一、简介
ShuffleNet 是旷世科技的Face++团队提出的,晚于MobileNet两个月在arXiv上公开。论文标题:
《ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices 》
论文链接:https://arxiv.org/abs/1707.01083
命名
一看名字ShuffleNet,就知道shuffle是本文的重点,那么shuffle是什么?为什么要进行shuffle?
shuffle具体来说是channel shuffle,是将各部分的feature map的channel进行有序的打乱,构成新的feature map,以解决group convolution带来的“信息流通不畅”问题。(MobileNet是用point-wise convolution解决的这个问题)
因此可知道shuffle不是什么网络都需要用的,是有一个前提,就是采用了group convolution,才有可能需要shuffle!! 为什么说是有可能呢?因为可以用point-wise convolution 来解决这个问题。
二、创新点 ---组卷积和通道重排
利用group convolution 和 channel shuffle 这两个操作来设计卷积神经网络模型, 以减少模型使用的参数数量。
group convolutiosn非原创,而channel shuffle是原创。 channel shuffle因group convolution 而起,正如论文中3.1标题: . Channel Shuffle for Group Convolution;
采用group convolution 会导致信息流通不当,因此提出channel shuffle,所以channel shuffle是有前提的,使用的话要注意!
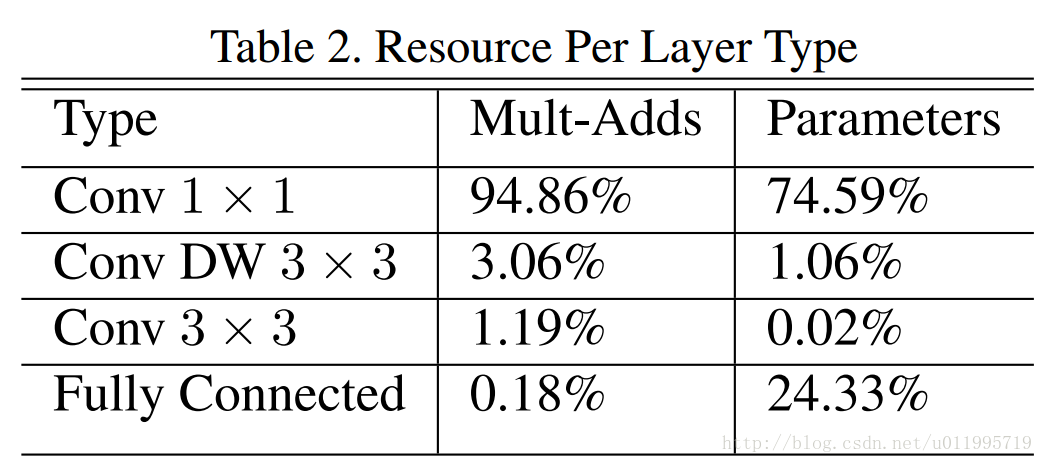
