理论
前面我们说过,Redis相对于Memcache等其他的缓存产品,有一个比较明显的优势就是Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。这几种丰富的数据类型我们接下来要介绍Redis的另外一大优势—持久化。
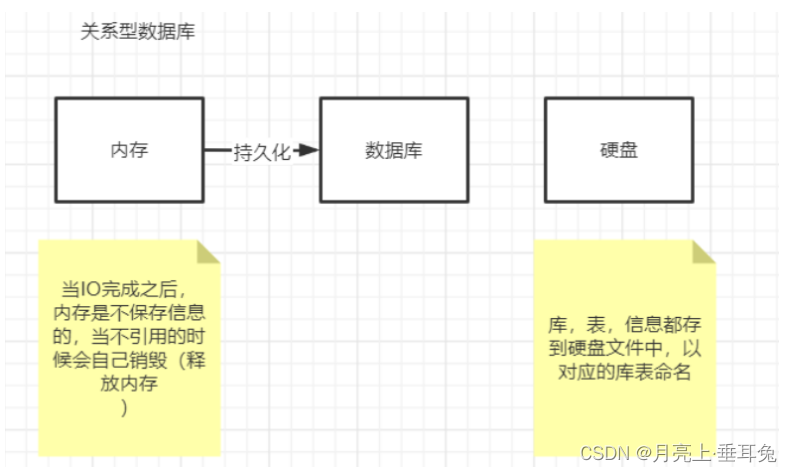
由于Rediis是一个内存数据库,所谓内存数据库,就是将数据库中的内容存到内存中,这与传统的Mysql,Oracle等关系型数据库直接将内容保存到硬盘中相比,内存数据库的读写效率比传统的数据库快得多(内存的读写效率远远大于硬盘的读写效率)。
但是保存在内存中也随之带来一个缺点,一旦断电或者宕机,那么内存数据库中的数据将会全部丢失。
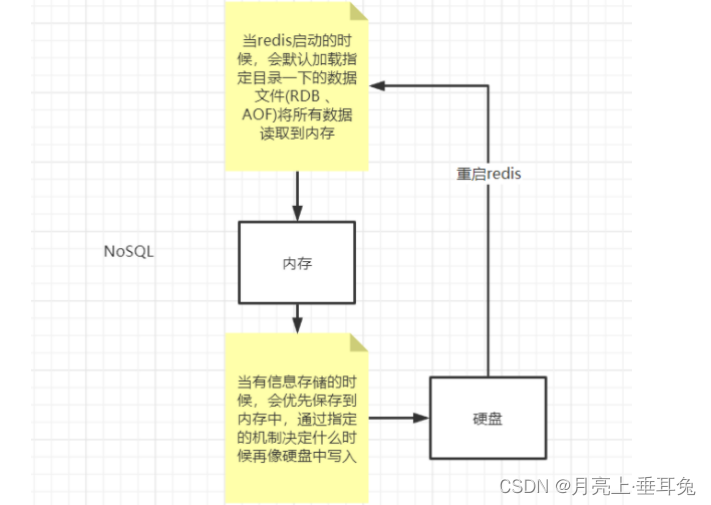
为了解决这个缺点,Redis提供了内存将数据持久化到硬盘,以及用持久化文件来恢复数据库的功能。Redis支持两种形式的持久化,一种是RDB快照,另一种是AOF数据库存储方式。
NoSQL存储方式
RDB快照(redis DateBase)
概述
EDB是Redis用来进行持久化的一种方式,是把当前内存中的数据集快照写入磁盘,也就是Snapshot快照(数据库中所有键值对数据)。恢复时是快照文件直接读到内存里。
触发方式
查看redis配置文件
################################ 快照 #################################
#
# 保存数据到磁盘,格式如下:
#
# save <seconds> <changes>
#
# 指出在多长时间内,有多少次更新操作,就将数据同步到数据文件rdb。
# 相当于条件触发抓取快照,这个可以多个条件配合
#
# 比如默认配置文件中的设置,就设置了三个条件
#
# save 900 1 900秒内至少有1个key被改变
# save 300 10 300秒内至少有10个key被改变
# save 60 10000 60秒内至少有10000个key被改变
save 900 1
save 300 10
save 60 10000
# 存储至本地数据库时(持久化到rdb文件)是否压缩数据,默认为yes
rdbcompression yes
# 本地持久化数据库文件名,默认值为dump.rdb
dbfilename dump.rdb
# 工作目录
#
# 数据库镜像备份的文件放置的路径。
# 这里的路径跟文件名要分开配置是因为redis在进行备份时,先会将当前数据库的状态写入到一个临时文件中,
等备份完成时,
# 再把该该临时文件替换为上面所指定的文件,而这里的临时文件和上面所配置的备份文件都会放在这个指定的路
径当中。
#
# AOF文件也会存放在这个目录下面
#
# 注意这里必须制定一个目录而不是文件
dir ./
save: 这里是用来配置触发 Redis的 RDB 持久化条件,也就是什么时候将内存中的数据保存到硬盘。比如
“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave(这个命令下面会介绍,手动触发RDB持
久化的命令)。
rdbcompression :默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,
redis会采用LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能,但是存储在
磁盘上的快照会比较大。
stop-writes-on-bgsave-error :默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停
止接收数据。这会让用户意识到数据没有正确持久化到磁盘上,否则没有人会注意到灾难(disaster)发生
了。如果Redis重启了,那么又可以重新开始接收数据了。
rdbchecksum :默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是
这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
dbfilename :设置快照的文件名,默认是 dump.rdb
dir:设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名。默认是和当前配置文件保存在
同一目录。
测试自动触发
1 添加数据测试, 查找数据库文件
2 改变文件名称
3 查看快照路径
手动触发
手动触发Redis进行RDB持久化的命令有两种:
save:该命令会阻塞当前Redis服务器,执行save命令期间,redis不能处理其他命令,直到RDB过程完成为
止。显然该命令对于内存比较大的实例会造成长时间阻塞,这是致命的缺陷,为了解决此问题,redis提供了
第二种方式。(不建议使用)
bgsave:执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。具体操作是
Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在创建子
进程fork阶段,一般时间很短。
