知乎介绍: 知乎是网络问答社区,连接各行各业的用户。用户分享着彼此的知识、经验和见解,为中文互联网源源不断地提供多种多样的信息。准确地讲,知乎更像一个论坛:用户围绕着某一感兴趣的话题进行相关的讨论,同时可以关注兴趣一致的人。对于概念性的解释,网络百科几乎涵盖了你所有的疑问;但是对于发散思维的整合,却是知乎的一大特色。2017年11月8日,知乎入选时代影响力·中国商业案例TOP30。
知乎官网: https://www.zhihu.com/
编程环境: python3.6,win10,goole
技术要求:
- 全程selenium模拟
- 模拟登录,使用第三方登录
- 点击定位节点
- 模拟下拉加载数据
- 获取用户URL地址
- 打开用户详情页面
- 获取网页源码
- 提取信息
- 保存信息
注册: 如果想使用知乎,必须要进行注册。注册后可以使用账号模拟登录,也可以使用知乎APP扫码登录,但是我下载的知乎APP注册后不能使用扫码功能,所以我是使用第三方账号登录(社交帐号登录) 登录知乎,写代码时前提前登录QQ,点击它就可以直接登录知乎了。
详细步骤讲解
1、模拟登录
搜索数据前必须要登录网站,我直接使用第三方平台登录,可以省掉验证码这个环节,先在电脑上登录QQ,使用QQ账号登录知乎。

实现点击QQ,使用第三方登录
driver.get('https://www.zhihu.com/')#打开知乎官网
driver.implicitly_wait(6)#等待加载六秒
driver.find_element_by_xpath('//*[@id="root"]/div/main/div/div/div[3]/span[2]/div[2]').click()#点击刚复制的节点元素
# 等待扫码登录
time.sleep(5)#点击QQ账号或扫码的时间只有5秒,速度一定要快点,也可以太调大点

2、 点击定位节点
selenium定位搜索框,输入关键词并回车
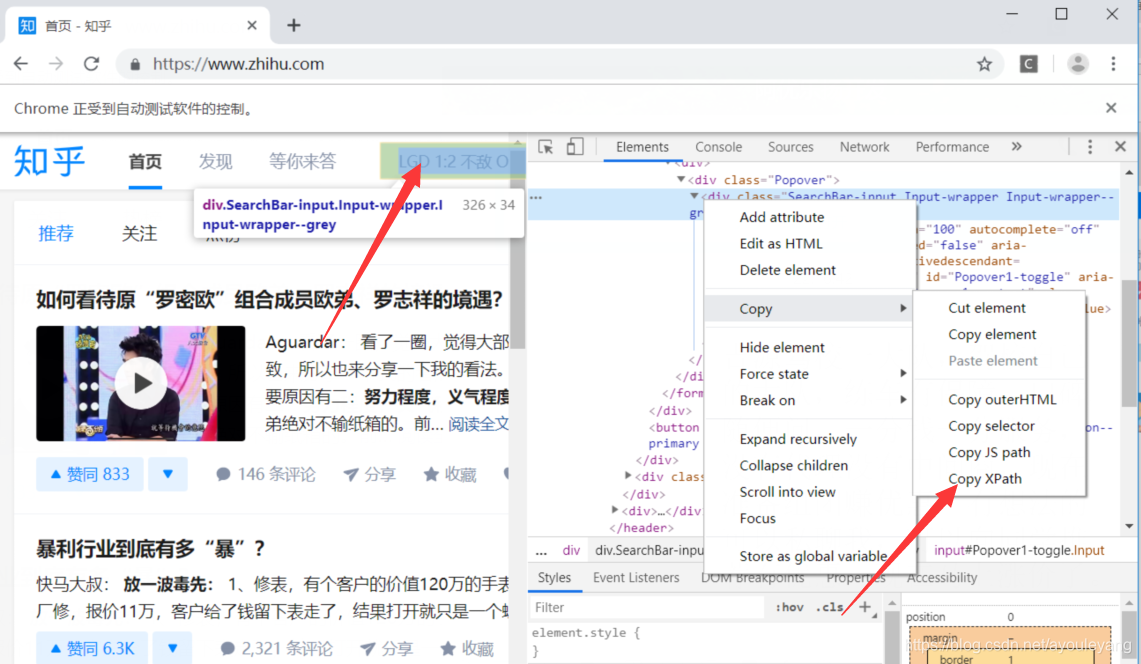
search = driver.find_element_by_xpath('//*[@id="Popover1-toggle"]')#定位搜索框节点
search.send_keys("金融")#输入搜素词
search.send_keys(Keys.ENTER)#点击回车
driver.implicitly_wait(6)
driver.find_element_by_xpath('//*[@id="root"]/div/main/div/div[1]/div/div/ul/li[2]/a').click()#定位用户节点并点击
time.sleep(3)#等待三秒
3、 模拟下拉加载数据
知乎的用户是通过下拉加载的,下拉多少就加载多少,由于用户太多,可以通过这个方法来控制加载的用户信息。
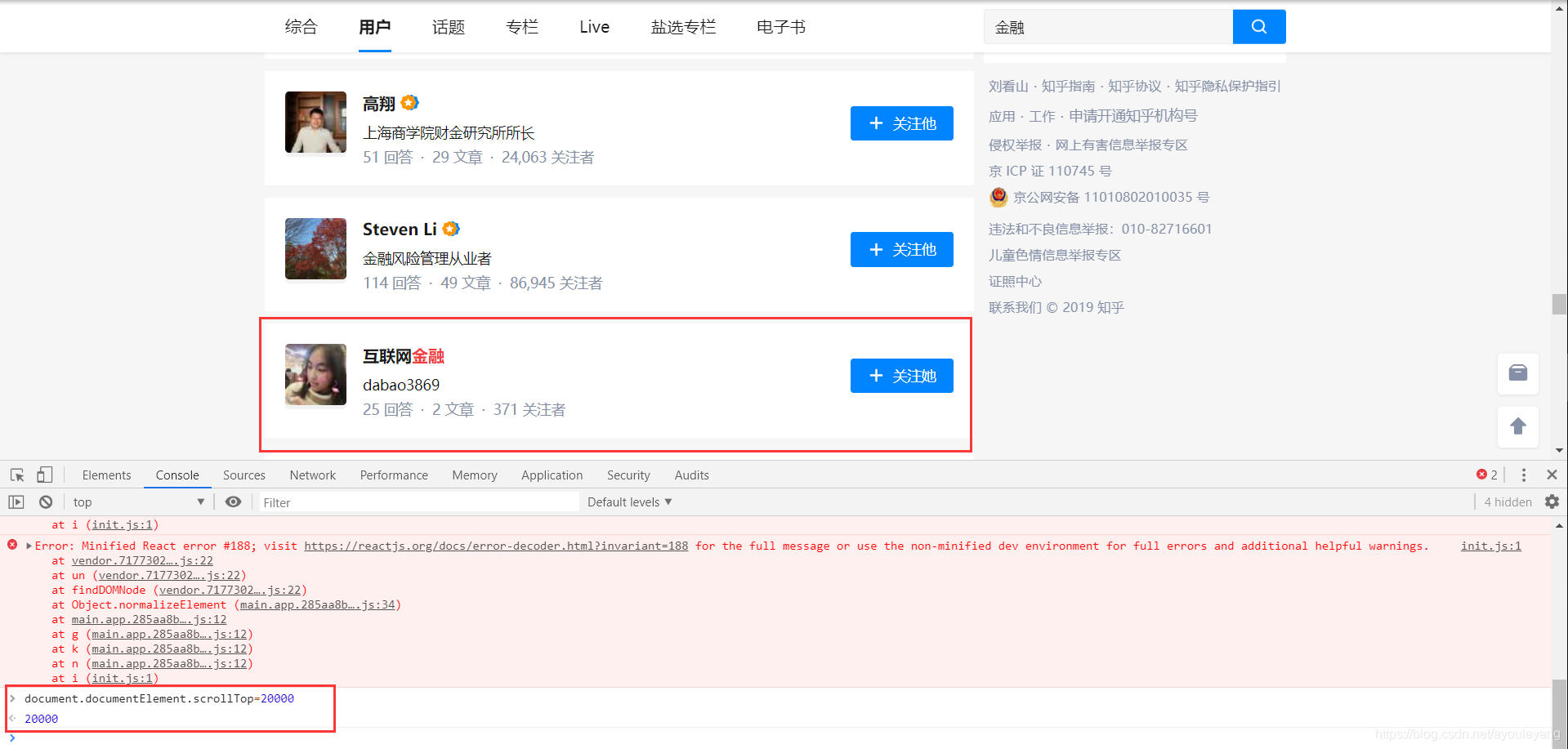
for i in range(400,2000,500):
time.sleep(1)#延时,模拟人为加载
js=f"document.documentElement.scrollTop={i}"#下拉加载
driver.execute_script(js)
4、 获取用户URL地址
每个用户都有一个对应的URL,需要获取每个对应URL

