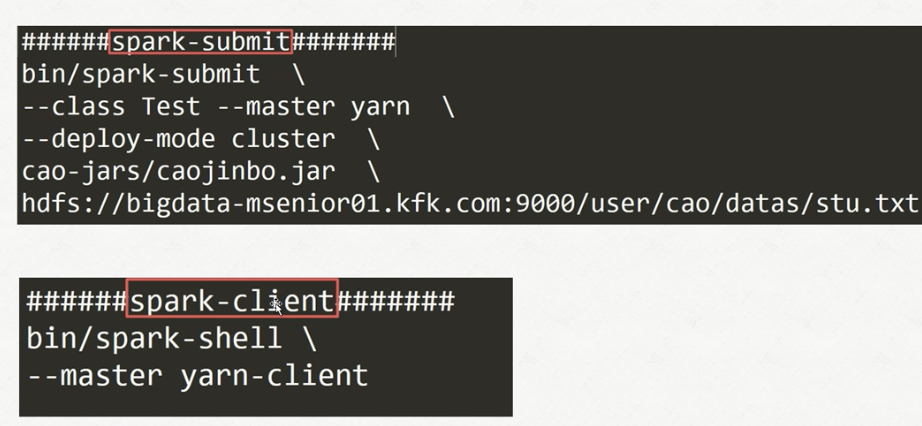
补充:spark-submit和spark-client命令
- 问题:当遇见yarn kill掉任务因为任务内存分配超出yarn现有的内存之后)
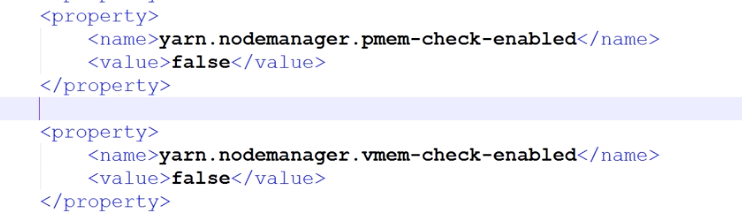
解决:配置yarn-site.xml
- 测试spark-submit提交任务:
bin/spark-submit --class com.spark.test.Test --master yarn --deploy-mode cluster /opt/jars/sparkTest.jar file:///opt/datas/test.txt
- 总结:
- spark on yarn的模式的话最好保证虚拟机的内存要大一些(但是也不要超过本机的限度)
- yarn检测线程会干掉内存占用超出限度的,将yarn-site中的相关项改为false
- 打包程序时,2.0之后的spark程序master(”local“)改为(“yarn-cluster”)
第20章:Spark2.X弹性分布式数据集
三大弹性分布式数据集介绍
- RDD\DF\DS都是spark平台下的弹性分布式数据集。
- 三者对比

Spark RDD概述与创建方式
Spark RDD五大特性
-
五大特性:
- 1.rdd是一个分区的集合
- 2.A fuction for computing each split 每一分区都有一个函数(计算任务)用于计算
- 3.RDD之间是相互依赖的。能够保障故障自动恢复
- 4.当RDD是key-value分区的,采用的是hash-partitioned分区算法
- 5.spark执行计算的时候,会根据数据节点位置来移动计算任务(计算任务移动优先)

Spark RDD操作方式及使用(一)
- 两种操作:
- transformation:懒加载,直到actioin阶段才会执行

- action

- transformation:懒加载,直到actioin阶段才会执行
DF创建方式及功能使用

DS创建方式及功能使用
DS继承了DF和RDD的优点和缺点。DS既能像RDD一样对每个元素进行操作(比如map……),也能像DF一样像table一样操作
数据集之间的对比与转换
- 转换(scala语言)
- DF->DS: val ds=df.as[对应的对象]
- RDD/DS->DF: .toDF
- DS/DF->RDD:.rdd
说明:
此系列文章为网课学习时所记录的笔记,希望给同为小白的学习者贡献一点帮助吧,如有理解错误之处,还请大佬指出。学习不就是不断纠错不断成长的过程嘛~