版权声明:本文为博主原创文章,转载请附上博文链接! https://blog.csdn.net/Daker_Huang/article/details/86736072
现如今深度学习最常用的有三大框架:caffe、tensorflow、torch/pytorch。基于这三大深度学习框架我们可以非常简单的实现很多功能,如图像分类、对象检测、图像分割、预测…
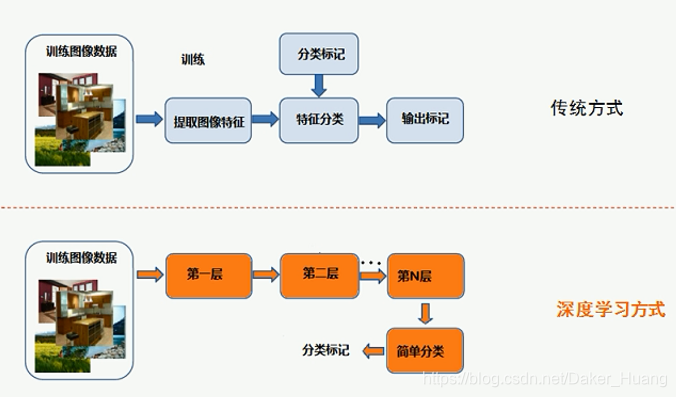
接下来我们就来学习一下在opencv中怎么使用深度神经网络进行图像分类。
如果OpenCv已经编译过了扩展模块了,已经有DNN模块了,如果没有编译过的话,据说在opencv3.3之后就已经在release版本中了,也不需要编译。但之前的可能需要编译一下。
这里以googlenet在caffe框架下训练好的模型为例,当然,也可以使用官网的tensorflow,torch等训练好的模型,包括自己训练的模型。这里需要注意一点,它们的后缀名都不同,所以用的时候需要区分清楚。

第一个文件是训练模型,第二个是描述文件,第三个是imagenet标签文件。以上文件是官网给出的,支持1000种物体的分类,涵盖了生活中大部分的物体。
#include<opencv2/opencv.hpp>
#include<opencv2/dnn.hpp>
#include<iostream>
using namespace cv;
using namespace std;
using namespace cv::dnn;
string caffe_model_file = "D:/test/googlenet_caffe/bvlc_googlenet.caffemodel"; //训练文件
string caffe_txt_file = "D:/test/googlenet_caffe/bvlc_googlenet.prototxt"; //描述文件
string labels_txt_file = "D:/test/googlenet_caffe/synset_words.txt"; //标签文件
vector<string> readClassLabels();//定义读取文件每行的函数
int main(int argc, char** argv)
{
Mat src = imread("D:/test/cat.jpg");
if (src.empty())
{
cout << "图片未找到!!!" << endl;
return -1;
}
//imshow("input image", src);
vector<string> labels = readClassLabels();
Net caffe_net = readNetFromCaffe(caffe_txt_file, caffe_model_file);
if (caffe_net.empty())
{
return -1;
}
Mat inputblob = blobFromImage(src, 1.0, Size(224, 224), Scalar(104, 117, 123)); //将读进来的图像转为blob
Mat prob;
caffe_net.setInput(inputblob, "data");//第一层是data
prob=caffe_net.forward("prob");
Mat Matprob = prob.reshape(1, 1); //维度变成1*1000
double Probability; //最大相似度
Point classindex;
minMaxLoc(Matprob, NULL, &Probability, NULL, &classindex);
int Nameindex = classindex.x; //最大相似度对应的索引
cout<<"Probability:"<< Probability*100<<"%"<< endl;
cout << "NameValue:" << labels.at(Nameindex) << endl;
putText(src, labels.at(Nameindex), Point(20, 20), FONT_HERSHEY_SIMPLEX, 1.0, Scalar(0, 0, 255), 2, 8);
imshow("result image", src);
waitKey(0);
return 0;
}
vector<string> readClassLabels()
{
vector<string>classNames; //存放name
ifstream fp(labels_txt_file);//读入文件
if (!fp.is_open())
{
cout << "文件未找到!!!" << endl;
exit(-1);
}
string name;
while (!fp.eof()) //当文件没有读到尾部
{
getline(fp, name); //读取文件每一行,从fp中读取,将结果放在name里面去
if (name.length())
{
classNames.push_back(name.substr(name.find(" ") + 1)); //从空格后面开始取字符
}
}
fp.close();//关闭输入输出流
return classNames;
}
上面代码中的Net caffe_net = readNetFromCaffe(caffe_txt_file, caffe_model_file);是专门读取caffe模型的,如果是tensorflow和torch,则分别替换为如下语句:
readNetFromTensorflow();
readNetFromTorch()
运行结果:
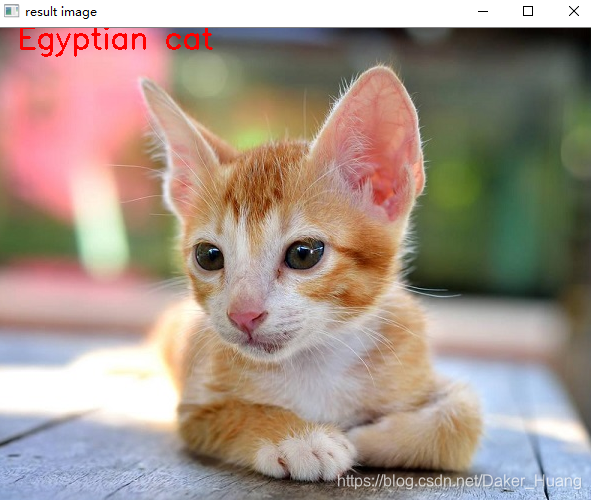

