一、redis持久化
redis提供两种持久化策略 rdb 和 aof
rdb持久化策略:按照规则 定时将内存冲的数据同步到磁盘
1、快照
redis 在指定情况下会触发快照
1)、自己配置的规则
redis.conf中如下配置 save seconds changes
save 900 1 --当900秒内 更改的key数量大于1 时 执行快照备份
save 300 10 --当300秒内 更改的key数量大于10 时 执行快照备份
save 60 10000 --当60秒内 更改的key数量大于10000 时 执行快照备份
2 )、save 活着bgsave
命令 save 执行内存的数据同步到磁盘的操作,这个操作会阻塞客户端的请求
命令 bgsave 在后台异步执行快照操作,这个操作不会阻塞客户端请求
3)、执行flushall 的时候
清楚内存中所有数据,只要规则不为空(1中配置的规则不为空)redis会执行快照
4 )、执行复制的时候
复制数据到从节点的时候
快照的实现原理
redis 会使用fork函数复制一份当前进程的副本(子进程),fork进程负责把内存中的数据同步到磁盘的临时文件
父进程继续处理客户端请求
优点:
1)可以最大化redis的性能
缺点:
1)、会有数据丢失,两次快照触发规则之间的数据变动 可能会丢失
2、aof持久化策略:每次执行命令后,把命令本身记录下来
aof会把redis执行的每一条命令追加到磁盘文件中。
优点 记录了每次的操作日志,数据恢复比rdb方式更完整。
缺点 备份每次客户端的操作,对redis 的性能会有一定的影响 可以考虑使用ssd固态硬盘
aof持久化方式的开启方式 在redis.conf 中配置 :appendonly yes (默认可能为no)
appendfilename “appendonly.aof” (该项配置配置aof文件的名称 会写在bin目录下)
修改完配置,启动redis 并执行如下 命令
OK
127.0.0.1:6379> set key value
OK
127.0.0.1:6379> set key val1
OK
127.0.0.1:6379>
然后bin目录下 vi appendonly.aof 可以看到文件中 记录的命令日志
[root@192 bin]# vi appendonly.aof
*2
$6
SELECT
$1
0
*1
$8
flushall
*3
$3
set
$3
key
$5
value
*3
$3
set
$3
key
$4
val1
~
默认情况下aof文件中会记录 所有的命令
压缩策略配置 压缩会对同一个键的操作进行优化。
auto-aof-rewrite-percentage 100 表示当前aof文件超过上次aof文件大小百分之多少的时候会进行重写。如果之前没有重写过以启动时文件大小为准
auto-aof-rewrite-min-size 64mb 表示限制允许重写最小aof文件大小。文件大小小于这个值时不用进行优化
aof 重写的原理过程:
redis在后台自动对aof文件重写。这个过程是安全的。客户端依然可以发起请求。
执行aof重写时现有的aof文件会继续追加命令日志,新建一个aof临时文件去做重写。
redis 每次更改数据的时候,aof机制会将命令记录的aof文件。但是由于计算机硬件也并不是直接将文件写入到磁盘,而是通过缓存写入,所以如果数据还在缓存时宕机也会存在数据丢失问题。
缓存数据同步到磁盘的时机也可以在redis.conf 中配置如下:
# appendfsync always 每次有redis命令都同步,性能最低,安全性最高
appendfsync everysec 每秒同步一次
# appendfsync no 不主动执行同步操作 由操作系统执行。这个是最快但是最不安全的
aof文件损坏如何修复:
通过 redis-check-aof -fix 命令进行修复。
两种持久化策略可以同时使用也可以使用一种。如果同时使用redis有限使用aof文件来回复数据。
二、集群:
1、复制(master-slave)
配置过程 修改 slave机器的 redis.conf 增加如下配置
slaveof
我这里两台slave 都配置
slaveof 192.168.159.10 6379
重启三台reidis 服务后 启动
执行 ./redis-cli 链接 本机redis 服务 然后执行info replication 可以看到主从状态信息如下
master:
[root@192 bin]# ./redis-cli
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.159.12,port=6379,state=online,offset=99,lag=1
slave1:ip=192.168.159.11,port=6379,state=online,offset=99,lag=1
master_repl_offset:99
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:98
slave :
[root@192 bin]# ./redis-cli
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.159.10
master_port:6379
master_link_status:up
master_last_io_seconds_ago:10
master_sync_in_progress:0
slave_repl_offset:99
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
然后在主节点自行 set name zhang 从节点执行 get name 也是zhang
并且从节点默认不能进行写操作。执行 set name zhang 报错如下(redis.conf 中有默认配置 slave-read-only yes):
127.0.0.1:6379> set name zhang
(error) READONLY You can't write against a read only slave.
