版权声明:本文为博主原创文章,转载请注明出处。 https://blog.csdn.net/u012319493/article/details/86943543
登录
如何跳过登录
- 安装 selenium。
pip install selenium

2. 安装对应 chrome 版本的 selenium webdriver。
https://www.cnblogs.com/nancyzhu/p/8589764.html
-
为 chromedriver.exe 添加环境变量。
-
生成登录爬虫。
scrapy genpider login https://login.taobao.com/member/login.jhtml?from=taobaoindex&f=top&style=&sub=true&redirect_url=https%3A%2F%2Fi.taobao.com%2Fmy_taobao.htm%3Fspm%3D2013.1.1997525045.1.73822f0d5Z0FNu

5. 使用 selenium。
from selenium import webdriver
browser = webdriver.Chrome() # 启动 chrome 浏览器
# 访问淘宝登录页面
browser.get("https://login.taobao.com/member/login.jhtml?redirectURL=http%3A%2F%2Fbuyertrade.taobao.com%2Ftrade%2Fitemlist%2Flist_bought_items.htm%3Fspm%3Da21bo.2017.1997525045.2.5af911d904ZhbN")
弹出如下界面:
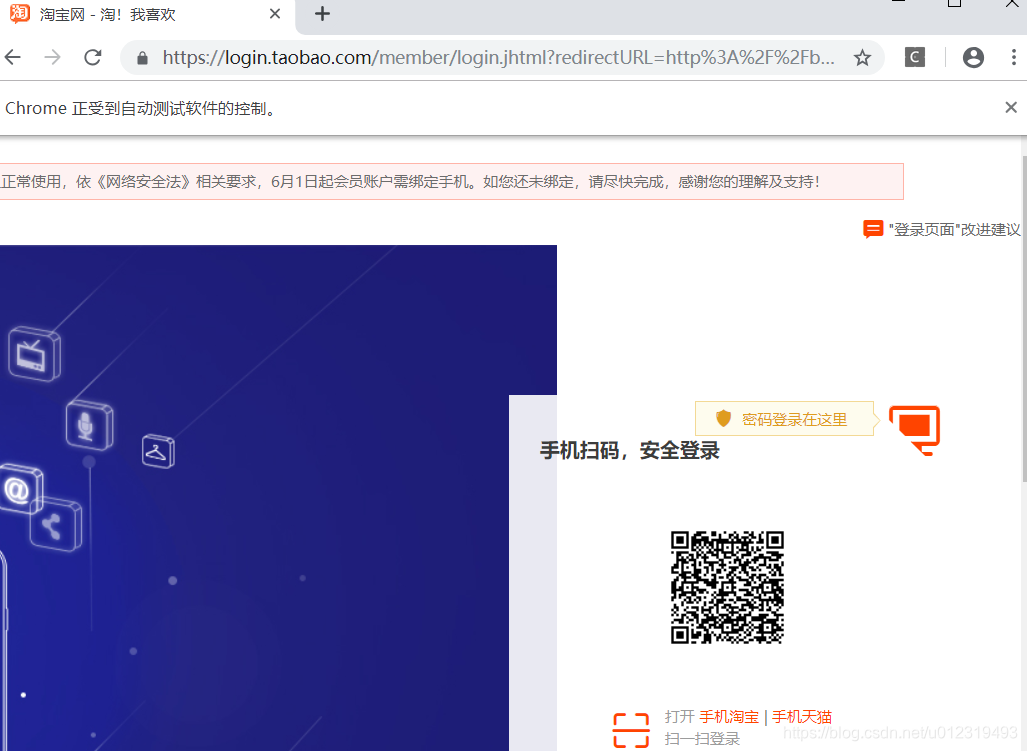
如何登录
跳出来的界面需要扫描登录,接下来切换到账号密码登录。
- 找到切换到账号密码登录。
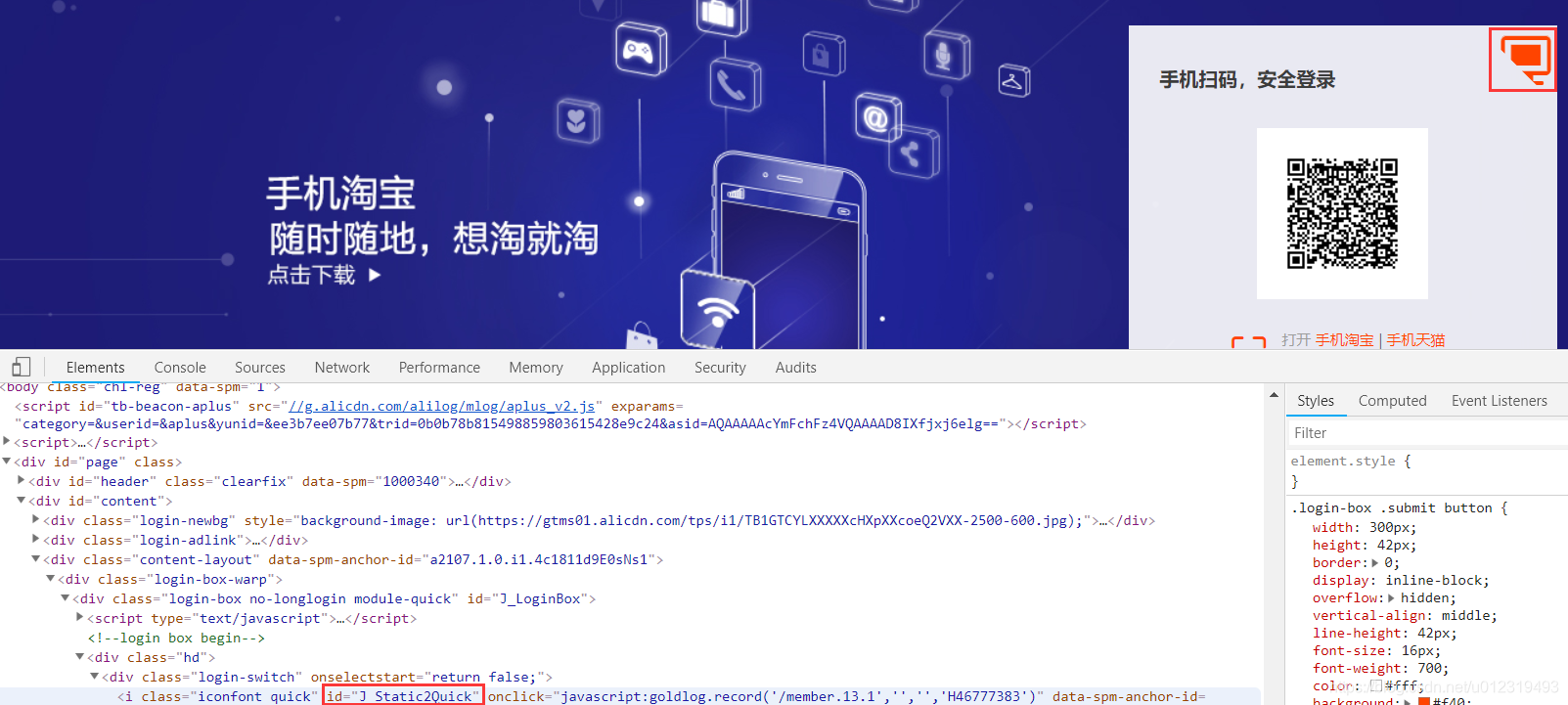
browser.find_element_by_id("J_Quick2Static").click()
- 得到用户名、密码输入框id。
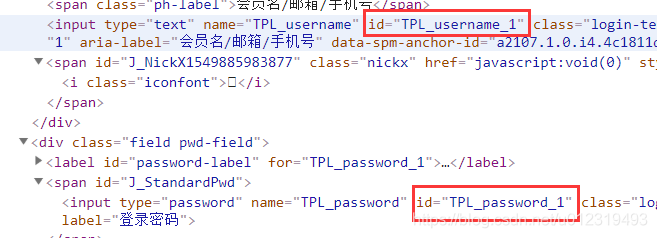
browser.implicitly_wait(10) # 睡眠 10s
browser.find_element_by_id("TPL_username_1").send_keys("aaa")
browser.find_element_by_id("TPL_password_1").send_keys("bbb")