可以看到,相似度最高大概为68%,而这68%就是cat,而图片也是cat,所以结果还是比较准确的。
我们再换一张试试:
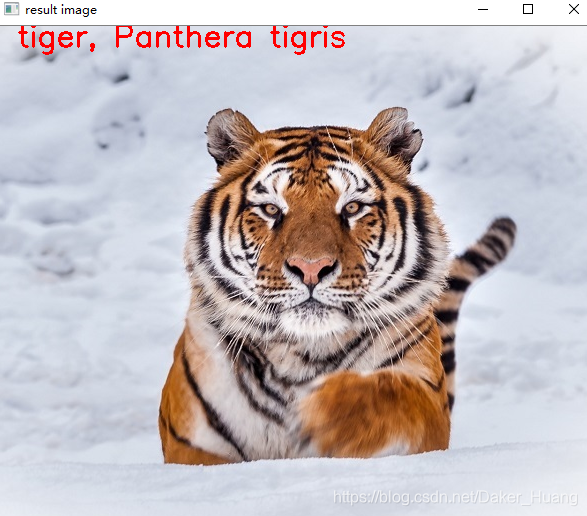

可以看到,这个相似度就达到了96%,非常高,也非常准确。
视频就是图片一帧一帧的播放的,我们也可以在视频中检测。具体代码如下:
#include<opencv2/opencv.hpp>
#include<opencv2/dnn.hpp>
#include<iostream>
using namespace cv;
using namespace std;
using namespace cv::dnn;
string caffe_model_file = "D:/test/googlenet_caffe/bvlc_googlenet.caffemodel"; //训练文件
string caffe_txt_file = "D:/test/googlenet_caffe/bvlc_googlenet.prototxt"; //描述文件
string labels_txt_file = "D:/test/googlenet_caffe/synset_words.txt"; //标签文件
vector<string> readClassLabels();//定义读取文件每行的函数
int main(int argc, char** argv)
{
Mat frame;
VideoCapture capture(1);
//Mat src = imread("D:/test/cat.jpg");
if (!capture.isOpened())
{
cout << "摄像头未找到!!!" << endl;
return -1;
}
//imshow("input image", src);
vector<string> labels = readClassLabels();
Net caffe_net = readNetFromCaffe(caffe_txt_file, caffe_model_file);
if (caffe_net.empty())
{
return -1;
}
Mat inputblob;
Mat prob, Matprob;
double Probability; //最大相似度
Point classindex;
while (capture.read(frame))
{
inputblob = blobFromImage(frame, 1.0, Size(224, 224), Scalar(104, 117, 123)); //将读进来的图像转为blob
caffe_net.setInput(inputblob, "data");//第一层是data
prob = caffe_net.forward("prob");
Matprob = prob.reshape(1, 1); //维度变成1*1000
minMaxLoc(Matprob, NULL, &Probability, NULL, &classindex);
int Nameindex = classindex.x; //最大相似度对应的索引
cout << "Probability:" << Probability * 100 << "%" << endl;
cout << "NameValue:" << labels.at(Nameindex) << endl;
putText(frame, labels.at(Nameindex), Point(20, 20), FONT_HERSHEY_SIMPLEX, 1.0, Scalar(0, 0, 255), 2, 8);
imshow("result image", frame);
char c = waitKey(5);
if(c==27)
{
break;
}
}
waitKey(0);
return 0;
}
vector<string> readClassLabels()
{
vector<string>classNames; //存放name
ifstream fp(labels_txt_file);//读入文件
if (!fp.is_open())
{
cout << "文件未找到!!!" << endl;
exit(-1);
}
string name;
while (!fp.eof()) //当文件没有读到尾部
{
getline(fp, name); //读取文件每一行,从fp中读取,将结果放在name里面去
if (name.length())
{
classNames.push_back(name.substr(name.find(" ") + 1)); //从空格后面开始取字符
}
}
fp.close();//关闭输入输出流
return classNames;
}