127.0.0.1:6379> get name
实现原理 :
1)slave第一次或重新连接到master 后 会向master发送一个sunc 命令
2)master收到sync 的时候做两件事
a)执行bgsave rdb快照保存数据到磁盘 并把文件传送给salve,slave收到文件会把文件中的数据加载到内存
b)把新收到的修改命令保存到缓冲区,并将命令发送给slave 实现同步
验证同步操作。
在slave几点执行sync 可以看到 命令同步过程如下:
主几点执行 set name li 后 slave 收到了 set name li
127.0.0.1:6379> sync
Entering slave output mode... (press Ctrl-C to quit)
SYNC with master, discarding 42 bytes of bulk transfer...
SYNC done. Logging commands from master.
"PING"
"PING"
"PING"
"PING"
"PING"
"SELECT","0"
"set","name","li"
主从数据不一致问题解决:
redis.conf 中 slave-serve-stale-data 选项可以配置,在从节点完成同步之前是否正常接收客户端请求 为yes 表示正常接收 no 如果没有同步完数据 有客户端请求时返回错误(具体参见redis.conf 中的说明)
复制方式:
基于rdb文件的复制
无硬盘复制
增量复制
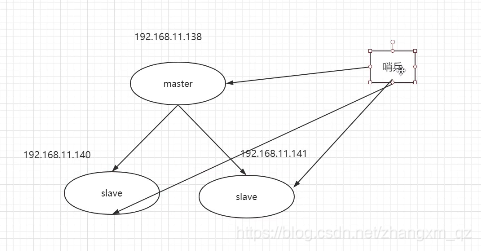
2、哨兵机制 sentinel
哨兵可以检测master 和slave 的状态
当master挂掉以后选举出新的master (哨兵也可以做集群,增加可用性)
哨兵监控redis状态的同时也会监控其他哨兵的状态。
配置哨兵:
1)复制sentinel.conf 配置文件到bin目录
2)修改配置
sentinel monitor mymaster 192.168.159.10 6379 2 配置要监控的master节点 ip 端口 第三个参数2 表示有几个哨兵投票才起作用 我们三个哨兵配置为2
sentinel down-after-milliseconds mymaster 10000 配置在多少毫秒之内 主节点没有响应就判断为离线
然后开始从 slave中选举出新的master
3)启动哨兵
运行 ./redis-sentinel ./sentinel.conf
[root@192 bin]# ./redis-sentinel ./sentinel.conf
8577:X 05 Feb 22:56:04.349 * Increased maximum number of open files to 10032 (it was originally set to 1024).
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 3.0.7 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in sentinel mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 26379
| `-._ `._ / _.-' | PID: 8577
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
8577:X 05 Feb 22:56:04.351 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
8577:X 05 Feb 22:56:04.351 # Sentinel runid is e01630b36aa383688bf8609a9622045d2620d017
8577:X 05 Feb 22:56:04.351 # +monitor master mymaster 192.168.159.10 6379 quorum 2
8577:X 05 Feb 22:56:04.404 * +slave slave 192.168.159.12:6379 192.168.159.12 6379 @ mymaster 192.168.159.10 6379
8577:X 05 Feb 22:56:04.461 * +slave slave 192.168.159.11:6379 192.168.159.11 6379 @ mymaster 192.168.159.10 6379
4)哨兵集群
直接在多台服务器启动哨兵即可 这里 三台服务器都按照上述步骤修改配置并启动哨兵。
多台哨兵启动时可以看到哨兵同事监控了哨兵的状态 如下:
[root@192 bin]# ./redis-sentinel ./sentinel.conf
7971:X 05 Feb 23:02:31.869 * Increased maximum number of open files to 10032 (it was originally set to 1024).