对比一下MobileNet,采用shuffle替换掉1*1卷积(注意!是1*1 Conv,也就是point-wise convolution;特别注意,point-wise convolution和 1*1 GConv是不同的),这样可以减少权值参数,而且是减少大量权值参数 ,因为在MobileNet中,1*1卷积层有较多的卷积核,并且计算量巨大,MobileNet每层的参数量和运算量如下图所示:
ShuffleNet的创新点在于利用了group convolution 和 channel shuffle,那么有必要看看group convolution 和channel shuffle
Group convolution
Group convolution 自Alexnet就有,当时因为硬件限制而采用分组卷积;之后在2016年的ResNeXt中,表明采用group convolution可获得高效的网络;再有Xception和MobileNet均采用depthwise convolution, 这些都是最近出来的一系列轻量化网络模型。depth-wise convolution具体操作可见2.2 MobileNet里边有简介
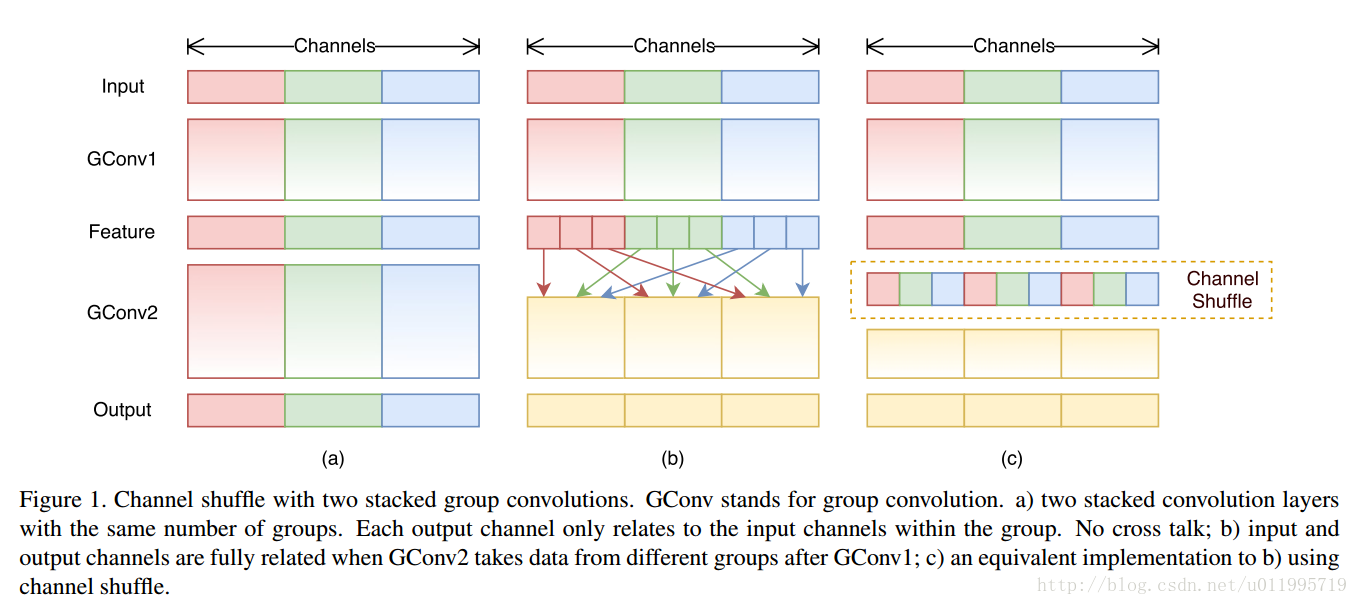
如下图(a)所示, 为了提升模型效率,采用group convolution,但会有一个副作用,即:“outputs from a certain channel are only derived from a small fraction of input channels.”
于是采用channel shuffle来改善各组间“信息流通不畅”问题,如下图(b)所示。
具体方法为:把各组的channel平均分为g(下图g=3)份,然后依次序的重新构成feature map
Channel shuffle 的操作非常简单,接下来看看ShuffleNet,ShuffleNet借鉴了Resnet的思想,从基本的resnet 的bottleneck unit 逐步演变得到 ShuffleNet 的bottleneck unit,然后堆叠的使用ShuffleNet bottleneck unit获得ShuffleNet;
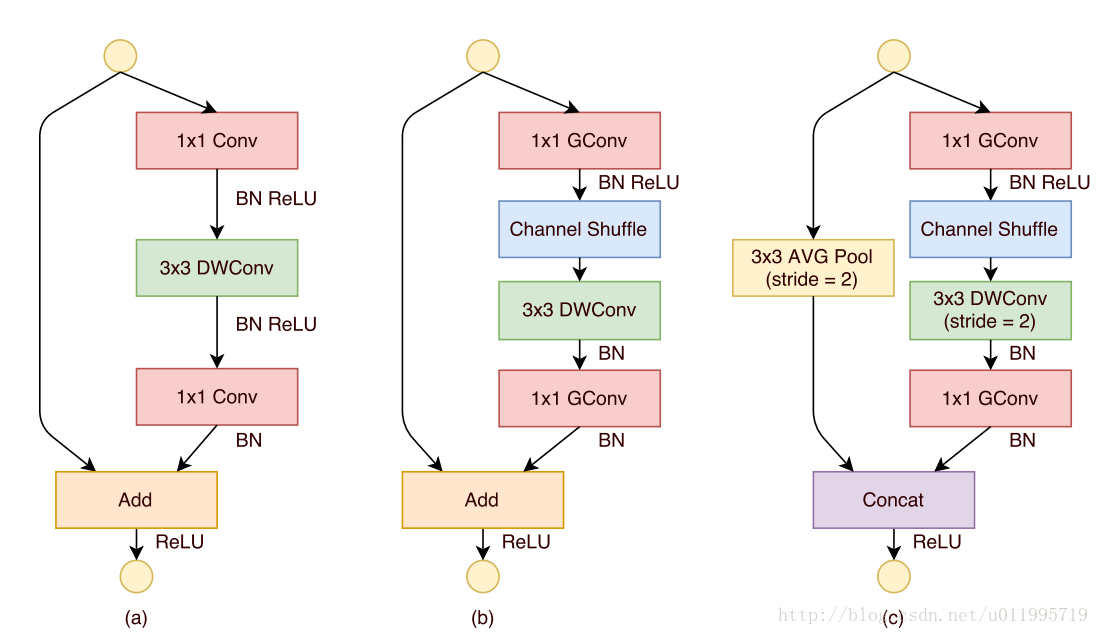
下图展示了ShuffleNet unit的演化过程