- 点击登录按钮

browser.find_element_by_id("J_SubmitStatic").click()
结果:
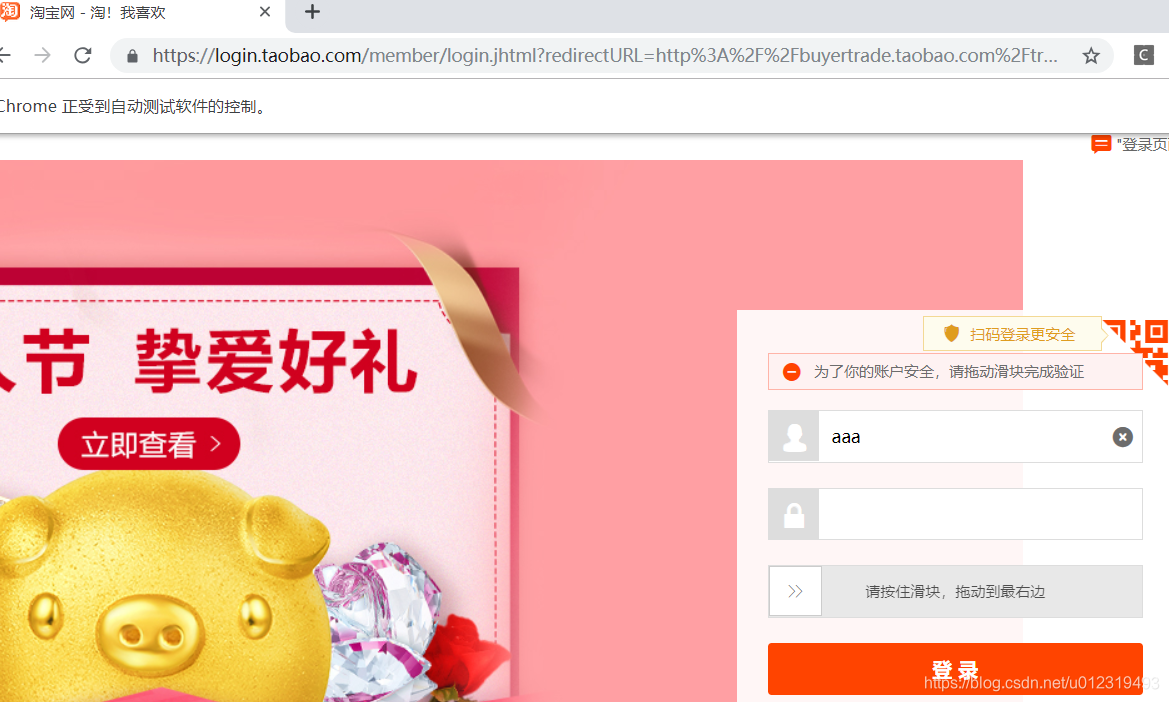
可见,还需要拖动滑块。
但是手动滑动滑块后登录仍然失败,也许一旦被认定是爬虫,就一定会失败。
综上,login.py 中代码如下
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver
class LoginSpider(scrapy.Spider):
name = 'login'
allowed_domains = ['login.taobao.com']
start_urls = ['https://login.taobao.com/member/login.jhtml?from=taobaoindex&f=top&style=&sub=true&redirect_url=https%3A%2F%2Fi.taobao.com%2Fmy_taobao.htm%3Fspm%3D2013.1.1997525045.1.73822f0d5Z0FNu']
def parse(self, response):
browser = webdriver.Chrome() # 启动 chrome 浏览器
# 访问淘宝登录页面
browser.get("https://login.taobao.com/member/login.jhtml?from=taobaoindex&f=top&style=&sub=true&redirect_url=https%3A%2F%2Fi.taobao.com%2Fmy_taobao.htm%3Fspm%3D2013.1.1997525045.1.73822f0d5Z0FNu")
browser.find_element_by_id("J_Quick2Static").click() # 切换到账号密码登录界面
browser.implicitly_wait(10) # 睡眠 10 s
browser.find_element_by_id("TPL_username_1").send_keys("aaa") # 输入用户名
browser.find_element_by_id("TPL_password_1").send_keys("bbb") # 输入密码
browser.find_element_by_id("J_SubmitStatic").click() # 点击登录按钮
以下是为了避免被认为是爬虫做了一些处理,但没起作用。