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 3.0.7 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in sentinel mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 26379
| `-._ `._ / _.-' | PID: 7971
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
7971:X 05 Feb 23:02:31.872 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
7971:X 05 Feb 23:02:31.873 # Sentinel runid is e83812b0bad75bb5e50886b76363668a4fc0d1b7
7971:X 05 Feb 23:02:31.873 # +monitor master mymaster 192.168.159.10 6379 quorum 2
7971:X 05 Feb 23:02:33.608 * +sentinel sentinel 192.168.159.11:26379 192.168.159.11 26379 @ mymaster 192.168.159.10 6379
7971:X 05 Feb 23:02:33.811 * +sentinel sentinel 192.168.159.12:26379 192.168.159.12 26379 @ mymaster 192.168.159.10 6379
哨兵选举演示。
通过客户端关闭master redis 可以看到哨兵重新选举了新的 master 节点 为 192.168.159.12 如下:
8507:X 05 Feb 23:09:39.961 # +sdown master mymaster 192.168.159.10 6379
8507:X 05 Feb 23:09:40.028 # +odown master mymaster 192.168.159.10 6379 #quorum 2/2
8507:X 05 Feb 23:09:40.028 # +new-epoch 1
8507:X 05 Feb 23:09:40.028 # +try-failover master mymaster 192.168.159.10 6379
8507:X 05 Feb 23:09:40.098 # +vote-for-leader 0ffa476301677a36b9e83e4a3305df9837cb06ee 1
8507:X 05 Feb 23:09:40.109 # 192.168.159.10:26379 voted for e83812b0bad75bb5e50886b76363668a4fc0d1b7 1
8507:X 05 Feb 23:09:40.124 # 192.168.159.11:26379 voted for 0ffa476301677a36b9e83e4a3305df9837cb06ee 1
8507:X 05 Feb 23:09:40.165 # +elected-leader master mymaster 192.168.159.10 6379
8507:X 05 Feb 23:09:40.165 # +failover-state-select-slave master mymaster 192.168.159.10 6379
8507:X 05 Feb 23:09:40.272 # +selected-slave slave 192.168.159.12:6379 192.168.159.12 6379 @ mymaster 192.168.159.10 6379
8507:X 05 Feb 23:09:40.273 * +failover-state-send-slaveof-noone slave 192.168.159.12:6379 192.168.159.12 6379 @ mymaster 192.168.159.10 6379
8507:X 05 Feb 23:09:40.361 * +failover-state-wait-promotion slave 192.168.159.12:6379 192.168.159.12 6379 @ mymaster 192.168.159.10 6379
8507:X 05 Feb 23:09:41.121 # +promoted-slave slave 192.168.159.12:6379 192.168.159.12 6379 @ mymaster 192.168.159.10 6379
8507:X 05 Feb 23:09:41.121 # +failover-state-reconf-slaves master mymaster 192.168.159.10 6379