for links in html.xpath('//*[@id="SearchMain"]/div/div/div/div/div'):
link = links.xpath('./div/div/div/div[2]/h2/div/span/div/div/a/@href')
if int(len(link)) !=0:#过滤掉空的数组
link = link[0]
print (link)
输出结果:
//www.zhihu.com/org/yun-feng-jin-rong
//www.zhihu.com/org/hai-er-chan-ye-jin-rong-lu-se-jin-rong
//www.zhihu.com/people/jinrongbaguanv
//www.zhihu.com/people/jrxmj
..............
拼接成完整的URL"https:"+str(link[0]) ,不然会被浏览器误认为是打开本地文件
5、打开用户详情页面
可以再次使用driver.get() 分别打开链接

进来的页面并还没有我们需要的信息,我们需要点击“查看详细资料”才能加载到他的数据

driver.find_element_by_xpath('//*[@id="ProfileHeader"]/div/div[2]/div/div[2]/div[3]/button').click()#点击“查看详细资料”加载数据
source = driver.page_source #获取网页源代码
6、 提取信息
我们得到网页源码后,可以使用 lxml 解析网页,再用它通过xpath节点获取信息,因为这个页面的信息位置并不重复,所以并不需要使用迭代循环输出数据,直接定位每个节点就可以了。
7、保存信息
把获取到的所有信息保存到Excel,作为永久信息,方便查看。
8、所有代码汇总
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from lxml import etree
import time,xlwt
all_page = []#定义数组
driver = webdriver.Chrome()
driver.implicitly_wait(5)
chrome_option = webdriver.ChromeOptions()
chrome_option.add_argument('--proxy--server=127.0.0.1:8080')#使用代理IP,告诉服务器这是人为操作
driver.get('https://www.zhihu.com/')#打开知乎官网
driver.implicitly_wait(6)#等待加载六秒
driver.find_element_by_xpath('//*[@id="root"]/div/main/div/div/div[3]/span[2]/div[2]').click()#点击刚复制的节点元素
# 等待扫码登录
time.sleep(5)#点击QQ账号或扫码的时间只有5秒,速度一定要快点,也可以太调大点
def start():
search = driver.find_element_by_xpath('//*[@id="Popover1-toggle"]')#定位输入框节点
search.send_keys("金融")#输入关键词
