前言
当简单的了解了深度神经网络和卷积神经网络后,我们会发现两者之间是有着一些联系的,其实两者的原理都是利用已经处理好的数据集来对网络进行逐步的训练,从而使它更加贴合真实的情况,但是,两者之间也是有点不同的,卷积和池化,就是在DNN的基础上加载进来的,那么为什么要引入这两个概念,因为,在日常生活中,我们不可能碰到像mnist这种已经处理的十分友好的数据集,大多数情况我们面对的就是复杂的图片,那么对于更加复杂的图片,我们就需要更加高级的方法去处理,不是说DNN处理不了,而是不合适.
那么卷积神经网络就给了我们一个很好的选择,因为在计算机领域,最优解是每个人都在追求的,接下来我们将深度剖析DNN实现过程
深度神经网络(DNN)
接下来我们以mnist数据集作为例子,给大家详细讲解深度神经网络的实现过程,
介绍mnist数据集
mnist数据集是一个入门级别的计算机视觉数据集,它包含了各种各样的手写数字照片,请看下图

我们主要介绍DNN的实现过程,所以在这里,我们只是简单的介绍一下mnist数据集
数据集被分为两个部分,60000行的训练数据和10000行的测试数据集,这样大家可能还是有点不太理解,我这样来说,我们将机器想象成一个人的大脑,当我们要去学习某件事物的时候,比如我们要学会做某一道数学题,那么在会做之前,我们是不是得做大量的练习,从而发现其中的规律,而这些大量的练习题,就是所谓的训练数据,现在,我们也已经做了大量的数学题了,考试要来了,那么,考试题就是所谓的测试数据集,因为你得测试一下你是否真的掌握了这道题,神经网络其实就是模拟了人脑的学习过程.
每一个数据单元有两部分组成,一张包含手写数字的图片和一个对应的标签,每一张图片包含了28*28像素,我们一般用一个二维数组来表示(可以看上面的图),当我们在计算的时候,我们会把这个28*28传递二维数组变成一个1*784的一维数组,在这784个值中存在灰度值,这是以后在计算的时候所需要的最重要的东西
了解构建深层网络的步骤(以训练手写数字为例子)
很多人就问我,你说的这些原理我都懂,但是具体如何实现这个网络,而且为什么要这么做,这些是我关注的点,那小编接下来将以风趣幽默的方式让大家记住如何构建深度神经网络
