学了网络爬虫两周了,还是比较喜欢用网页级库requests,很灵活方便,scrapy网站级面向对象库,还不熟悉,可能是原来c++学习面向对象就没学好,对面向对象编程还没理解好吧...两周中爬了淘宝,京东,天猫(爬取失败,反爬虫把我这种新手难倒了,登录验证就卡死),爬取搜狗批量下载输入的类型图片...用beautifulsoup,正则表达式的理解更加深入,慢慢有自己的认知和经验。
进入正题。。。这次爬取的是京东商品价格和名称。
一:老规矩分析京东方接口:打开京东页面,随便搜索一个东西,复制下图的中红色框里面网址
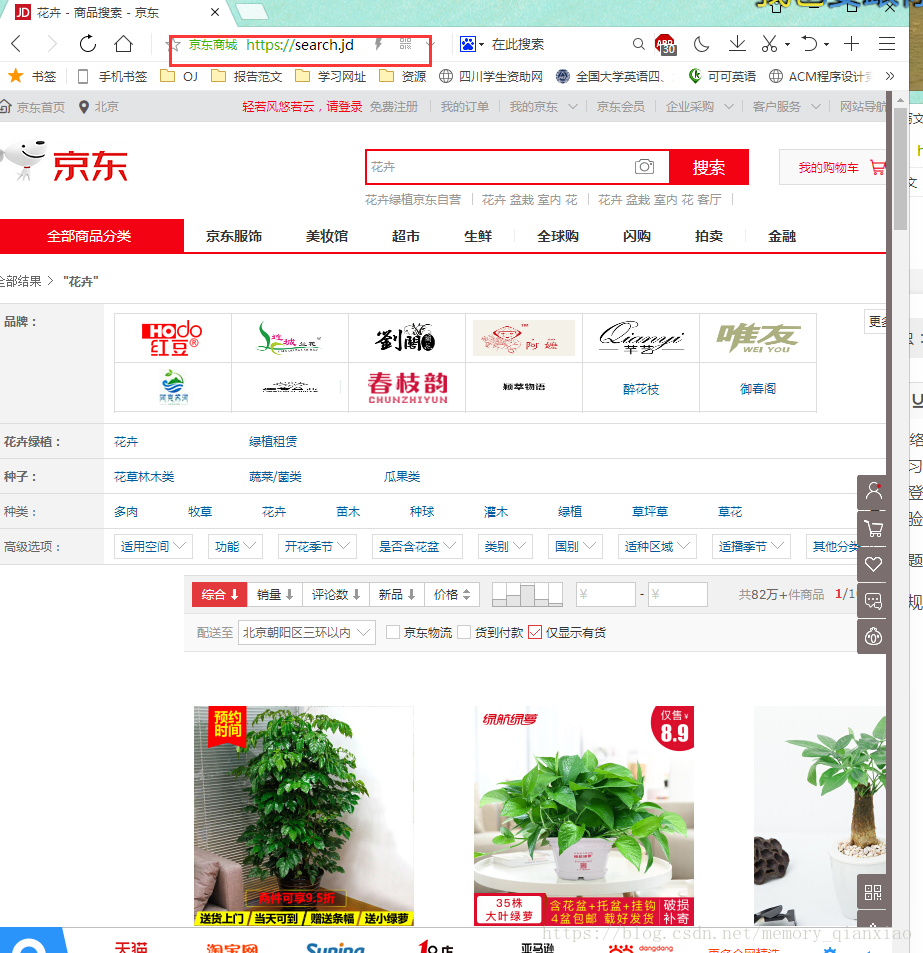
第一页:https://search.jd.com/Searchkeyword=%E8%8A%B1%E5%8D%89&enc=utf8&wq=%E8%8A%B1%E5%8D%89&pvid=f25c9779fce841d6982ce59edcadab51
第二页:https://search.jd.com/Search?keyword=%E8%8A%B1%E5%8D%89&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E8%8A%B1%E5%8D%89&stock=1&page=3&s=54&click=0
第三页:https://search.jd.com/Search?keyword=%E8%8A%B1%E5%8D%89&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E8%8A%B1%E5%8D%89&stock=1&page=5&s=107&click=0
可以发现搜索接口是:https://search.jd.com/Search?keyword= 翻页是&page= 可以发现京东的页面是按照2的递增的,第一页就是1,第二页3,第三页5....经笔者尝试,还需要向网址中增加&enc-utf-8也就是上面网址标红发地方,才能进入成功。不像淘宝可以直接接口加翻页就可以。
所以最终的接口方式是:
https://search.jd.com/Search?keyword=(输入关键词)+&enc-utf-8+&page=(页面号)然后定义4个函数:分别是获取每一页品,返回Text,然后解析网页,提取我们需要的东西,然后存excel,主函数
def getHtmlText(url,headers):def parserPage(infoList,html):def Write_Excel(ls,name):def main():接下来就说其中一些爬取过程中重点吧,分析网页按住F12我们可以发现,把鼠标对着每个li标签,发现阴影都对着每个商品,说明,每个商品都对应li标签