search.send_keys(Keys.ENTER)#回车
driver.implicitly_wait(6)
driver.find_element_by_xpath('//*[@id="root"]/div/main/div/div[1]/div/div/ul/li[2]/a').click()#定位用户节点并点击
scroll()
def scroll():
for i in range(400,2000,500):
time.sleep(1)#延时,模拟人为加载
js=f"document.documentElement.scrollTop={i}"#下拉加载
driver.execute_script(js)#操作js
user_link()
def user_link():
source = driver.page_source#获取网页源码
html = etree.HTML(source)#lxml解析网页
for links in html.xpath('//*[@id="SearchMain"]/div/div/div/div/div'):
link = links.xpath('./div/div/div/div[2]/h2/div/span/div/div/a/@href')#获取所有用户URL
if int(len(link)) !=0:#过滤掉数组为空的URL
linkStr = "https:"+str(link[0])#拼接出完整的URL
userList.append(linkStr)#追加到userList数组中
def getUserPage():
for item in userList:
driver.get(item)#分别打开每个用户的URL
# 点击详情
driver.find_element_by_xpath('//*[@id="ProfileHeader"]/div/div[2]/div/div[2]/div[3]/button').click()#点击“查看详细资料”加载数据
source = driver.page_source
spider(source)
def spider(source):
html = etree.HTML(source)
array=[]
#用户名称
name = html.xpath('//*[@id="ProfileHeader"]/div/div[2]/div/div[2]/div[1]/h1/span/text()')
name = ''.join(name)
#用户介绍
introduce = html.xpath('//*[@id="ProfileHeader"]/div/div[2]/div/div[2]/div[2]/div/div/text()')
introduce = ''.join(introduce)
#发表文章
writer = html.xpath('//*[@id="ProfileMain"]/div[1]/ul/li[4]/a/span/text()')
writer = ''.join(writer)
#发表的想法
idear = html.xpath('//*[@id="ProfileMain"]/div[1]/ul/li[6]/a/span/text()')