第一步:利用前向传播算法得出一个结果Y
很多人在这里就懵逼了,什么是前向传播算法,不着急,我们先来一个图,有助于理解
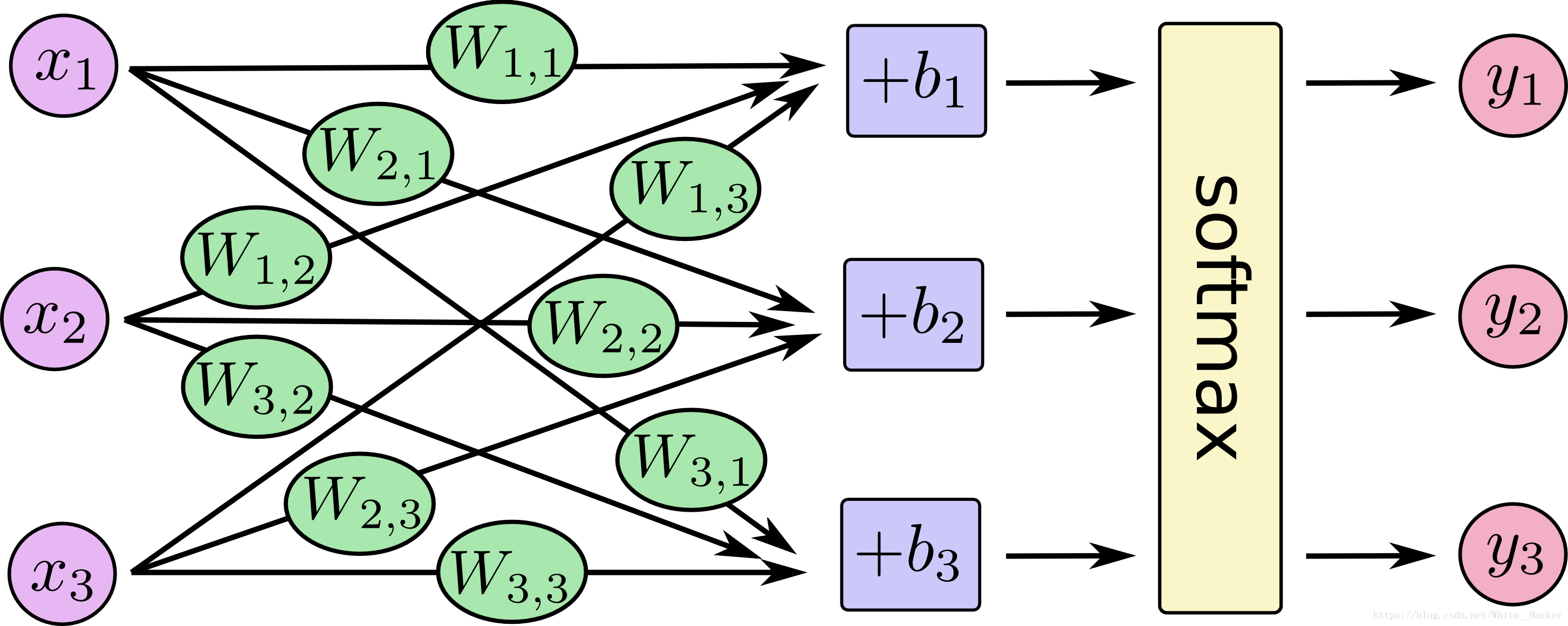

这时候大家会看到一个网状的图,很丑,但很温柔,在这里,大家一定要get几个重要的点,因为,这就是前向传播算法的精髓,首先,请大家注意这个W和b,W代表权值,b代表偏置,我相信大家都能理解这两个概念,要是理解不了,对不起,你不适合深度学习,点击你右上角的叉叉,bye,好了好了,不开玩笑了,W(权重),在这里我解释一下,所谓权重我们可以这样理解,就是你的每个东西在你的心里都有一个重要度,这个重要度就是权重,对于mnist来说灰度值就是用来衡量权重的重要参考,不要问我什么是灰度值,去点叉叉吧,b(偏置),这个你可以这样理解,任何事物都要允许有无关紧要的人或者事存在,虽然对您没用,但是还得存在,很讨厌,但是没办法,这就是偏置,那么现在我们就可以根据图形得出一个公式了那就是请看下图

x就是我们要进去的测试数据,y就是我们要得出的结果,这时候有人问我,那x输入什么,y又输出什么,其实刚才我们已经说了,我们x输入的是一个二维数组,每一个二维数组代表着不同的图片,y这个输出也是一个数组,你可以理解成一个label,这个labe就是0-9这是个数字,输入一张图片,网络进行判断,然后将它分类到某一个label中,这时候又有人问了,什么是softmax,问题怎么这么多,这个我们后面再讲,好了,前向传播算法大概就解释清楚了,这里牵扯了很多的矩阵运算,线性代数不好的同学直接叉叉吧.
又有一个同学问问题了,他说:为什么这个函数是个线性函数,你这样写是不是有点特殊,这个问题是问的非常好的,get到了一个很重要的点------去线性化,在日常生活中,我们所碰到的问题一般是不能用线性函数来表示的,那么我们就得用一点花里胡哨的函数来处理问题,在这里我给大家介绍三种花里胡哨,不对不对,去线性化的函数
1.relu函数
2.sigmoid函数
3.tanh函数
在这里我们不深究这三个函数的性质,在以后的博客中我会具体介绍这三个函数的.