基本上 Redis 内部所有的RDB操作都是采用 bgsave 命令。
还有两种特殊的操作也能触发RDB的持久化,但是因为情况特殊,所以不作为手动触发条件
执行执行 flushall.flushdb 命令,也会产生dump.rdb文件,但里面是空的,无意义
关闭redis 服务同样会生成 — 规则使用 bgsave 保存数据
RDB数据恢复(企业管理者经常用的手段)
将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可,redis就会自动加载文件数据至内存了。
Redis 服务器在载入 RDB 文件期间,会一直处于阻塞状态,直到载入工作完成为止。
启动服务器的当前目录一定是redis-*** 否则快照生成的路径就会发生错误!
127.0.0.1:6379> config get dir
dir
/opt/redis-7.0.4
测试文件恢复
停止 RDB 持久化
有些情况下,我们只想利用Redis的缓存功能,并不像使用 Redis 的持久化功能,那么这时候我们最好停掉
RDB 持久化。可以通过上面讲的在配置文件 redis.conf 中,可以注释掉所有的 save 行来停用保存功能或者
直接一个空字符串来实现停用:save “”
# save 60 10000
save ""
也可以执行命令
redis-cli config set save ""
RDB 的优势和劣势(高危面试题)
优势
- RDB是一个非常紧凑的文件(默认压缩),它保存redis 在某个时间点上的数据集。这种文件非常适合用于
备份和灾难恢复。 - 生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁
盘IO操作。 - RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
劣势 - RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运行都要执行fork操作创建子进
程,属于重量级操作(内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑),频繁执行成本过高(影
响性能) - RDB文件使用特定二进制格式保存,Redis版本演进过程中有多个格式的RDB版本,存在老版本Redis服
务无法兼容新版RDB格式的问题(版本不兼容) - 在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改(数
据有丢失)
RDB 自动保存的原理(高低薪差异题)
redis有个服务器状态结构:
struct redisService{
//1、记录保存save条件的数组
struct saveparam *saveparams;
//2、修改计数器
long long dirty;
//3、上一次执行保存的时间
time_t lastsave;
}
首先看记录保存save条件的数组 saveparam,里面每个元素都是一个 saveparams 结构:
struct saveparam{
//秒数
time_t seconds;
//修改数
int changes;
};
前面我们在 redis.conf 配置文件中进行了关于save 的配置:
save 3600 1 :表示3600 秒内如果至少有 1 个 key 的值变化,则保存
save 300 100:表示300 秒内如果至少有 10 个 key 的值变化,则保存
save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存
那么服务器状态中的saveparam 数组将会是如下的样子:

dirty 计数器和lastsave 属性
dirty 计数器记录距离上一次成功执行 save 命令或者 bgsave 命令之后,Redis服务器进行了多少次修改(包
括写入、删除、更新等操作)。
lastsave 属性是一个时间戳,记录上一次成功执行 save 命令或者 bgsave 命令的时间。
执行原理:通过这两个属性,当服务器成功执行一次修改操作,那么dirty 计数器就会加 1,而lastsave 属性记录上一次
执行save或bgsave的时间,Redis 服务器还有一个周期性操作函数 severCron ,默认每隔 100 毫秒就会执行
一次,该函数会遍历并检查 saveparams 数组中的所有保存条件,只要有一个条件被满足,那么就会执行
bgsave 命令。
执行完成之后,dirty 计数器更新为 0 ,lastsave 也更新为执行命令的完成时间。
AOF
概述
Redis的持久化方式之一RDB是通过保存数据库中的键值对来记录数据库的状态。而另一种持久化方式 AOF
则是通过保存Redis服务器所执行的写命令来记录数据库状态。
AOF以协议文本的方式,将所有对数据库进行写入的命令(及其参数)记录到 AOF 文件,以此达到记录数据
库状态的目的。
用日志的形式来记录每个操作,将redis执行过的所有的指令都记录下来(读操作不记录),只许追加文件但不
可以写文件,换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次,已完成数据文件的
恢复工作
比如对于如下命令:
