ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
摘要
目前,神经网络的架构设计主要是由计算复杂度的间接度量,即FLOPs来指导的。然而,速度,也取决于其他因素,如内存访问成本和平台特性。而不仅仅是考虑FLOPs。因此,提出了一种新的架构,称为ShuffleNet V2。
1 介绍
使用 FLOPs 作为计算复杂性的唯一指标是不够的。间接(FLOPs)和直接(速度)指标之间的差异可归因于两个主要原因。首先,FLOPs 没有考虑几个对速度有相当大影响的重要因素。其中一个因素是内存访问成本 (MAC)。
其次**,具有相同 FLOP 的操作可能具有不同的运行时间**,具体取决于平台。
我们建议应该考虑两个原则来进行有效的网络架构设计。首先,应该使用直接指标(例如,速度)而不是间接指标(例如,FLOPs)。其次,应在目标平台上评估此类指标。
然后,我们得出了四个有效网络设计指南,这些指南不仅仅是考虑FLOPs。
2 高效网络设计实用指南
如图 2 所示,整体运行时间被分解为不同的操作。我们注意到 FLOPs 指标只考虑了卷积部分。虽然这部分消耗了大部分时间,但其他操作包括数据I/O、数据 shuffle 和逐元素操作(AddTensor、ReLU 等)也占用了相当多的时间。因此,FLOPs 对实际运行时间的估计不够准确。基于这一观察,我们从几个不同方面对运行时间(或速度)进行了详细分析,并得出了几个有效网络架构设计的实用指南。

G1) 相等的通道宽度最小化内存访问成本 (MAC)。。
现代网络通常采用深度可分离卷积 [2, 8, 35, 24],其中逐点卷积(即 1 × 1 卷积)占了大部分的复杂性 [35]。
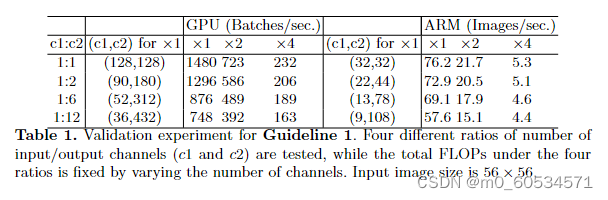
表 1. 指南 1 的验证实验。测试了输入/输出通道数的四种不同比率(c1 和 c2),而四种比率下的总 FLOPs通过改变通道数来固定。输入图像大小为 56 × 56。
G2) 过多的组卷积会增加 MAC。
组卷积是现代网络架构的核心 [33、35、12、34、31、26]。它通过将所有通道之间的密集卷积更改为稀疏(仅在通道组内)来降低计算复杂度(FLOP)。一方面,它允许在给定固定 FLOPs 的情况下使用更多通道并增加网络容量(从而提高准确性)。然而,另一方面,通道数量的增加导致更多的 MAC。

表 2. 指南 2 的验证实验。测试组号 g 的四个值,而四个值下的总 FLOPs 通过改变总通道数 c 来固定。输入图像大小为 56 ×56。
G3) 网络碎片化降低了并行度。
在 GoogLeNet 系列 [27、29、28、13] 和自动生成的架构 [39、21、18])中,每个网络块都广泛采用"多路径"结构。使用了许多小型运算符(这里称为"碎片化运算符")而不是一些大型运算符。例如,在 NASNET-A [39] 中,碎片运算符的数量(即一个构建块中单个卷积或池化操作的数量)为 13。

表 3. 指南 3 的验证实验。c 表示 1-片段的通道数。调整其他分片结构中的通道数,使 FLOPs 与 1-fragment 相同。输入图像大小为 56 × 56。
表 3 中的结果表明,碎片化会显着降低 GPU 上的速度,例如4 片段结构比 1 片段慢 3倍以上。在ARM 上,速度降低相对较小。
G4) 逐元素操作不可忽略。
这里,element-wise 逐元素操作算子包括ReLU、AddTensor、AddBias 等,它们的 FLOP 较小,但 MAC 相对较重。特别地,我们还将深度卷积 [2, 8,24, 35] 视为逐元素运算符,因为它也具有很高的 MAC/FLOPs 比率。