idear = ''.join(writer)#从数组转换成字符串,并把两个以上的长度的数组拼成一个字符串
#关注者人数
closer = html.xpath('//*[@id="root"]/div/main/div/div[2]/div[2]/div[2]/div/a[2]/div/strong/text()')
closer = ''.join(closer)
#所在行业
major = html.xpath('//*[@id="ProfileHeader"]/div/div[2]/div/div[2]/div[2]/div/div/div[2]/div/text()')
major = ''.join(major)
#机构网站
web = html.xpath('//*[@id="ProfileHeader"]/div/div[2]/div/div[2]/div[2]/div/div/div[3]/div/a/span[2]/text()')
web = ''.join(web)
#机构介绍
com_intro = html.xpath('//*[@id="ProfileHeader"]/div/div[2]/div/div[2]/div[2]/div/div/div[4]/div/text()')
com_intro = ''.join(com_intro)
#公司名称
company = html.xpath('//*[@id="ProfileHeader"]/div/div[2]/div/div[2]/div[2]/div/div/div[5]/div/text()')
company = ''.join(company)
print (name,introduce,writer,idear,closer,major,web,com_intro,company,'\n')
page = [name,introduce,writer,idear,closer,major,web,com_intro,company]#生成数组
all_page.append(page)
saveData()
def saveData():
book = xlwt.Workbook(encoding = 'utf-8')#创建工作簿
sheet = book.add_sheet('jinrong',cell_overwrite_ok=True)#创建表名,cell_overwrite_ok=True用于确认同一个cell单元是否可以重设值
head = ['用户','介绍','发表文章','发表想法','关注者(人)','所在行业','机构网站','机构介绍','机构主体']#定义表头,即Excel中第一行标题
for h in range(len(head)):
sheet.write(0,h,head[h])#写入表头
j = 1#第一行开始
for list in all_page:
k = 0
for date in list:
sheet.write(j,k,date)#迭代列,并写入数据,重新设置,需要cell_overwrite_ok=True
k = k+1
j = j+1
book.save('G:\zhihu_users.xls')
if __name__ == '__main__':
start()
getUserPage()
编辑器运行部分截图:

Excel部分截图:

