思路
选定起始人 选一个关注数或者粉丝数多的大V作为爬虫起始点
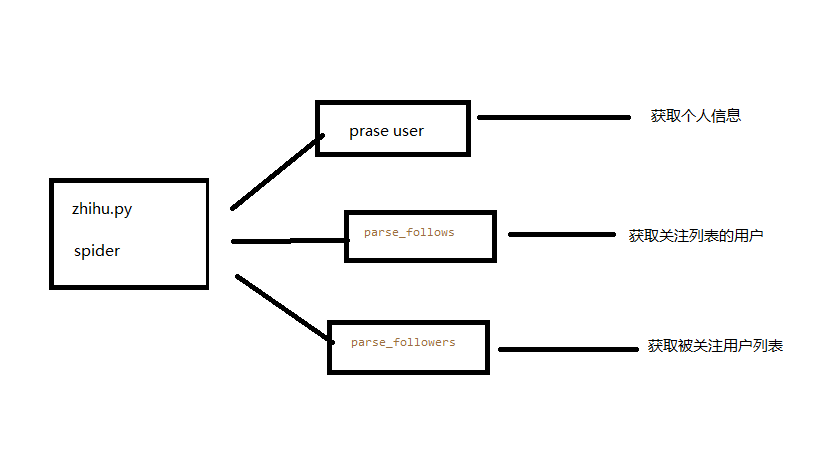
获取粉丝和关注列表 通过知乎接口获得该大V的粉丝列表和关注列表
获取列表用户信息 获取列表每个用户的详细信息
获取每个用户的粉丝和关注 进一步对列表中的每个用户 获取他们的粉丝和关注列表实现递归爬取
起始点 https://www.zhihu.com/people/excited-vczh/answers
抓取信息
个人信息
关注列表 ajax请求
代码实现
./items.py文件
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html from scrapy import Item, Field class UserItem(Item): # define the fields for your item here like: id = Field() name = Field() avatar_url = Field() headline = Field() description = Field() url = Field() url_token = Field() gender = Field() cover_url = Field() type = Field() badge = Field() answer_count = Field() articles_count = Field() commercial_question_count = Field() favorite_count = Field() favorited_count = Field() follower_count = Field() following_columns_count = Field() following_count = Field() pins_count = Field() question_count = Field() thank_from_count = Field() thank_to_count = Field() thanked_count = Field() vote_from_count = Field() vote_to_count = Field() voteup_count = Field() following_favlists_count = Field() following_question_count = Field() following_topic_count = Field() marked_answers_count = Field() mutual_followees_count = Field() hosted_live_count = Field() participated_live_count = Field() locations = Field() educations = Field() employments = Field()
./middlewares.py文件
# -*- coding: utf-8 -*- # Define here the models for your spider middleware # # See documentation in: # http://doc.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals class ZhihuSpiderMiddleware(object): # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the spider middleware does not modify the # passed objects. @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s def process_spider_input(response, spider): # Called for each response that goes through the spider # middleware and into the spider. # Should return None or raise an exception. return None def process_spider_output(response, result, spider): # Called with the results returned from the Spider, after # it has processed the response. # Must return an iterable of Request, dict or Item objects. for i in result: yield i def process_spider_exception(response, exception, spider): # Called when a spider or process_spider_input() method # (from other spider middleware) raises an exception. # Should return either None or an iterable of Response, dict # or Item objects. pass def process_start_requests(start_requests, spider): # Called with the start requests of the spider, and works # similarly to the process_spider_output() method, except # that it doesn’t have a response associated. # Must return only requests (not items). for r in start_requests: yield r def spider_opened(self, spider): spider.logger.info('Spider opened: %s' % spider.name)
./pipelines.py文件
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html import pymongo class ZhihuPipeline(object): def process_item(self, item, spider): return item class MongoPipeline(object): collection_name = 'users' def __init__(self, mongo_uri, mongo_db): self.mongo_uri = mongo_uri self.mongo_db = mongo_db @classmethod def from_crawler(cls, crawler): return cls( mongo_uri=crawler.settings.get('MONGO_URI'), mongo_db=crawler.settings.get('MONGO_DATABASE') ) def open_spider(self, spider): self.client = pymongo.MongoClient(self.mongo_uri) self.db = self.client[self.mongo_db] def close_spider(self, spider): self.client.close() def process_item(self, item, spider): self.db[self.collection_name].update({'url_token': item['url_token']}, dict(item), True) return item
./settings.py文件
# -*- coding: utf-8 -*- # Scrapy settings for zhihuuser project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # http://doc.scrapy.org/en/latest/topics/settings.html # http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html # http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html BOT_NAME = 'zhihuuser' SPIDER_MODULES = ['zhihuuser.spiders'] NEWSPIDER_MODULE = 'zhihuuser.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent # USER_AGENT = 'zhihu (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16) # CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs # DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: # CONCURRENT_REQUESTS_PER_DOMAIN = 16 # CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) # COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) # TELNETCONSOLE_ENABLED = False # Override the default request headers: DEFAULT_REQUEST_HEADERS = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36', 'authorization': 'oauth c3cef7c66a1843f8b3a9e6a1e3160e20', } # Enable or disable spider middlewares # See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html # SPIDER_MIDDLEWARES = { # 'zhihuuser.middlewares.ZhihuSpiderMiddleware': 543, # } # SPIDER_MIDDLEWARES = { # 'scrapy_splash.SplashDeduplicateArgsMiddleware': 100, # } # Enable or