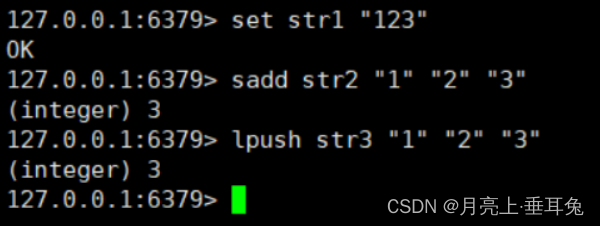
RDB 持久化方式就是将 str1,str2,str3 这三个键值对保存到 RDB文件中,而 AOF 持久化则是将执行的
set,sadd,lpush 三个命令保存到 AOF 文件中。
AOF配置
############################## AOF ###############################
# 默认情况下,redis会在后台异步的把数据库镜像备份到磁盘,但是该备份是非常耗时的,而且备份也不能很频
繁,
#如果发生诸如拉闸限电、拔插头等状况,那么将造成比较大范围的数据丢失。
# 所以redis提供了另外一种更加高效的数据库备份及灾难恢复方式。
# 开启append only模式之后,redis会把所接收到的每一次写操作请求都追加到appendonly.aof文件中,
#当redis重新启动时,会从该文件恢复出之前的状态。
# 但是这样会造成appendonly.aof文件过大,所以redis还支持了BGREWRITEAOF指令,对appendonly.aof
进行重新整理。
# 你可以同时开启asynchronous dumps 和 AOF
appendonly no
# AOF文件名称 (默认: "appendonly.aof")
# appendfilename appendonly.aof
# Redis支持三种同步AOF文件的策略:
#
# no: 不进行同步,系统去操作 . Faster.
# always: always表示每次有写操作都进行同步. Slow, Safest.
# everysec: 表示对写操作进行累积,每秒同步一次. Compromise.
#
# 默认是"everysec",按照速度和安全折中这是最好的。
# 如果想让Redis能更高效的运行,你也可以设置为"no",让操作系统决定什么时候去执行
# 或者相反想让数据更安全你也可以设置为"always"
#
# 如果不确定就用 "everysec".
# appendfsync always
appendfsync everysec
# appendfsync no
# AOF策略设置为always或者everysec时,后台处理进程(后台保存或者AOF日志重写)会执行大量的I/O操作
# 在某些Linux配置中会阻止过长的fsync()请求。注意现在没有任何修复,即使fsync在另外一个线程进行处理
#
# 为了减缓这个问题,可以设置下面这个参数no-appendfsync-on-rewrite
#
# This means that while another child is saving the durability of Redis is
# the same as "appendfsync none", that in pratical terms means that it is
# possible to lost up to 30 seconds of log in the worst scenario (with the
# default Linux settings).
#
# If you have latency problems turn this to "yes". Otherwise leave it as
# "no" that is the safest pick from the point of view of durability.
no-appendfsync-on-rewrite no
# Automatic rewrite of the append only file.
# AOF 自动重写
# 当AOF文件增长到一定大小的时候Redis能够调用 BGREWRITEAOF 对日志文件进行重写
#
# 它是这样工作的:Redis会记住上次进行些日志后文件的大小(如果从开机以来还没进行过重写,那日子大小在开
机的时候确定)
