版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_20095389/article/details/87092396
1、统计学习方法
监督学习,非监督学习,半监督学习,强化学习等。
2、监督学习
输入X和输出Y具有联合分布概论的假设是监督学习关于数据的基本假设。
- 输入空间
- 特征空间
- 假设空间 :监督学习的目的在于学习一个由输入到输出的映射,这一映射由模型来表示,模型属于由输入空间到输出空间的映射的集合,这个集合就是假设空间。
3、统计学习三要素
方法 = 模型 + 策略 + 算法
- 模型:所要学习的条件概率分布或决策函数。
- 策略:按照什么样的准则学习或者选择最优的模型。我将它理解为如何制定目标函数。
- 算法:学习模型的具体计算方法。我将它理解为如何求解目标函数最优化的方法,例如深度学习中的BP等。
4、 解决过拟合的方法
正则化
让所求的参数具有稀疏性,增加泛化能力。
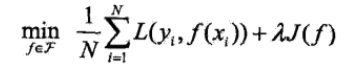
- 【问】L1和L2范数的区别和选择?
L1:倾向产生稀疏参数
L2:倾向产生接近于0的参数
https://www.cnblogs.com/lyr2015/p/8718104.html
交叉验证
重复地使用数据,把给定的数据进行切分,将切分的数据集组合为训练集和测试集,在此基础上反复地进行训练、测试以及模型的选择。
- 简单交叉验证:首先数据集切分成训练集,测试集两部分(例如70%训练,30%测试);其次 用训练集在各种条件下(例如,不同参数个数)训练模型,从而得到不同的模型;最后 在测试集上评价各个模型的训练误差,选出测试误差最小的模型。
- S折交叉验证:首先随机的将数据切分为S个互不相交的大小相同的子集;其次 利用S-1个自己的数据训练模型,利用余下的自己测试模型;然后 将这一过程对可能的S种选择重复进行;最后 选出S次评测中平均测试误差最小的模型。

- 留一交叉验证:将S折中的测试集变成一个数据样本,即为留一交叉验证。
5、生成模型与判别模型
生成方法
- 可以还原出联合概率分布P(X,Y)
- 学习收敛速度快,即当样本容量增加的时候,学到的模型可以更快的收敛于真实模型。
- 当存在隐变量时,仍可以用生成方法学习。
- 朴素贝叶斯,隐马尔科夫模型
判别方法
- 直接学习条件概率P(Y|X)或决策函数f(X),直接面对预测,往往学习的准确率更高。
- 对数据进行某种程度上的抽象、定义特征并使用特征,可以简化学习问题。
- k近邻法、感知机、决策树、logist回归模型,最大熵模型,支持向量机,提升方法,条件随机场
6、分类问题评价方法
TP —— 将正类预测为正类数
FN —— 将正类预测为负类数
FP —— 将负类预测为正类数
FN —— 将负类预测为负类数
精确率:
召回率:
F1值:
精确度召回率都高时,F1值也会高。