8507:X 05 Feb 23:09:41.201 * +slave-reconf-sent slave 192.168.159.11:6379 192.168.159.11 6379 @ mymaster 192.168.159.10 6379
8507:X 05 Feb 23:09:42.157 * +slave-reconf-inprog slave 192.168.159.11:6379 192.168.159.11 6379 @ mymaster 192.168.159.10 6379
8507:X 05 Feb 23:09:42.343 # -odown master mymaster 192.168.159.10 6379
8507:X 05 Feb 23:09:43.205 * +slave-reconf-done slave 192.168.159.11:6379 192.168.159.11 6379 @ mymaster 192.168.159.10 6379
8507:X 05 Feb 23:09:43.310 # +failover-end master mymaster 192.168.159.10 6379
8507:X 05 Feb 23:09:43.310 # +switch-master mymaster 192.168.159.10 6379 192.168.159.12 6379
8507:X 05 Feb 23:09:43.316 * +slave slave 192.168.159.11:6379 192.168.159.11 6379 @ mymaster 192.168.159.12 6379
8507:X 05 Feb 23:09:43.317 * +slave slave 192.168.159.10:6379 192.168.159.10 6379 @ mymaster 192.168.159.12 6379
8507:X 05 Feb 23:09:53.336 # +sdown slave 192.168.159.10:6379 192.168.159.10 6379 @ mymaster 192.168.159.12 6379
在 192.168.159.12 redis中 执行命令 set name zhang 其他节点 执行 get name 可以获取到 zhang 如下:
127.0.0.1:6379> get name
"zhang"
127.0.0.1:6379>
再次启动 192.168.159.10(原来的master节点)发现节点状态变为了 slave 如下
8507:X 05 Feb 23:18:11.923 # -sdown slave 192.168.159.10:6379 192.168.159.10 6379 @ mymaster 192.168.159.12 6379
[root@192 bin]# ./redis-cli
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.159.12
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:136084
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379>
哨兵+复制 才能组成redis 高可用
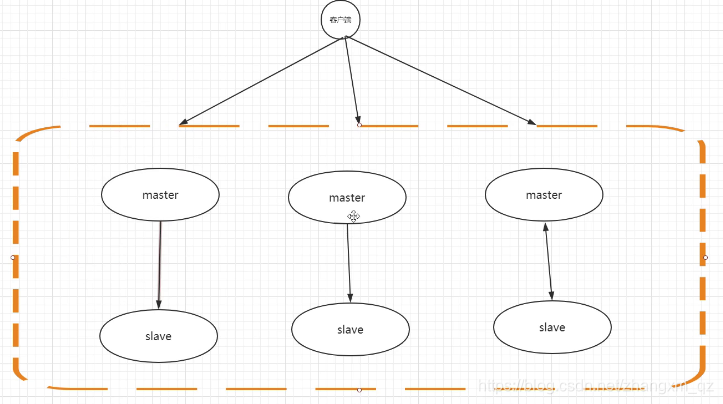
3、集群(3.0以后的功能)
之前redis 中所有的数据都保存在一个节点中,数据量大时会有性能问题。redis集群会把数据分片保存到多个节点,多个master共同保存一份数据,每个master又都有自己的slave 和哨兵,如下图
3.0之前实现方式:客户端 根据key 的hash值对服务节点数量取模,进行数据分片
3.0之后 redis提供了分片的机制 客户端不用做处理
slot(槽) 的概念 在redis集群中一共会有16384个槽
根据key 的 crc16算法 ,得到的结果再对16384进行取模。假如有有三个节点 16384/3=5460
node 1 保存槽位 0-5460
node2 保存槽位5461-10922
node3 保存槽位10923-15383
如果增加了节点 就会出现数据迁移 1-3个节点上都有一部分数据要迁移到新节点中。
需要人工迁移, 有一个脚本 redis-trib.rb
目前使用这种方案的比较少,因为3.0刚提供,3.0之前市面上提供了集群方案如下。
1)redis shardding jedis客户端支持shardding操作。 根据一致性hash取模 实现
2)codis (豌豆荚提供的分片策略 目前 应用比较广泛)基于redis2.8代码分支开发了一个codis-server。集成了分片操作。
3)twemproxy
不管用哪种方案,增删节点时都会涉及到 数据的迁移。目前应用广泛的解决方式就是 pre-shardding (预分片)
假如我只需要三台redis服务,那么我部署9台。每台服务器上部署三台(共九个redis节点),这样不用增加硬件,前期redis数据量不大时还可以提高cpu利用率。日后如果数据量变大,只需要将每台机器上的三台redis服务迁移到新的服务器上就可以了。不用进行任何数据分片处理