#
# 基础大小会同现在的大小进行比较。如果现在的大小比基础大小大制定的百分比,重写功能将启动
# 同时需要指定一个最小大小用于AOF重写,这个用于阻止即使文件很小但是增长幅度很大也去重写AOF文件的情况
# 设置 percentage 为0就关闭这个特性
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
appendonly:默认值为no,也就是说redis 默认使用的是rdb方式持久化,如果想要开启 AOF 持久化方
式,需要将appendonly 修改为 yes。
appendfilename :aof文件名,默认是"appendonly.aof"
appendfsync**:**aof持久化策略的配置;
- no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快,但是不太安全;
- always表示每次写入都执行fsync,以保证数据同步到磁盘,效率很低;
-
- everysec表示每秒执行一次fsync,可能会导致丢失这1s数据。通常选择 everysec ,兼顾安全性和效
率。(默认)
no-appendfsync-on-rewrite:在aof重写或者写入aof文件的时候,会执行大量IO,此时对于everysec和
always的aof模式来说,执行fsync会造成阻塞过长时间,no-appendfsync-on-rewrite字段设置为默认设置
为no。如果对延迟要求很高的应用,这个字段可以设置为yes,否则还是设置为no,这样对持久化特性来说
这是更安全的选择。 设置为yes表示rewrite期间对新写操作不fsync,暂时存在内存中,等rewrite完成后再写
入,默认为no,建议yes。Linux的默认fsync策略是30秒。可能丢失30秒数据。默认值为no。
auto-aof-rewrite-percentage:默认值为100。aof自动重写配置,当目前aof文件大小超过上一次重写的
aof文件大小的百分之多少进行重写,即当aof文件增长到一定大小的时候,Redis能够调用bgrewriteaof对日
志文件进行重写。当前AOF文件大小是上次日志重写得到AOF文件大小的二倍(设置为100)时,自动启动
新的日志重写过程。 64M - 40M - 80M(55M) - 110M(70M)
auto-aof-rewrite-min-size:64mb。设置允许重写的最小aof文件大小,避免了达到约定百分比但尺寸仍
然很小的情况还要重写。
aof-load-truncated:aof文件可能在尾部是不完整的,当redis启动的时候,aof文件的数据被载入内存。
重启可能发生在redis所在的主机操作系统宕机后,出现这种现象 redis宕机或者异常终止不会造成尾部不完
整现象,可以选择让redis退出,或者导入尽可能多的数据。如果选择的是yes,当截断的aof文件被导入的时
候,会自动发布一个log给客户端然后load。如果是no,用户必须手动redis-check-aof修复AOF文件才可
以。默认值为 yes。
- everysec表示每秒执行一次fsync,可能会导致丢失这1s数据。通常选择 everysec ,兼顾安全性和效
开启AOF
默认不开启,需要手动开启 - AOF和RDB同时开启 ,默认走AOF策略
appendonly yes

注意配置完成后重启redis,并set几个值,# vim查看aof文件
#7.04 版本 aof文件存储已经更改到appendonlydir文件夹下,对应去查找 appendonly.aof.1.incr.aof
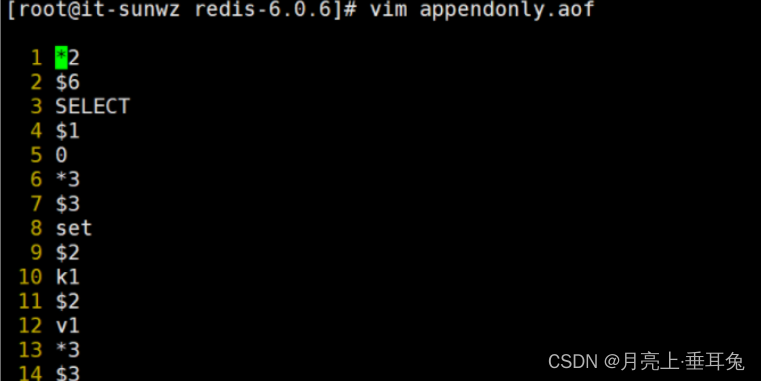
所以这里就是以日志的形式默认记录所有的写操作,如果这个文件遭到破坏,可以通过以下这个命令进行恢
复