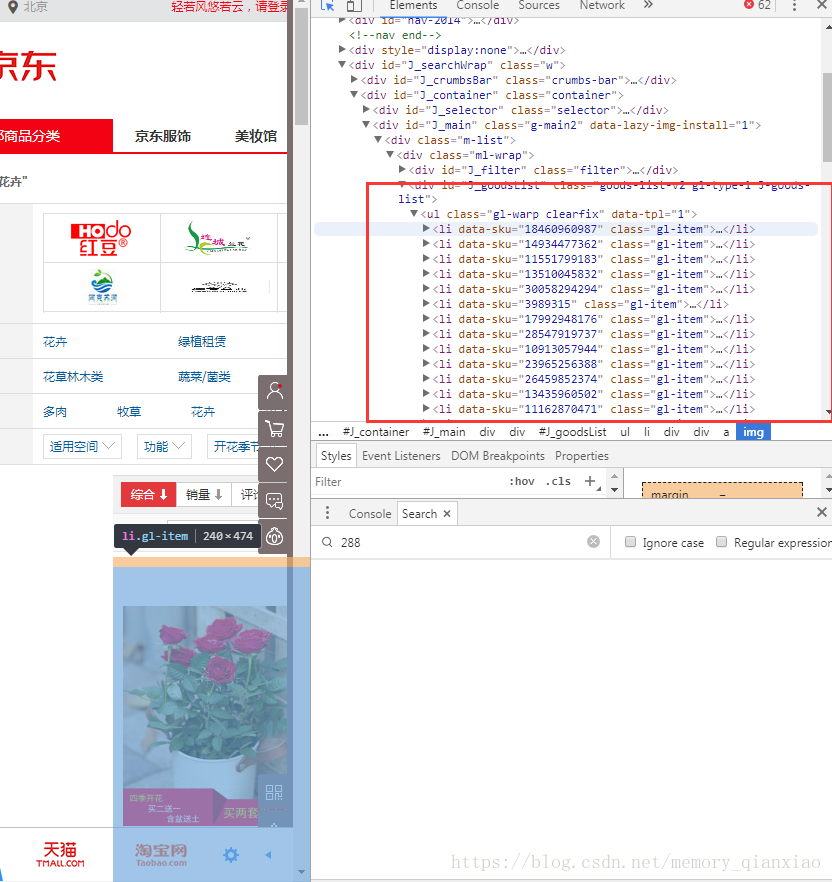
然后分析网页:可以发现商品名称在a标签中的 title属性中,价格是div 标签中i标签的string类型。
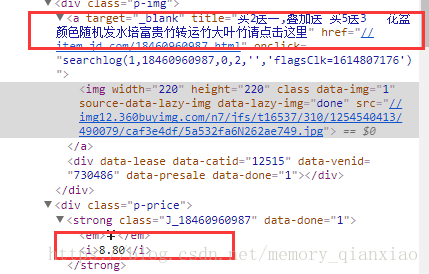
因为是新手,提取不太熟练,所以也是经过不断尝试,网页解析提取的代码是:
def parserPage(infoList,html):
soup=BeautifulSoup(html,"html.parser")
goods=soup.find_all('li','gl-item')
try:
for good in goods:
name=good.a["title"]
price=good.find('div','p-price').i.string[:15]
infoList.append([price,name])
print("网页解析成功!")
except:
print("网页解析失败")接下来就说下存入Excel表,,需要用第三方库xlwt,没有的可以直接通过pip install xlwt。
我们需要先把头标题存进去,表格也是按照矩阵从0,0开始的。然后在一行一行的存入数据。xlwt的用法请点击传送门:xlwt用法
def Write_Excel(ls,name):
print("正在写入Exce表:")
workbook=xlwt.Workbook(encoding='utf-8')
name="京东"+name+"商品信息"
table=workbook.add_sheet(name)
# table.col(3).width=256*20
value=["序号","价格","商品名称"]
for i in range(len(value)):
table.write(0,i+1,value[i])
for i in range(len(ls)):
value=[i+1,float(ls[i][0]),ls[i][1]]
for j in range(3):
table.write(i+1,j+1,value[j])
workbook.save(name+'.xls')
print("写入Excel表成功!请在本程序下同一路径下寻找excle")因为我们我们列表是二维数据,所以存入excel是一行一行的存,先行后列,学过c语言估计就更能明白了。
我们来看下效果。
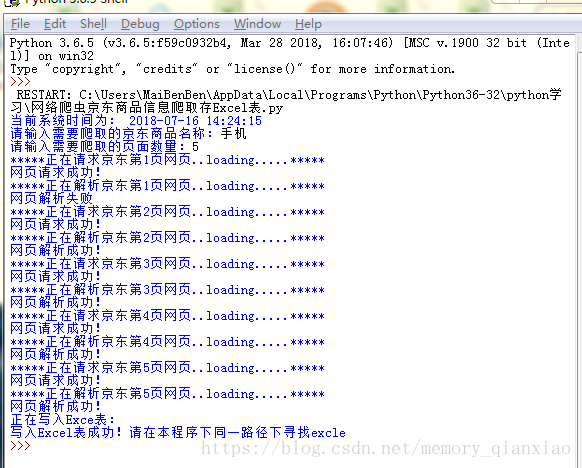
我用是pythonIDLE,IDLE是不能看到excel表的,所以复制运行代码的idle路径,在我的电脑里面粘贴路径,就会发现excel。
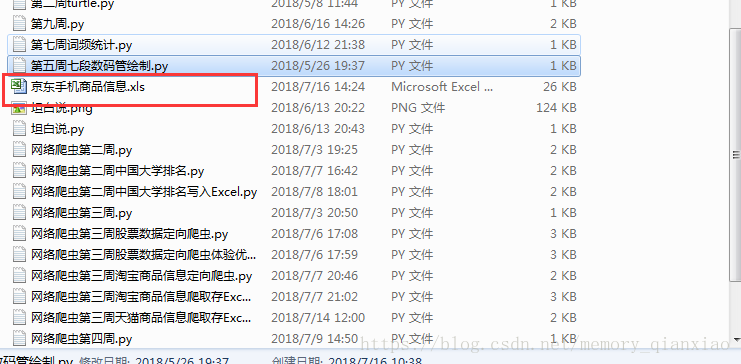
我们就看看我们抓取的成果吧!