图(a):是一个带有depthwise convolution的bottleneck unit;
图(b):作者在(a)的基础上进行变化,对1*1 conv 换成 1*1 Gconv,并在第一个1*1 Gconv之后增加一个channel shuffle 操作;
图(c): 在旁路增加了AVG pool,目的是为了减小feature map的分辨率;因为分辨率小了,于是乎最后不采用Add,而是concat,从而“弥补”了分辨率减小而带来的信息损失。
文中提到两次,对于小型网络,多多使用通道,会比较好。
“this is critical for small networks, as tiny networks usually have an insufficient number of channels to process the information”
所以,以后若涉及小型网络,可考虑如何提升通道使用效率
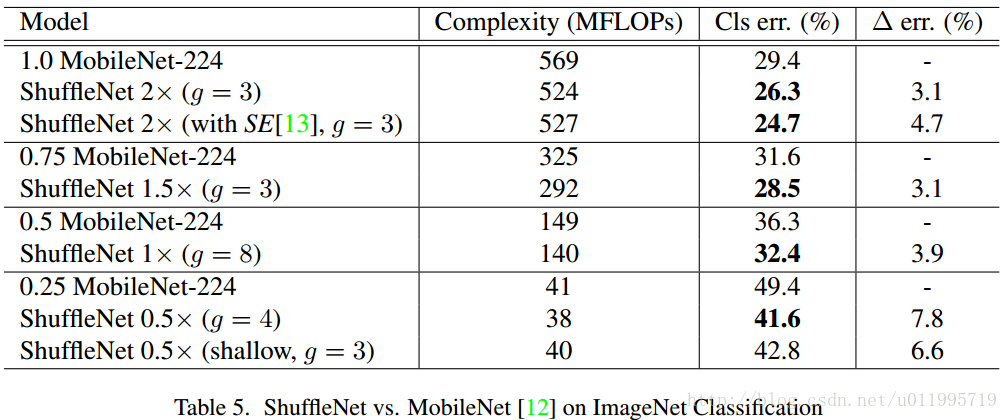
至于实验比较,并没有给出模型参数量的大小比较,而是采用了Complexity (MFLOPs)指标,在相同的Complexity (MFLOPs)下,比较ShuffleNet和各个网络,还专门和MobileNet进行对比,由于ShuffleNet相较于MobileNet少了1*1 Conv(注意!少了1*1 Conv,也就是point-wise convolution),所以效率大大提高了嘛,贴个对比图随意感受一下好了
三、ShuffleNet小结
1.与MobileNet一样采用了depth-wise convolution,但是针对 depth-wise convolution带来的副作用——“信息流通不畅”,ShuffleNet采用了一个channel shuffle 操作来解决。
2.网络拓扑方面,ShuffleNet采用的是resnet的思想,而mobielnet采用的是VGG的思想,SqueezeNet也是采用VGG的堆叠思想
参考:https://blog.csdn.net/u011995719/article/details/79100582