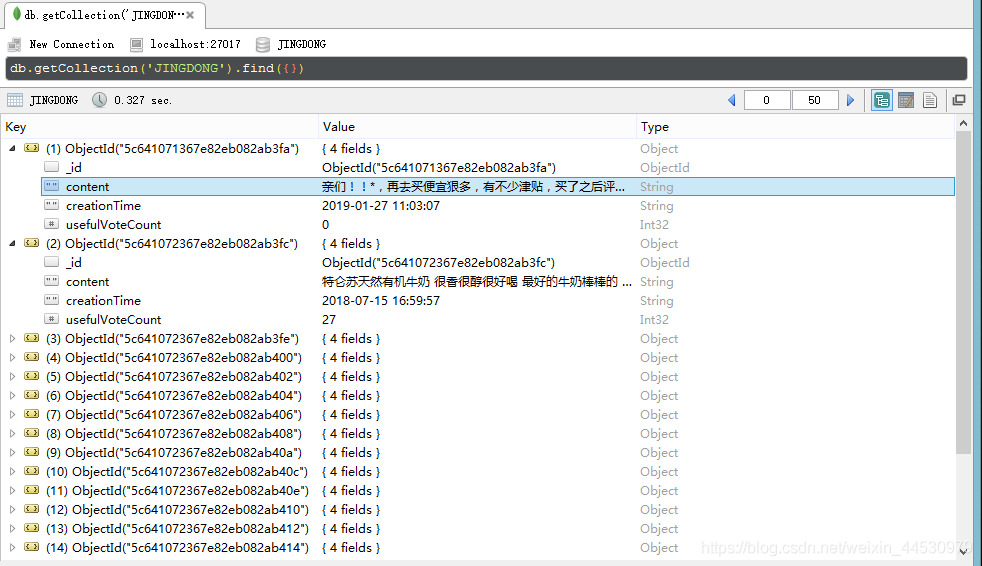
用python的requests库爬取京东某商品的评论内容,评论有用数及时间,并将结果存到MongoDB
**1、**首先打开所选商品的详情页面,此处以https://item.jd.com/2922989.html为例,打开chrome开发者工具,点击商品评价,在某项评论中找一个关键字(此处以logo为关键字),使用chrome开发者工具中的Search功能,输入后找到包含该关键字的文件,文件中记录了该评论的详细信息,如下图所示。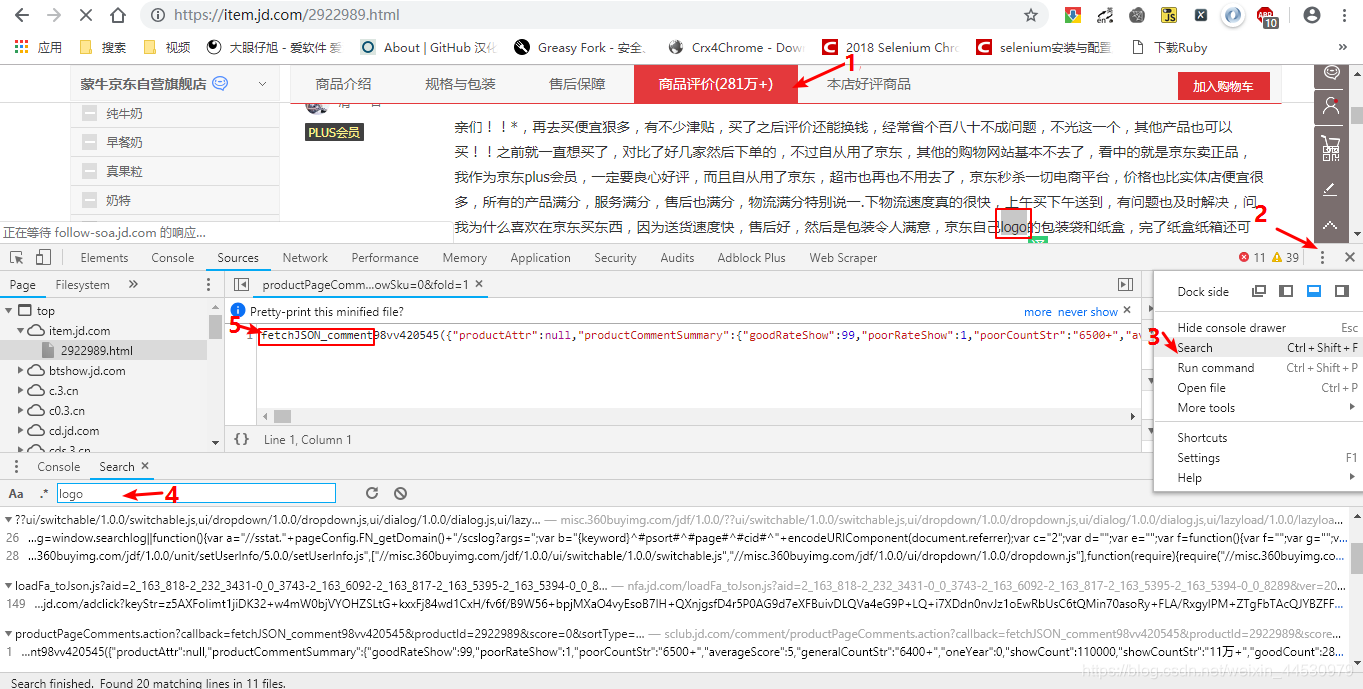
**2、**找到该文件后提取关键字fetchJSON_comment,切换到Network,搜索该关键字可以得到该文件,发现其为JS文件,点击该文件后我们可以看到所需要的数据在comments中。
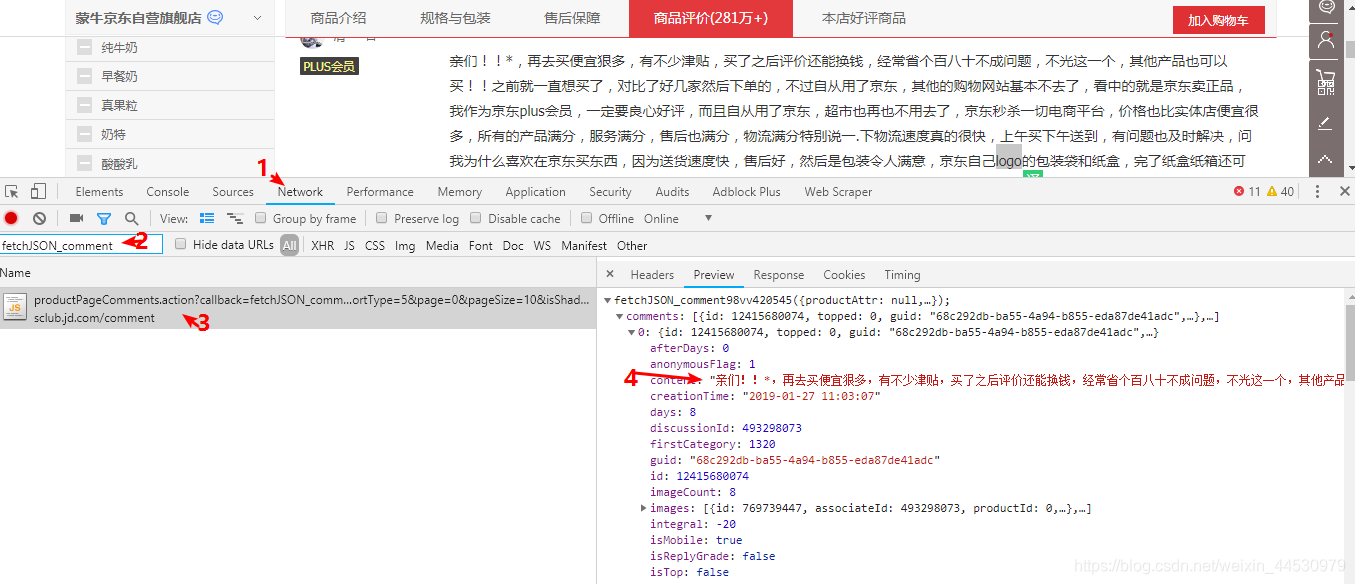
接着切换到Headers,可以得到我们请求到该文件的URL为:https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv420545&productId=2922989&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
通过点击多页得到的URL分析可知,该URL中变化的部分为page字段,其对应的就是页码数。要想从存储数据的文件中国提取到我们想要的数据,需对此URL中一些参数进行处理,经处理后得到一个简缩版的URL为:https://sclub.jd.com/comment/productPageComments.action?productId=2922989&score=0&sortType=5&page={“此为页码数”}&pageSize=10 ,此时该URL返回的数据是一个json数据格式,分析完毕后启动pycharm创建项目,具体代码如下:
主程序:jingdong.py
from config import *
import json
import pymongo
import requests
client = pymongo.MongoClient(MONGO_URL, connect=False)
class JingDongSprider():
def __init__(self):
self.url_temp="https://sclub.jd.com/comment/productPageComments.action?productId=2922989&score=0&sortType=5&page={}&pageSize=10"
self.headers={"User-Agent":set_user_agent()}