AOF文件故障修复
# 关闭redis
# 删除dump.rdb
# 随便修改点aof文件
# 重新启动redis

通过redis-check-aof --fix 工具 修复文件

修复后重新启动。
AOF文件重写机制
AOF 文件包含三类文件:基本文件、增量文件与清单文件。其中基本文件一般为 rdb 格式,就是 rdb 持久化
的数据文件。
由于AOF持久化是Redis不断将写命令记录到 AOF 文件中,随着Redis不断的进行,AOF 的文件会越来越
大,文件越大,占用服务器内存越大以及 AOF 恢复要求时间越长。为了解决这个问题,Redis新增了重写机
制,当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最
小指令集。可以使用命令 bgrewriteaof 来重写。
比如对于如下命令:
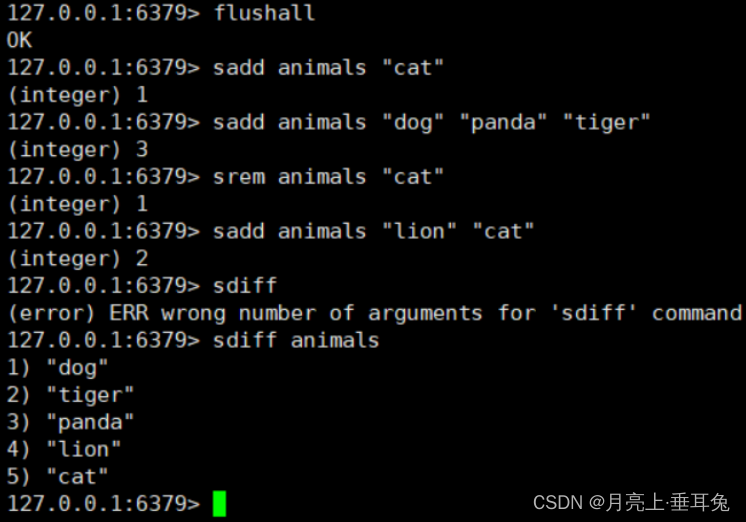
如果不进行 AOF 文件重写,那么 AOF 文件将保存四条 SADD 命令,如果使用AOF 重写,那么AOF 文件中将
只会保留下面一条命令:
sadd animals “dog” “tiger” “panda” “lion” “cat”
也就是说 AOF 文件重写并不是对原文件进行重新整理,而是直接读取服务器现有的键值对,然后用一条命令
去代替之前记录这个键值对的多条命令,生成一个新的文件后去替换原来的 AOF 文件。
AOF 重写触发机制:
通过 redis.conf 配置文件中的 auto-aof-rewrite-percentage:默认值为100,以及auto-aof-rewrite-minsize:64mb 配置,也就是说默认Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次
rewrite后大小的一倍且文件大于64M时触发。
这里再提一下,我们知道 Redis 是单线程工作,如果重写 AOF 需要比较长的时间,那么在重写 AOF 期间,
Redis将长时间无法处理其他的命令,这显然是不能忍受的。Redis为了克服这个问题,解决办法是将 AOF 重
写程序放到子程序中进行,这样有两个好处:
- 子进程进行 AOF 重写期间,服务器进程(父进程)可以继续处理其他命令。
- 子进程带有父进程的数据副本,使用子进程而不是线程,可以在避免使用锁的情况下,保证数据的安全
性。
使用子进程解决了上面的问题,但是新问题也产生了:因为子进程在进行 AOF 重写期间,服务器进程依然在
处理其它命令,这新的命令有可能也对数据库进行了修改操作,使得当前数据库状态和重写后的 AOF 文件状
态不一致。
为了解决这个数据状态不一致的问题,Redis 服务器设置了一个 AOF 重写缓冲区,这个缓冲区是在创建子进
程后开始使用,当Redis服务器执行一个写命令之后,就会将这个写命令也发送到 AOF 重写缓冲区。当子进
程完成 AOF 重写之后,就会给父进程发送一个信号,父进程接收此信号后,就会调用函数将 AOF 重写缓冲
区的内容都写到新的 AOF 文件中。
这样将 AOF 重写对服务器造成的影响降到了最低。
AOF的优缺点
优点:
- AOF 持久化的方法提供了多种的同步频率,即使使用默认的同步频率每秒同步一次,最多也就丢失1秒
的数据而已。 - AOF 文件使用 Redis 命令追加的形式来构造,因此,即使 Redis 只能向 AOF 文件写入命令的片断,使
用 redis-check-aof 工具也很容易修正 AOF 文件。 - AOF 文件的格式可读性较强,这也为使用者提供了更灵活的处理方式。例如,如果我们不小心错用了
FLUSHALL 命令,在重写还没进行时,我们可以手工将最后的 FLUSHALL 命令去掉,然后再使用 AOF
来恢复数据。
缺点: - 对于具有相同数据的的 Redis,AOF 文件通常会比 RDB 文件体积更大。