避免被认为是爬虫
UserAgent
不断变换 UserAgent,可提高爬虫识别难度。
安装:
pip install fake-useragent

middlewares.py 中添加:
from fake_useragent import UserAgent
class RandomeUserAgentMiddleware(object):
def __init__(self, crawler):
super(RandomeUserAgentMiddleware, self).__init__()
self.ua = UserAgent()
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_request(self, request, spider):
request.headers.setdefault("User-Agent", self.ua.random)
#print("request.headers:" + str(request.headers))
settings.py 中修改:
DOWNLOADER_MIDDLEWARES = {
'spider.middlewares.SpiderDownloaderMiddleware': 543,
'spider.middlewares.RandomeUserAgentMiddleware': 1,
}
IP 代理
在 middlewares.py 中添加:
class IPAgentMiddleware(object):
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_request(self, request, spider):
request.meta['proxy'] = "113.240.225.164:8080" # IP 代理
settings.py 中添加:
DOWNLOADER_MIDDLEWARES = {
'spider.middlewares.SpiderDownloaderMiddleware': 543,
'spider.middlewares.RandomeUserAgentMiddleware': 1,
'spider.middlewares.IPAgentMiddleware': 2,
}
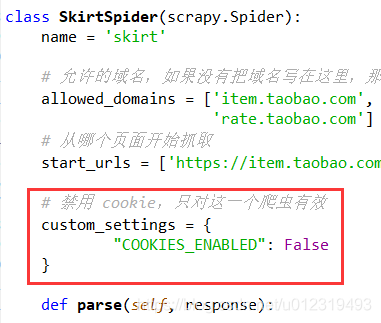
禁用 cookie
在不需要登录的情况下,禁用 cookie 后,可提高爬虫识别难度。
custom_settings = {
"COOKIES_ENABLED": False
}