写在前面的话 :上一篇文章我们学习了selenium的使用方法,接下来我们将使用selenium来爬取京东商品信息
温馨提示 :博主使用的系统为win10,使用的python版本为3.6.5
一、网页分析
原来,博主打算写一个能够爬取所有商品信息的爬虫,可是在分析过程中发现,不同商品的网页结构还是不一样的,所以后来就放弃了这个想法,转为只爬取笔记本类商品的信息(若要爬取其它类商品信息,只需要把提取数据的规则改变就好,有兴趣的同学可以自己试试看呀)
用chrome打开笔记本商品首页,我们很容易发现该网页是一个动态加载的网页,因为刚打开网页时只会显示30个商品的信息,可是当我们向下拖动网页的时,它会再次加载剩下的30个商品信息,所以我们就可以通过selenium模拟浏览器下拉网页的过程来获取网页返回的全部商品信息
>>> browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")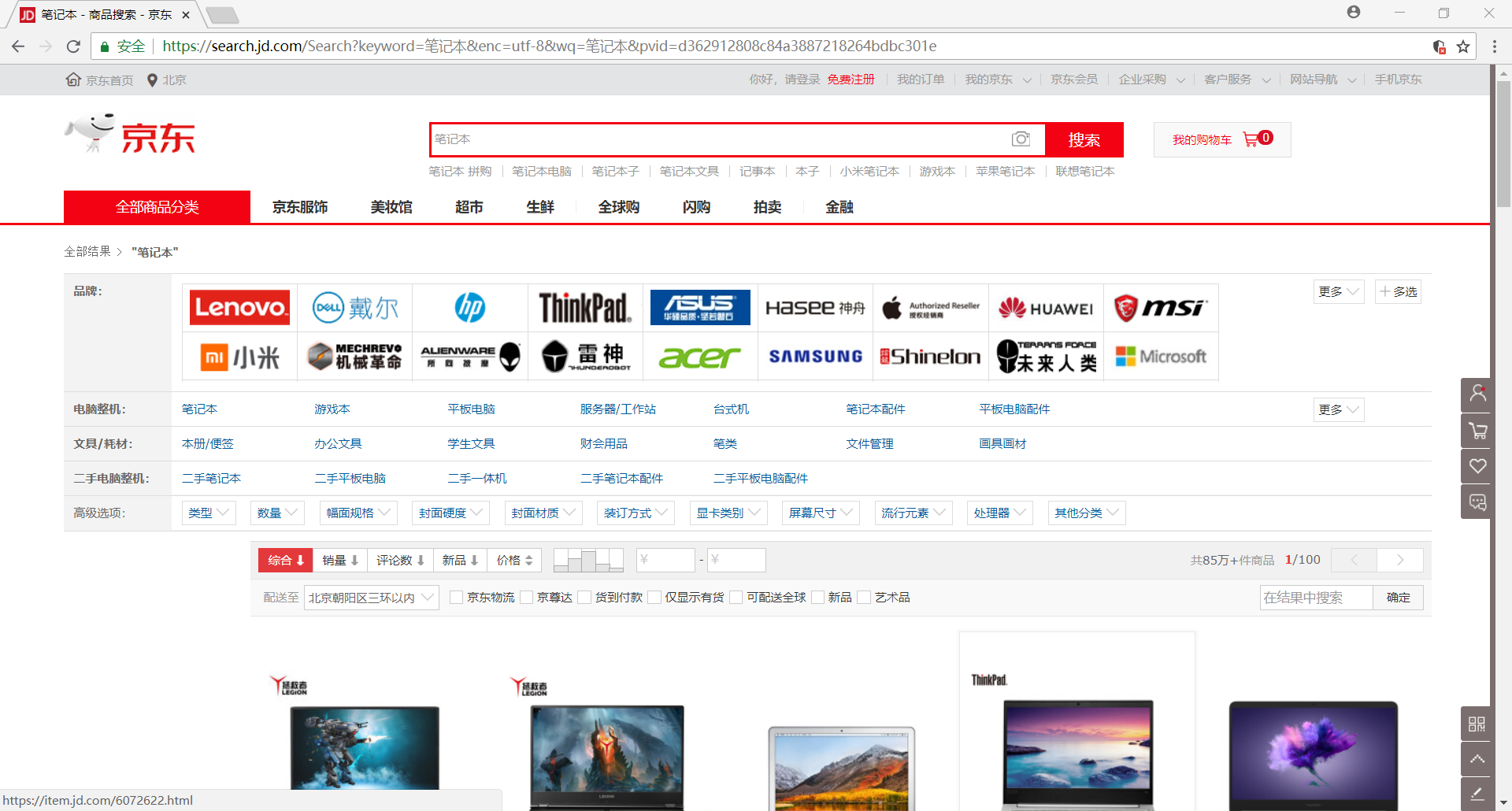
另外,我们发现该网站一共有100个网页,当然我们可以通过构造URL来获取每一个网页的内容,但是这里我们还是选择使用selenium模拟浏览器的翻页行为,下拉网页至底部可以发现有一个 下一页 的按钮,我们只需获取该元素并点击即可实现翻页了
>>> next_page = browser.find_element_by_xpath('//a[@class="pn-next" and @onclick]')
>>> next_page.click()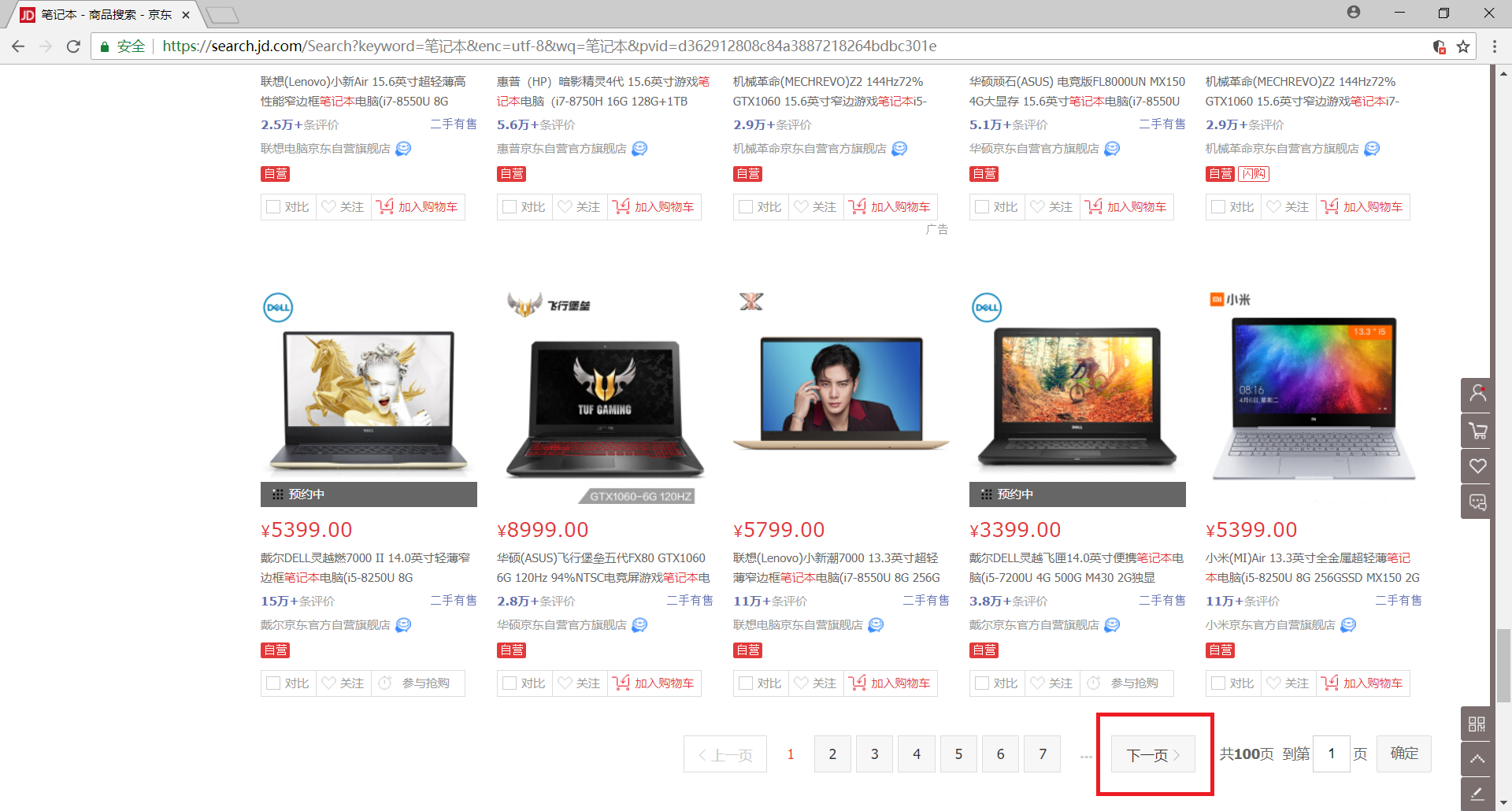
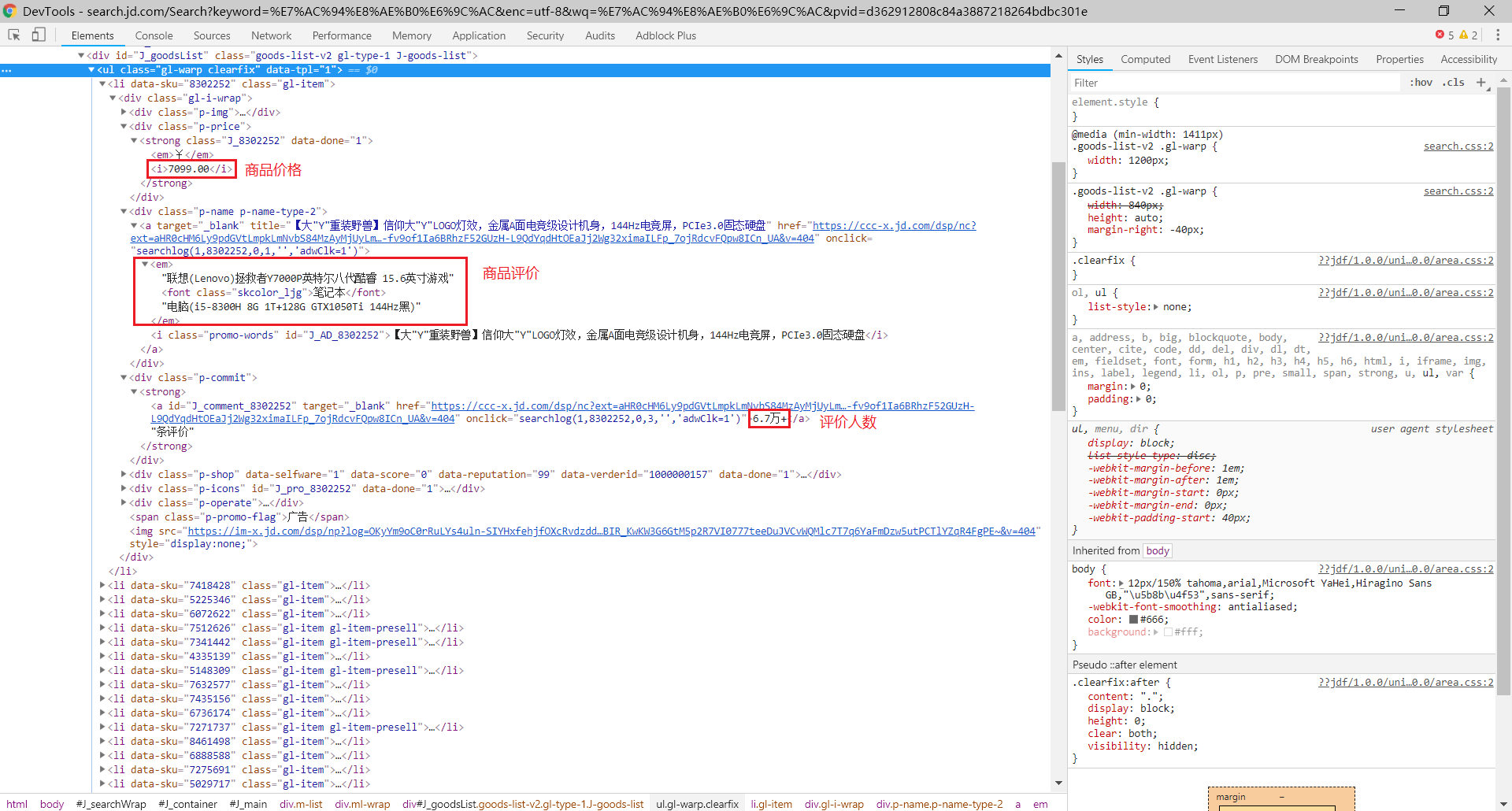
接下来我们就需要解析每一个网页来获取我们需要的数据了,包括商品名称、商品价格和评论人数,我们发现每一项商品的信息包含在一个li标签里面,那么我们就可以直接使用selenium来选择元素,再使用元素的text属性获取文本值,而这个就是我们需要的数据了
- 商品价格:
browser.find_elements_by_xpath('//div[@class="gl-i-wrap"]/div[2]/strong/i') - 商品名称:
browser.find_elements_by_xpath('//div[@class="gl-i-wrap"]/div[3]/a/em') - 评论人数:
browser.find_elements_by_xpath('//div[@class="gl-i-wrap"]/div[4]/strong')
二、编码实现
好了,分析过程很简单,基本思路是使用selenium模拟浏览器的行为,下面是代码实现(只需要短短的几十行代码就可以实现了)
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import json
import csv
count = 0
file_format = input('请输入文件保存格式(txt、json、csv):')
while file_format!='txt' and file_format!='json' and file_format!='csv':
file_format = input('输入错误,请重新输入文件保存格式(txt、json、csv):')
if file_format=='txt' :
file = open('Jd.txt','w',encoding='utf-8')
elif file_format=='json' :
file = open('Jd.json','w',encoding='utf-8')
elif file_format=='csv' :
file = open('Jd.csv','w',encoding='utf-8',newline='')
writer = csv.writer(file)
browser = webdriver.Chrome()
browser.implicitly_wait(10)
wait = WebDriverWait(browser,10)
start_url = 'https://search.jd.com/Search?keyword=%E7%AC%94%E8%AE%B0%E6%9C%AC&enc=utf-8&wq=%E7%AC%94%E8%AE%B0%E6%9C%AC&pvid=e8604bd75a024b31a9aff06b803229ea'
browser.get(start_url)
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
print('Processing')
while True :
try:
symbol = wait.until(EC.presence_of_element_located((By.XPATH,'//div[@class="gl-i-wrap"]/div[2]/strong/i')))
symbol = wait.until(EC.presence_of_element_located((By.XPATH,'//div[@class="gl-i-wrap"]/div[3]/a/em')))
symbol = wait.until(EC.presence_of_element_located((By.XPATH,'//div[@class="gl-i-wrap"]/div[4]/strong')))
#symbol = wait.until(EC.presence_of_element_located((By.XPATH,'//div[@class="gl-i-wrap"]/div[5]/span/a')))
except selenium.common.exceptions.TimeoutException:
continue
else:
prices = browser.find_elements_by_xpath('//div[@class="gl-i-wrap"]/div[2]/strong/i')
names = browser.find_elements_by_xpath('//div[@class="gl-i-wrap"]/div[3]/a/em')
commits = browser.find_elements_by_xpath('//div[@class="gl-i-wrap"]/div[4]/strong')
#shops = browser.find_elements_by_xpath('//div[@class="gl-i-wrap"]/div[5]/span/a')
if file_format=='txt' :
for i in range(len(prices)):
count += 1
print(count)
file.write('--------------------'+str(count)+'--------------------\n')
file.write('price:')
file.write(prices[i].text)
file.write('\n')
file.write('name:')
file.write(names[i].text)
file.write('\n')
file.write('commit:')
file.write(commits[i].text)
file.write('\n')
#file.write('shop:')
#file.write(shops[i].text)
#file.write('\n')
elif file_format=='json' :
for i in range(len(prices)):
count += 1
print(count)
item = {}
item['price'] = prices[i].text
item['name'] = names[i].text
item['commit'] = commits[i].text
#item['shop'] = shops[i].text
json.dump(item,file,ensure_ascii = False)
elif file_format=='csv' :
for i in range(len(prices)):
count += 1
print(count)
item = {}
item['price'] = prices[i].text
item['name'] = names[i].text
item['commit'] = commits[i].text
#item['shop'] = shops[i].text
for key in item:
writer.writerow([key, item[key]])
try:
next_page = browser.find_element_by_xpath('//a[@class="pn-next" and @onclick]')
except selenium.common.exceptions.NoSuchElementException:
break
else:
next_page.click()
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
file,close()
browser.quit()
print('Finished')写在后面的话 :虽然使用selenium模拟浏览器爬取动态网页十分方便,可是由于selenium需要启动浏览器来辅助工作,所以其运行速度确实比较慢,所以下一篇文章我们将要学习PhantomJS无界面浏览器来加快爬取速度