- 虽然 AOF 提供了多种同步的频率,默认情况下,每秒同步一次的频率也具有较高的性能。但在 Redis
的负载较高时,RDB 比 AOF 具好更好的性能保证。 - RDB 使用快照的形式来持久化整个 Redis 数据,而 AOF 只是将每次执行的命令追加到 AOF 文件中,因
此从理论上说,RDB 比 AOF 方式更健壮。官方文档也指出,AOF 的确也存在一些 BUG,这些 BUG 在
RDB 没有存在
redis发布订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
Redis 的 subscribe 命令可以让客户端订阅任意数量的频道, 每当有新信息发送到被订阅的频道时, 信息就
会被发送给所有订阅指定频道的客户端。
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关
系: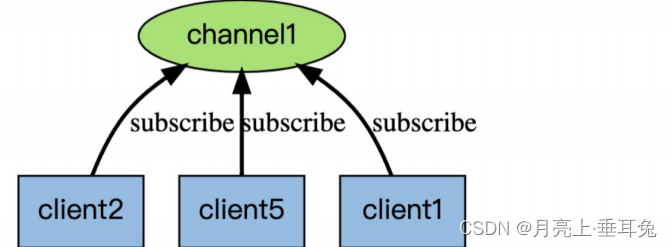
当有新消息通过 publish 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端: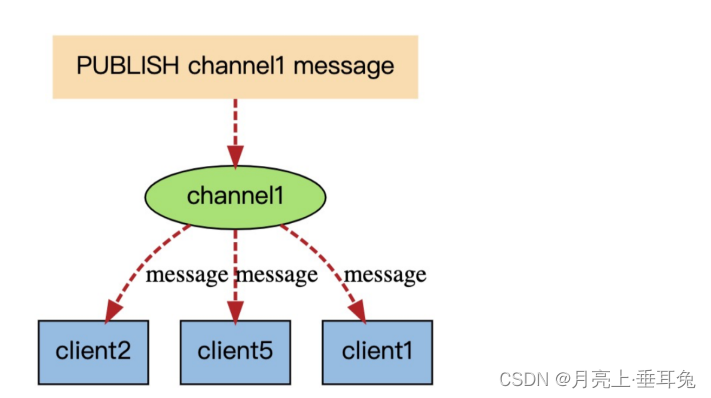
为什么要用发布订阅?
熟悉消息中间件的同学都知道,针对消息订阅发布功能,市面上很多大厂使用的是kafka、RabbitMQ、
ActiveMQ, RocketMQ等这几种,redis的订阅发布功能跟这三者相比,相对轻量,针对数据准确和安全性要
求没有那么高可以直接使用,适用于小公司。
Redis有两种发布/订阅模式:
基于频道(Channel)的发布/订阅
基于模式(pattern)的发布/订阅(可以自学)
基于频道(Channel)的发布/订阅 操作命令如下

“发布/订阅” 包含2种角色:发布者和订阅者。发布者可以向指定的频道(channel)发送消息;订阅者可以订阅
一个或者多个频道(channel),所有订阅此频道的订阅者都会收到此消息。
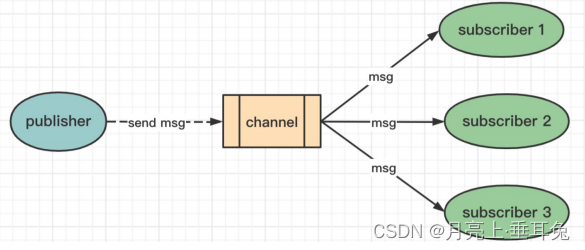
--------------------------客户端1(订阅者) :订阅频道 ---------------------
# 订阅 “mrtt” 和 “csdn” 频道(如果不存在则会创建频道)
127.0.0.1:6379> subscribe mrtt csdn
Reading messages... (press Ctrl-C to quit)
1) "subscribe" -- 返回值类型:表示订阅成功!
2) "mrtt" -- 订阅频道的名称
3) (integer) 1 -- 当前客户端已订阅频道的数量
1) "subscribe"
2) "csdn"
3) (integer) 2
#注意:订阅后,该客户端会一直监听消息,如果发送者有消息发给频道,这里会立刻接收到消息
发布者发布消息 publish channel message
--------------------------客户端2(发布者):发布消息给频道 -------------------
# 给“mrtt”这个频道 发送一条消息:“I am mrtt”
127.0.0.1:6379> publish mrtt "I am mrtt"
(integer) 1 # 接收到信息的订阅者数量,无订阅者返回0
客户端2 (发布者) 发布消息给频道后,此时我们再来观察 客户端1 (订阅者) 的客户端窗口变化:
# --------------------------客户端1(订阅者) :订阅频道 -----------------
127.0.0.1:6379> subscribe mrtt csdn
Reading messages... (press Ctrl-C to quit)
1) "subscribe" -- 返回值类型:表示订阅成功!
2) "mrtt" -- 订阅频道的名称
3) (integer) 1 -- 当前客户端已订阅频道的数量
1) "subscribe"
2) "csdn"
3) (integer) 2
---------------------变化如下:(实时接收到了该频道的发布者的消息)------------
1) "message" -- 返回值类型:消息
2) "mrtt" -- 来源(从哪个频道发过来的)
3) "I am mrtt" -- 消息内容
详解请见:https://blog.csdn.net/w15558056319/article/details/121490953
redis集群
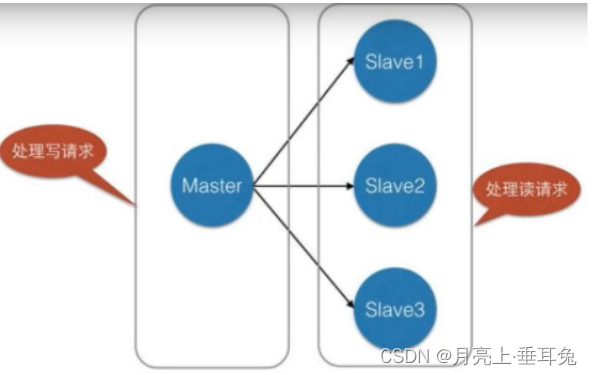
使用redis的复制功能创建主机和从机(一对多) 主从机支持多个数据库之间的数据同步。一类是主数据库
(master主机)一类是从数据库(slave从机)(主从复制) 读写分离
主数据库可以进行读写操作,当发生写操作的时候自动将数据同步到从数据库,而从数据库一般是只读的(读
写分离)
从机接收主数据库同步过来的数据,一个主数据库可以有多个从数据库,而一个从数据库只能有一个主数据
库(只有一个老大)
通过redis的复制功能可以很好的实现数据库的读写分离,提高服务器的负载能力。主数据库主要进行写操
作,而从数据库负责读操作。
这样大部分80%的操作都是读取数据,所以在之前给大家介绍的架构图中,读写分离的方式,从而减轻服务
器压力,这样也就是集群的环境了。
#一般推荐搭建方式为1主2从为最低配。
主从复制(redis集群)的作用
#1 数据冗余: 主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式,在大数据领域,冗余一
般是指一模一样的数据存储多于一份的情况.
#2 数据灾备(故障恢复): 当主节点出现问题时,可以由从节点提供服务,实现快速的故障服务
#3 负载均衡:主从复制的基础之上,可以实现读写分离,提高并发了量。
#4 高可用(集群)基础:主从复制是哨兵和集群实施的基础,因此说redis的主从复制是高可用的基础(集群
环境的基础)
#所以在真实的项目中,我们不可能是单机模式,基本都是搭建redis集群,实现高可用和高并发
集群基础搭建(单机多集群)
基础命令
# info 查看所有配置信息 -- 信息太多。
# info server 服务器信息
# info clients 表示已连接客户端信息
# info cpu CPU 计算量统计信息
# info replication 主从复制信息 **************************
首先查看当前环境信息
# Replication
role:master #表示当前环境为主机
connected_slaves:0 #集群从机连接的数量
master_failover_state:no-failover
master_replid:a38595b7159c4f304a57e43c6352259afd396799
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
准备工作
#将存储方式改为rdb
#搭建1主2从集群 6379 6380 6381
#多复制2份 redis-config 文件 并修改对应的端口号和dump6379.rdb dump6380.rdb dump6381.rdb
#修改pidfile记录文件
#修改启动日志文件名
# 主机配置 - 6379
# 主机端口port --> 6379 不用修改
# pidfile --> 守护进程产生的文件 默认redis_6379 主机也不用改
# 日志logfile --> 改成"6379.log"
# 数据库文件dbfilename --> dump6379.rdb
#从机配置-1 6380
# 主机端口port --> 6380
# pidfile --> 守护进程产生的文件 默认redis_6380
# 日志logfile --> 改成"6380.log"
# 数据库文件dbfilename --> dump6380.rdb
#从机配置-2 6381
# 主机端口port --> 6381
# pidfile --> 守护进程产生的文件 默认redis_6381
# 日志logfile --> 改成"6381.log"
# 数据库文件dbfilename --> dump6381.rdb
启动集群
#启动6379
[root@sunwz redis-7.0.4]# redis-server sunwz/redis6379.conf
[root@sunwz redis-7.0.4]# ps -ef | grep redis
root 66509 1 0 00:06 ? 00:00:00 redis-server *:6379
root 66841 65483 0 00:06 pts/0 00:00:00 grep --color=auto redis
[root@sunwz redis-7.0.4]# redis-cli -p 6379 --raw
127.0.0.1:6379> info replication
# Replication
role:master # 主机
connected_slaves:0
master_failover_state:no-failover
master_replid:a283a0746770b978c00c1768146261d82fe5038c
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379>
启动6380
[root@sunwz redis-7.0.4]# redis-server sunwz/redis6380.conf
[root@sunwz redis-7.0.4]# ps -ef | grep redis
root 66509 1 0 00:06 ? 00:00:00 redis-server *:6379
root 68472 65483 0 00:07 pts/0 00:00:00 redis-cli -p 6379 --raw
root 75357 1 0 00:11 ? 00:00:00 redis-server *:6380
root 76045 71194 0 00:12 pts/2 00:00:00 grep --color=auto redis
[root@sunwz redis-7.0.4]# redis-cli -p 6380 --raw
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:1d2881d7dd50bee528ace73c2129b33f3373cf2a
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
启动6381
[root@sunwz redis-7.0.4]# redis-server sunwz/redis6381.conf
[root@sunwz redis-7.0.4]# ps -ef | grep redis