def get_url_list(self):
return [self.url_temp.format(i) for i in range(0,2)]#此处只抓取前两页评论
def parse_url(self,url):
response=requests.get(url,headers=self.headers)
return response.text
def get_content_list(self,json_str):
dirt_ret = json.loads(json_str)
content_list=dirt_ret["comments"]
if content_list:
for content in content_list:
comment = {}
comment['content'] = content['content']#评论内容
comment['usefulVoteCount'] = content['usefulVoteCount']#评论有用数
comment['creationTime'] = content['creationTime']#评论发布时间
self.save_to_mongo(comment)
def save_to_mongo(self,comment_list):#存储数据
db = client[taget_DB]
if db[taget_TABLE].update_one(comment_list, {'$set': comment_list}, upsert=True):
print('Successfully Saved to Mongo', comment_list)
def run(self):
#1.url_list
url_list=self.get_url_list()
#2.遍历,发送请求,获取响应
for url in url_list:
html_str=self.parse_url(url)
#3.提取数据
self.get_content_list(html_str)
if __name__ == '__main__':
jingdong=JingDongSprider()
jingdong.run()
辅助程序:config.py,用于连接MongoDB,及设置随机请求UA以应对反爬
import random
MONGO_URL = 'localhost'
taget_DB = "JINGDONG"
taget_TABLE = "JINGDONG"
def set_user_agent():
USER_AGENTS = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
user_agent = random.choice(USER_AGENTS)
return user_agent
爬取结果如下图: