版权声明:不要转载复制当原创就好了,指明下参考地址或者书目,大家一起学习进步。 https://blog.csdn.net/Monk_donot_know/article/details/86681938
参考文献:黄红梅,张良均等.Python数据分析与应用[M].北京:人民邮电出版社,2018.
还有其他的博客,在文中附了链接。
文章目录
1. 数据
采用sklearn自带数据集,鸢尾花数据集。
‘sepal length (cm)’, ‘sepal width (cm)’, ‘petal length (cm)’, 'petal width (cm)'分别是花瓣长度、花瓣宽度、花萼长度、花萼宽度。
2. KMeans参数说明
KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001,
precompute_distances='auto', verbose=0, random_state=None,
copy_x=True, n_jobs=None, algorithm='auto')
上头显示的就是默认哈~
| 参数 | 说明 |
|---|---|
| n-cluster | 分类簇的数量 |
| max_iter | 最大的迭代次数 |
| n_init | 算法的运行次数 |
| init | 接收待定的string。kmeans++表示该初始化策略选择的初始均值向量之间都距离比较远,它的效果较好;random表示从数据中随机选择K个样本最为初始均值向量;或者提供一个数组,数组的形状为(n_cluster,n_features),该数组作为初始均值向量。 |
| precompute_distance | 接收Boolean或者auto。表示是否提前计算好样本之间的距离,auto表示如果nsamples*n>12 million,则不提前计算。 |
| tol | 接收float,表示算法收敛的阈值。 |
| N_jobs | 表示任务使用CPU数量 |
| random_state | 表示随机数生成器的种子。 |
| verbose | 0表示不输出日志信息;1表示每隔一段时间打印一次日志信息。如果大于1,打印次数频繁。 |
3. 代码及结果
from sklearn.datasets import load_iris
import xlwt
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import MinMaxScaler
print(iris)
iris=load_iris()
iris_data=iris['data']
iris_target=iris['target']
iris_names=iris['feature_names']
print("是骡子是马打印出来看看就知道了:\n",'第一个',iris_data,'\n','第二个',iris_target,'\n','第三个',iris_names)
# 依次是:花瓣长度、花瓣宽度、花萼长度、花萼宽度。
## Z分数标准化标准化
data_zs=(iris_data-iris_data.mean())/iris_data.std()
## 也可以自定义函数minmax标准化、或者现成的函数
scale=MinMaxScaler().fit(iris_data)
iris_datascale=scale.transform(iris_data)
kmeans=KMeans(n_clusters=3,random_state=123,n_jobs=4).fit(iris_datascale)
result=kmeans.predict([[5.6,2.8,4.9,2.0]])
## 这里有点小问题,就是预测的数据需要使用和训练数据同样的标准化才行。
print(result)
#简答打印结果
r1=pd.Series(kmeans.labels_).value_counts()
r2=pd.DataFrame(kmeans.cluster_centers_)
r=pd.concat([r2,r1],axis=1)
r.columns=list(iris_names)+[u'类别数目']
print(r)
#详细输出原结果
r_new=pd.concat([pd.DataFrame(iris_data),pd.Series(kmeans.labels_)],axis=1)
r_new.columns=list(iris_names)+[u'类别数目']
r_new.to_excel("path")## 自定义一个路径,保存在excel里面
是这样的,这本书在聚类时,做了数据标准化。但是我仔细思考了,在量纲一致的情况下是不需要标准化的。
所以预测时候,新的数据需要使用同样的标准化方式才行。
4 聚类结果可视化
import pandas as pd
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
tsne=TSNE(n_components=2,init='random',random_state=177).fit(iris_data)
df=pd.DataFrame(tsne.embedding_)
df['labels']=kmeans.labels_
df1=df[df['labels']==0]
df2=df[df['labels']==1]
df3=df[df['labels']==2]
fig=plt.figure(figsize=(9,6))
plt.plot(df1[0],df1[1],'bo',df2[0],df2[1],'r*',df3[0],df3[1],'gD')
plt.show()
这个TSNE函数就是实现多维数据可视化的展现,n_components设置二维还是三维。

5. 评价聚类模型
5.1 评价体系
| 方法 | 真实值 | 最佳值 | sklearn函数 |
|---|---|---|---|
| ARI(兰德系数) | 需要 | 1.0 | adjusted_rand_score |
| AMI(互信息) | 需要 | 1.0 | adjusted_mutual_info_score |
| V-measure | 需要 | 1.0 | completeness_score |
| FMI | 需要 | 1.0 | fowlkes_mallows_score |
| 轮廓系数 | 不需要 | 畸变程度大 | silhouette_score |
| Calinski_ Harabaz | 不需要 | 最大值 | calinski_harabaz_score |
5.2 FMI评价法
from sklearn.metrics import fowlkes_mallows_score
for i in range(2,7):
kmeans=KMeans(n_clusters=i,random_state=123).fit(iris_data)
score=fowlkes_mallows_score(iris_target,kmeans.labels_)
print("聚类%d簇的FMI分数为:%f" %(i,score))
out:
聚类2簇的FMI分数为:0.750473
聚类3簇的FMI分数为:0.820808
聚类4簇的FMI分数为:0.753970
聚类5簇的FMI分数为:0.725483
聚类6簇的FMI分数为:0.614345
这里没搞懂FMI这块是如何计算的。

这里有个问题就是,iris_target 的标签含义和kmeans.labels_标签的含义是不同的,比如都是1,代表的类别是不同的,后续是怎么区分的????????还有就是FMI这个值是怎么计算的?
在这篇文章中提到计算方式是这样的,可是,这里的P/N是什么?这里是三分类…晕
这篇文章传送门
希望看到这个旁友,懂的话评论解释一下~~谢谢啦!
5.3 轮廓系数
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
silhouettescore=[]
for i in range(2,15):
kmeans=KMeans(n_clusters=i,random_state=123).fit(iris_data)
score=silhouette_score(iris_data,kmeans.labels_)
silhouettescore.append(score)
plt.figure(figsize=(10,6))
plt.plot(range(2,15),silhouettescore,linewidth=1.5,linestyle='-')
plt.show()

这个轮廓系数就是看这条曲线的畸变程度。说直白点就是斜率变化!变化快的部分就是分类的最佳选择。从图中可以看到在2~3,5 ~6两段的变化比较快,结合实际情况判断,还是分三类比较好,而不是分六类。
5.4 Calinski-Harabasz指数评价
from sklearn.metrics import calinski_harabaz_score
for i in range(2,7):
kmeans=KMeans(n_clusters=i,random_state=123).fit(iris_data)
score=calinski_harabaz_score(iris_data,kmeans.labels_)
print("聚类%d簇的calinski_harabaz分数为:%f" %(i,score))
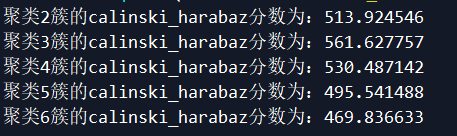
越大越好。所以还是3类最优。