root 66509 1 0 00:06 ? 00:00:00 redis-server *:6379
root 68472 65483 0 00:07 pts/0 00:00:00 redis-cli -p 6379 --raw
root 75357 1 0 00:11 ? 00:00:00 redis-server *:6380
root 77552 71194 0 00:12 pts/2 00:00:00 redis-cli -p 6380 --raw
root 83211 1 0 00:14 ? 00:00:00 redis-server *:6381
root 83748 80750 0 00:15 pts/4 00:00:00 grep --color=auto redis
[root@sunwz redis-7.0.4]# redis-cli -p 6381 --raw
一主二从配置
#默认情况下,每一台redis服务器都是主节点 - 所以我们只要配置从机就可以了!!
#分别连接客户端(对应端口登录) 通过 info replication查看情况 — 默认都是主机
主(6379) 从(6380,6381)
配置命令
slaveof ip port
#===========6380认老大==============
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
#=============6381认老大===============
127.0.0.1:6381> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
# ==============查看主机==============
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=168,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=168,lag=1
测试:数据是否同步。
注意:我们这里使用的是命令配置的,如果服务器重启就会消失配置,真是的企业环境都配置到配置文件
中,这样就是永久配置了。
读写分离(默认)
redis实现了主从复制之后默认就是读写分离的。如果想set数据,那么只能在master主机中才能进行存储。
# 主机--写
# 从机--读
# 并且主机中所有的数据都会被从机保存
#测试从机写数据
127.0.0.1:6380> set k110 ceshi
(error) READONLY You can't write against a read only replica.
127.0.0.1:6380>
#测试主机宕机从机是否还能正常读取
127.0.0.1:6380> keys *
1) "k1" #值存在
127.0.0.1:6380> info replication
# Replication
role:slave #并且依然是从机模式
master_host:127.0.0.1
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
#测试恢复主机,测试是否还能同步(可以的)
总结:主机断开,从机依然能正常获取数据,但是没有写操作了,当主机恢复后,依然能够同步数据(高可
用)
#测试从机宕机,主机继续增加数据,查看从机是否获取,从新连接之后继续增加数据查看是否能获取
127.0.0.1:6380> shutdown
not connected> exit
[root@sunwz redis-7.0.4]# redis-server sunwz/redis6380.conf
[root@sunwz redis-7.0.4]# redis-cli -p 6380 --raw
127.0.0.1:6380> get u
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:d7cead93f6383df180b3c1de6750d425049c8612
master_replid2:c84b86fcd5b2f7d723431edbfe33d1d4abf28152
master_repl_offset:7661
second_repl_offset:7662
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:7662
repl_backlog_histlen:0
127.0.0.1:6380> slaveof 127.0.0.1 6379
OK
127.0.0.1:6380> get u
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:2
master_sync_in_progress:0
slave_read_repl_offset:7928
slave_repl_offset:7928
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:c84b86fcd5b2f7d723431edbfe33d1d4abf28152
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:7928
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:7929
repl_backlog_histlen:0
127.0.0.1:6380> keys *
stu
u
ww
name
127.0.0.1:6380> get u
123
127.0.0.1:6380>
从机宕机后,此时剩余的一主一从可以正常工作,从机6380恢复之后,不能直接同步数据,原因是通过命令
进行挂载的主机,重新启动后默认当前6380是主机,如果继续保持这个集群环境,需要我们再次通过
slaveof host port 指定老大,指定之后所有的数据会同步到从机中。
#如果我们这个集群通过配置文件搭建的,是否能够避免上述问题。
修改配置文件
# replicaof <masterip> <masterport>
# replicaof 127.0.0.1 6379 #将当前6381 挂载到6379上
重新启动从机
127.0.0.1:6381> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_read_repl_offset:8754
slave_repl_offset:8754
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:c84b86fcd5b2f7d723431edbfe33d1d4abf28152
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:8754
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:8279
repl_backlog_histlen:476
127.0.0.1:6381> keys *
ww
name
stu
u