表 4. 指南 4 的验证实验。ReLU 和快捷操作分别从"瓶颈"单元 [5] 中移除。 c 是单元中的通道数。单元重复堆叠10次以对标速度。
表 4 报告了不同变体的运行时间。我们观察到在移除 ReLU 和快捷方式后,GPU 和 ARM 都获得了大约 20% 的加速。
基于上述指导方针和实证研究,我们得出结论,一个有效的网络架构应该
1)使用"平衡"卷积(等通道宽度);
2)注意使用组卷积的成本;
3)降低碎片化程度;
4)减少逐元素操作。
这些理想的属性取决于超出理论 FLOP 的平台特征(例如内存操作和代码优化)。它们应该被考虑到实际的网络设计中。
轻量级神经网络架构 [35,8, 24,39, 21, 18,2] 的最新进展主要基于FLOPs 的度量,没有考虑上述这些属性。例如,ShuffleNet v1 [35] 严重依赖于组卷积(违反 G2)和类似瓶颈的构建块(违反 G1)。MobileNetv2[24] 使用了违反 G1 的倒置瓶颈(反残差)结构。它在"厚"特征图上使用深度卷积和 ReLU。这违反了 G4。自动生成的结构 [39、21、18] 高度分散并且违反了G3。
3 ShuffleNet V2:一个高效的架构
回顾 ShuffleNet v1 [35]。 ShuffleNet 是最先进的网络架构。它被广泛应用于手机等低端设备。它启发了我们的工作。因此,首先对其进行分析。
根据ShuffleNet v1 [35],轻量级网络的主要挑战是在给定的计算预算(FLOPs)下只能提供有限数量的特征通道。为了在不显著增加 FLOPs的情况下增加通道数量, ShuffleNet v1 [35] 中采用了两种技术:逐点组卷积和瓶颈状结构。然后引入"通道融合"操作以实现不同频道组之间的信息通信并提高准确性。
构建块如图3(a)(b) 所示。如第 2 节所述,逐点组卷积和瓶颈结构都会增加 MAC(G1 和G2)。这个成本是不可忽略的,特别是对于轻量级模型。此外,使用过多的组违反了 G3。快捷连接中的元素级"添加"操作也是不可取的(G4)。因此为了获得高模型容量和效率,关键问题是如何在既不密集卷积也不过多组的情况下保持大量且等宽的通道。为达到上述目的,我们引入了一个简单的算子,称为 channel split。如图 3© 所示。
根据G3的规则,,一个分支仍然是同等连接,另一个分支由三个具有相同输入和输出通道的卷积组成,以满足 G1。与ShuffleNet v1[35] 不同,两个 1 x 1 卷积不再是分组的。这部分是为了遵循G2,除此之外还因为拆分操作已经产生了两个组。
卷积后,将两个分支连接起来。因此,通道数保持不变(G1)。然后使用与*ShuffleNet v1 [35] 中相同的"chane shufflel"操作来启用两个分支之间的信息通信。
chane shufflel后,下一单元开始。请注意,ShuffleNet v1 [35] 中的"Add"操作不再存在。像 ReLU 和深度卷积这样的逐元素操作只存在于一个分支中。此外,三个连续的逐元素操作"Concat"、"Channe Shuffle"和"Channel Split"合并为一个逐元素操作。根据 G4,这些变化是有益的。
对于空间下采样模块,略有修改,如图 3(d) 所示。删除了通道拆分运算符。因此,输出通道的数量增加了一倍。提议的构建块 ©(d) 以及由此产生的网络称为 ShuffleNet V2。该架构设计非常高效,因为它遵循所有准则。

ShuffleNet v2 不仅高效,而且准确。主要有两个原因。**首先,**每个构建块的高效率使得能够使用更多的特征通道和更大的网络容量。其次,在每个块中,一半的特征通道(当 c’ = c/2 时)直接穿过块并加入下一个块。这可以被视为一种特征重用,

结论
我们建议网络架构设计应该考虑速度等直接指标,而不是 FLOPs 等间接指标。我们提出了实用指南和一种新颖的架构,ShuffleNet v2。综合实验验证了我们新模型的有效性。我们希望这项工作能够激发未来的平台意识和更实用的网络架构设计工作。