disable downloader middlewares # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html # DOWNLOADER_MIDDLEWARES = { # 'zhihuuser.middlewares.MyCustomDownloaderMiddleware': 543, # } # DOWNLOADER_MIDDLEWARES = { # 'scrapy_splash.SplashCookiesMiddleware': 723, # 'scrapy_splash.SplashMiddleware': 725, # 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810, # } # Enable or disable extensions # See http://scrapy.readthedocs.org/en/latest/topics/extensions.html # EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, # } # Configure item pipelines # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'zhihuuser.pipelines.MongoPipeline': 300, # 'scrapy_redis.pipelines.RedisPipeline': 301 } # Enable and configure the AutoThrottle extension (disabled by default) # See http://doc.scrapy.org/en/latest/topics/autothrottle.html # AUTOTHROTTLE_ENABLED = True # The initial download delay # AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies # AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server # AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: # AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings # HTTPCACHE_ENABLED = True # HTTPCACHE_EXPIRATION_SECS = 0 # HTTPCACHE_DIR = 'httpcache' # HTTPCACHE_IGNORE_HTTP_CODES = [] # HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' # DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter' # HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage' # SPLASH_URL = 'http://192.168.99.100:8050' MONGO_URI = 'localhost' MONGO_DATABASE = 'zhihu' # SCHEDULER = "scrapy_redis.scheduler.Scheduler" # DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # SCHEDULER_FLUSH_ON_START = True
./spiders文件夹下 zhihu.py文件
# -*- coding: utf-8 -*- import json from scrapy import Spider, Request from zhihuuser.items import UserItem class ZhihuSpider(Spider): name = "zhihu" allowed_domains = ["www.zhihu.com"] user_url = 'https://www.zhihu.com/api/v4/members/{user}?include={include}' follows_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}' followers_url = 'https://www.zhihu.com/api/v4/members/{user}/followers?include={include}&offset={offset}&limit={limit}' start_user = 'excited-vczh' user_query = 'locations,employments,gender,educations,business,voteup_count,thanked_Count,follower_count,following_count,cover_url,following_topic_count,following_question_count,following_favlists_count,following_columns_count,answer_count,articles_count,pins_count,question_count,commercial_question_count,favorite_count,favorited_count,logs_count,marked_answers_count,marked_answers_text,message_thread_token,account_status,is_active,is_force_renamed,is_bind_sina,sina_weibo_url,sina_weibo_name,show_sina_weibo,is_blocking,is_blocked,is_following,is_followed,mutual_followees_count,vote_to_count,vote_from_count,thank_to_count,thank_from_count,thanked_count,description,hosted_live_count,participated_live_count,allow_message,industry_category,org_name,org_homepage,badge[?(type=best_answerer)].topics' follows_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics' followers_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics' def start_requests(self): yield Request(self.user_url.format(user=self.start_user, include=self.user_query), self.parse_user) yield Request(self.follows_url.format(user=self.start_user, include=self.follows_query, limit=20, offset=0), self.parse_follows) yield Request(self.followers_url.format(user=self.start_user, include=self.followers_query, limit=20, offset=0), self.parse_followers) def parse_user(self, response): result = json.loads(response.text) item = UserItem() for field in item.fields: if field in result.keys(): item[field] = result.get(field) yield item yield Request( self.follows_url.format(user=result.get('url_token'), include=self.follows_query, limit=20, offset=0), self.parse_follows) yield Request( self.followers_url.format(user=result.get('url_token'), include=self.followers_query, limit=20, offset=0), self.parse_followers) def parse_follows(self, response): results = json.loads(response.text) if 'data' in results.keys(): for result in results.get('data'): yield Request(self.user_url.format(user=result.get('url_token'), include=self.user_query), self.parse_user) if 'paging' in results.keys() and results.get('paging').get('is_end') == False: next_page = results.get('paging').get('next') yield Request(next_page, self.parse_follows) def parse_followers(self, response): results = json.loads(response.text) if 'data' in results.keys(): for result in results.get('data'): yield Request(self.user_url.format(user=result.get('url_token'), include=self.user_query), self.parse_user) if 'paging' in results.keys() and results.get('paging').get('is_end') == False: next_page = results.get('paging').get('next') yield Request(next_page, self.parse_followers)
最后运行zhihu.py爬虫脚本 再查看MongoDB数据库中的数据 知乎用户信息数据采集就完成了。
那些步骤不理解的 欢迎下方留言