很成功!
idle查看excel要复制路径有点麻烦,我们可以直接打包成无需环境的exe文件,保存的excel就会在运行excel 的地方,很方便!
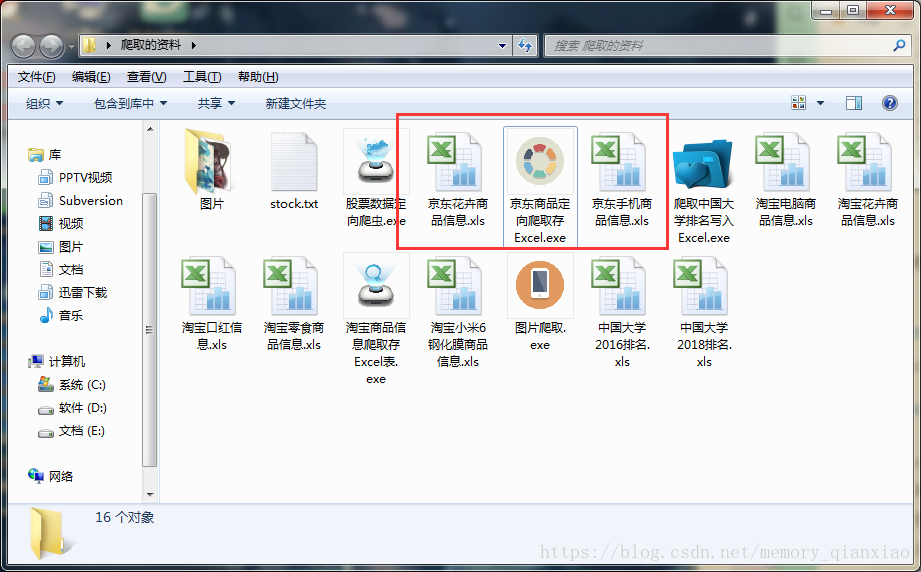
接下来就放一份源代码:供大家学习参考!切记超大量爬取数据。
#https://search.jd.com/Search?keyword=花卉&enc=utf-8&page=7
import requests,re,xlwt,datetime
from bs4 import BeautifulSoup
def getHtmlText(url,headers):
try:
r=requests.get(url,headers=headers,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
print("网页请求成功!")
return r.text
except:
print("网页请求失败")
def parserPage(infoList,html):
soup=BeautifulSoup(html,"html.parser")
goods=soup.find_all('li','gl-item')
try:
for good in goods:
name=good.a["title"]
price=good.find('div','p-price').i.string[:15]
infoList.append([price,name])
print("网页解析成功!")
except:
print("网页解析失败")
def Write_Excel(ls,name):
print("正在写入Exce表:")
workbook=xlwt.Workbook(encoding='utf-8')
name="京东"+name+"商品信息"
table=workbook.add_sheet(name)
# table.col(3).width=256*20
value=["序号","价格","商品名称"]
for i in range(len(value)):
table.write(0,i+1,value[i])
for i in range(len(ls)):
value=[i+1,float(ls[i][0]),ls[i][1]]
for j in range(3):
table.write(i+1,j+1,value[j])
workbook.save(name+'.xls')
print("写入Excel表成功!请在本程序下同一路径下寻找excle")
def main():
print("当前系统时间为:",datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
start_url="https://search.jd.com/Search?keyword="
goods=input("请输入需要爬取的京东商品名称:")
num=int(input("请输入需要爬取的页面数量:"))
infoList=[]
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5514.400 QQBrowser/10.1.1660.400"}
for i in range(1,num+1):
try:
url=start_url+goods+"&enc=utf-8&page="+str(i*2)
print("*****正在请求京东第%d页网页..loading.....*****"%i)
html=getHtmlText(url,headers)
print("*****正在解析京东第%d页网页..loading.....*****"%i)
parserPage(infoList,html)
except:
continue
#print(infoList)
Write_Excel(infoList,goods)
main()