好了,现在我们已经去线性化了,也前向传播了,接下来我们要干什么了呢?
第二步:计算损失函数
emmmmm,是不是又听不懂了,那我们举个例子,你在学习如何去解一道数学题,你做啊做啊终于做出来了,那么接下来你会做什么呢,毫无疑问------验证答案,因为你要知道你做的是对的还是错的,那么,计算损失函数就是对答案的过程,通过前向传播,你得到了你的答案,而在数据集中有我的标准答案,那么现在我们就要比较,你的答案和标准答案到底差了多少,下面我们提供一个比较的方法
交叉熵
交叉熵最开始是信息论的概念(我知道你们不知道什么是信息论,哈哈哈哈),在神经网络中,交叉熵主要刻画的是两个概率分布之间的距离给定两个概率分布,p和q,通过q来表示p的交叉熵为
H(p,q) = -∑ p(x) log q(x)
p就是通过前向传播算法算出的结果
q就是标准答案
具体的关于交叉熵的内容,请关注小编的另一篇博客深度学习经典损失函数
第三步:反向传播与梯度下降
当我们发现自己的数学题答案和标准答案之间是存在一定的距离的时候,接下来我们要做的是不是就是再次将这道题做一遍,然后缩小和标准答案之间的距离,深度神经网络和做数学题的方法是一样的,接下来我们给大家介绍利用反向传播对模型进行调整
反向传播其实我们从他的名字就可以知道它是干嘛用的,就是返回去,再次进行计算,在反向传播中,我们最常用的方法就是梯度下降法,我们举一个简单的例子,请看下图

我们可以看到,这是一个很简单的二次函数,我们用x代表网络中的参数的值,y表示损失函数,那么,顾名思义,当x取到某一值的时候,要让y最小,也就是损失函数最小,那么此时我们就认为,在这一点,学习是最成功的,那么问题来了,我刚开始选的x是随机值,我也不知道x在哪里,这时候怎么办呢,我们就会想到,既然要让y最小,那么x的梯度必须越来越小,这样才能出现y值慢慢下降的过程,其实在这个下降的过程就是梯度下降,当然又有那种杠精同学出来了问了,又不是所有的函数都会像二次函数这么简单,一下就能判断出来,当然,小编有专门治这种杠精的办法,不好意思,随机梯度下降法了解一波
随机梯度下降,就是用来处理复杂函数用的,他的原理就是随机抽取一个batch,然后去寻找这个最小值,在极小值中寻找最小值,最后学习成功.然后我们在强调一点,梯度下降,那我们到底每次下降多少合适一点呢,下降的多了,可能我们会越过最小值,下降的少了,就会效率低,这时候不要慌,我们提供一种衰减的方法,指数衰减法,具体如何衰减,我会在另外一篇博客中给大家详细介绍.
第四步:使用softmax函数进行输出
在前面几步中,我们已经完成了一轮比较,接下来,我们要做的就是不断的重复,迭代,俗话说的好,成功,就是不断的重复,在经过了大量的重复训练后,终于,我们的模型算是训练好了,这时候我们有个问题,训练好了,怎么输出啊,我不可能输出一个矩阵吧,这样谁看的懂,这时候我们就会用到softmax函数,简单来说这个东西是把矩阵变成概率分布的函数要是对这个函数感兴趣,请期待小编的另外一篇博客softmax函数详解(虽然现在还没写....)
总结
以上就是深度神经网络构建的一个大体过程,其中有很多的细节,小编没有展开讲,毕竟这个是给入门深度学习的人看的,要是对于深度学习有极大的兴趣,请多多关注小编的博客,在接下来,我会给大家来点真正的超级干货,就是那种看着就很厉害的那种,各种数学公式满天飞的那种,当然还有你们最最喜欢的代码哦,所以,关注我,让我们一起deeplearning! ! !