一、集群概述
Redis的数据是存放在内存中的,这就意味着redis不适合存储大数据,大数据存储一般公司常用hadoop中的Hbase或者MogoDB。因此redis主要用来处理高并发的,用电商项目来说,电商项目如果并发大的话,一台单独的redis是不能足够支持我们的并发,这就需要我们扩展多台设备协同合作,即用到集群。
Redis搭建集群的方式有多种,例如:客户端分片、Twemproxy、Codis等,但是redis3.0之后就支持redis-cluster集群,这种方式采用的是无中心结构,每个节点保存数据和整个集群的状态,每个节点都和其他所有节点连接。节点之间会定时的互相发送ping命令,测试节点的健康状态,当节点接受到ping命令后,会返回一个pong字符串。
二、Redis的容错机制
投票机制:
如果一个节点A给节点B发送ping没有得到pong返回,会通知其他节点再次给B发送ping,如果集群中有超过一半的节点收不B节点的pong。那么就认为B节点挂了。一般会为每个节点提供一个备份节点,如果挂掉会切换到备份节点。

1、所有的节点都通过PING-PONG机制彼此互相连接;
2、每个节点的fail是通过集群中超过半数的节点检测失效时才生效;
3、客户端与redis集群连接,只需要连接集群中的任何一个节点即可;
4、Redis-cluster把所有的物理节点映射到【0-16383】slot上,负责维护
三、 Redis的持久化
Redis是内存型数据库,同时它也可以持久化到硬盘中,redis的持久化方式有两种:
1、RDB(半持久化方式):
按照配置不定期的通过异步的方式、快照的形式直接把内存中的数据持久化到磁盘的一个dump.rdb文件(二进制文件)中;
这种方式是redis默认的持久化方式,它在配置文件(redis.conf)中的格式是:save N M,表示的是在N秒之内发生M次修改,则redis抓快照到磁盘中;
**原理:**当redis需要持久化的时候,redis会fork一个子进程,这个子进程会将数据写到一个临时文件中;当子进程完成写临时文件后,会将原来的.rdb文件替换掉,这样的好处是写时拷贝技术(copy-on-write),可以参考下面的流程图;

**优点:**只包含一个文件,对于文件备份、灾难恢复而言,比较实用。因为我们可以轻松的将一个单独的文件转移到其他存储媒介上;性能最大化,因为对于这种半持久化方式,使用的是写时拷贝技术,可以极大的避免服务进程执行IO操作;想对于AOF来说,如果数据集很大,RDB的启动效率就会很高
缺点:如果想保证数据的高可用(最大限度的包装数据丢失),那么RDB这种半持久化方式不是一个很好的选择,因为系统一旦在持久化策略之前出现宕机现象,此前没有来得及持久化的数据将会产生丢失;rdb是通过fork进程来协助完成持久化的,因此当数据集较大的时候,我们就需要等待服务器停止几百毫秒甚至一秒;
2、AOF(全持久化的方式):
把每一次数据变化都通过write()函数将你所执行的命令追加到一个appendonly.aof文件里面;事实上,不会立即将命令写入硬盘文件中,而是写入硬盘缓存,可以配置策略,配置多久从硬盘缓存写入到硬盘文件中。
Appendfsync always
Appendfsync everysec 默认的
Appendfsync no 不主动,默认30秒一次
Redis默认是不支持这种全持久化方式的,需要将no改成yes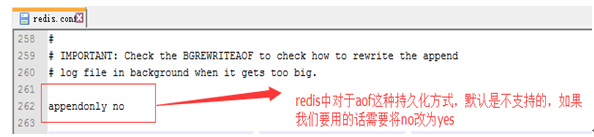
实现文件刷新的三种方式:

no:不会自动同步到磁盘上,需要依靠OS(操作系统)进行刷新,效率快,但是安全性就比较差;
always:每提交一个命令都调用fsync刷新到aof文件,非常慢,但是安全;
everysec:每秒钟都调用fsync刷新到aof文件中,很快,但是可能丢失一秒内的数据,推荐使用,兼顾了速度和安全;
**原理:**redis需要持久化的时候,fork出一个子进程,子进程根据内存中的数据库快照,往临时文件中写入重建数据库状态的命令;父进程会继续处理客户端的请求,除了把写命令写到原来的aof中,同时把收到的写命令缓存起来,这样包装如果子进程重写失败的话不会出问题;当子进程把快照内容以命令方式写入临时文件中后,子进程会发送信号给父进程,父进程会把缓存的写命令写入到临时文件中;接下来父进程可以使用临时的aof文件替换原来的aof文件,并重命名,后面收到的写命令也开始往新的aof文件中追加。下面的图为最简单的方式,其实也是利用写时复制原则。

优点:
数据安全性高
该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机问题,也不会破坏日志文件中已经存在的内容;
如果日志文件过大,可以采用rewriter机制
Rewriter机制:
aof文件中存放了所有的redis操作指令,当aof文件达到一定条件或者手动bgrewriteaof命令都可以触发rewriter,Rewriter函数执行完成之后,aof文件中会保存keys的最后状态,清楚之前冗余的状态,从而达到缩小这个文件的作用可以在配置文件中设置Auto-aof-rewrite-percentage 100:当前写入日志文件的大小超过上一次rewriter之后的文件大小的百分之100时(也就是2倍的时候)触发rewriter这个函数。
缺点:
对于数量相同的数据集来说,aof文件通常要比rdb文件大,因此rdb在恢复大数据集时的速度大于AOF;根据同步策略的不同,AOF在运行效率上往往慢于RDB,每秒同步策略的效率是比较高的,同步禁用策略的效率和RDB一样高效;
针对以上两种不同的持久化方式,如果缓存数据安全性要求比较高的话,用aof这种持久化方式(比如项目二中的购物车);如果对于大数据集要求效率高的话,就可以使用默认的。而且这两种持久化方式可以同时使用。