 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
2.3 分类器及损失
2.3.1 线性分类
现在,我们将开发一种功能更强大的图像分类方法,最终将其自然地扩展到整个神经网络和卷积神经网络。线性分类方法。这种方法来主要由两部分,一个函数将输入数据映射到一个类别分数,另一个就是损失函数来量化预测的分数与目标值之间的一致性。
回到之前的CIFAR-10例子,输入训练图像的数据集50000张图片, 向量维度D = 32 x 32 x 3 = 3072像素,K大小为10个类别

我们可以控制参数w,b的设置。我们的目标是设置这些参数,以便计算出的分数与整个训练集中的目标值标签相匹配。这种方法的一个优点是利用训练数据来学习参数w,b,但是一旦学习完成,我们就可以丢弃整个训练集,只保留学习到的参数。
2.3.1.1 线性分类解释


-
解释:w的每一行都是其中一个类的分类器。这些数字的几何解释是,当我们改变w的一行时,像素空间中相应的线将以不同的方向旋转。而其中的偏置是为了让我们避免所有的分类器都过原点。
-
总结:分类器的权重矩阵其实是对应分类的经过训练得到的一个分类模板,通过测试数据与分类模板间的数据计算来进行分类。在训练的过程中,其实可以看作是权重矩阵的学习过程,也可以看成是分类模板的学习过程,如何从训练样本中学习分类的模板。模板权重的大小,反映了样本中每个像素点对分类的贡献率。
学习到的权重
将线性分类器解释为模板匹配。权重w的另一种解释是,w的每一行对应于其中一个类的模板(有时也称为原型)。然后,通过使用内部积(或点积)逐个比较每个模板和图像来获得图像的每个类的分数,以找到“最适合”的模板。我们以CIFAR-10例子,10个类别分类,学习到10个模板,下方显示的即是训练过后所学习的权重矩阵(也即是分类模板)

线性分类器将数据中这两种模式的马合并到一个模板中。类似地,汽车分类器似乎已经将多个模式合并到一个模板中,该模板必须从各个方面识别所有颜色的汽车。特别是,这个模板最终是红色的,这意味着cifar-10数据集中的红色汽车比任何其他颜色的都多。线性分类器太弱,无法正确解释不同颜色的汽车,但正如我们稍后将看到的,神经网络将允许我们执行这项任务。
- 存在问题
- 每个类别,只能学习到一个模板,分类能力是有限的,如果数据集中的图片同一类别差差异较大,那么学习不到太多的东西来进行判别。
- 后面会介绍到的:无法进行非线性的分类(类似于异或的分类)
2.3.2 损失函数
损失函数是用来告诉我们当前分类器性能好坏的评价函数,是用于指导分类器权重调整的指导性函数,通过该函数可以知道该如何改进权重系数。CV与深度学习课程之前,大家应该都接触过一些损失函数了,例如解决二分类问题的逻辑回归中用到的对数似然损失、SVM中的合页损失等等。

现在回到前面的线性分类例子,该函数预测在“猫”、“狗”和“船”类中的分数,我们发现,在这个例子中,我们输入描绘猫的像素,但是猫的分数与其他类别(狗的分数437.9和船的分数61.95)相比非常低(-96.8)。那么这个结果并不好,我们将会去衡量这样的一个成本,如果分类做好了,这个损失将会减少。
多分类问题的损失该如何去衡量?下面会进行通常会使用的两种方式作对比,这里介绍在图像识别中最常用的两个损失——多类别SVM损失(合页损失hinge loss)和交叉熵损失,分别对应多类别SVM分类器和Softmax分类器
2.3.2.1 多分类SVM损失




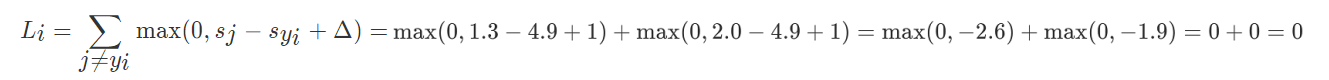



最终得到5.27的分数大小,Loss反映了真实分类所得分数与其他分类分数的差别,也就是说,如果真实分类所得分数比分类为其他类的分数要低,但是分数低多少,要想真实分类的分数最高,差距在哪,即是通过损失函数的l值反映出来了。同时,如果分类正确的分数比其他的分类分数高于1,即使正确分类的分数发生微小变化(相差仍然大于1),那么Hinge Loss仍然有效,损失函数值不会发生变化。

多分类支持向量机损失希望正确分类的分数至少高于其他分类的分数,如果错误分类的分数-正确分类的分数很小即超过上述的红色区域,则不会加入损失;如果在红色区域内部,那么会累积损失。
当然这里为了方便理解,并没有去考虑正则化项的影响,有时候使用L2-SVM损失效果会更好些。
关于深度学习的正则化后面会着重去介绍
2.2.2.2 Softmax 分类(Multinomial Logistic Regression)与cross-entropy(交叉熵损失)
1、Softmax
另外一种就是Softmax,它有着截然不同的损失函数。如果你听说过逻辑回归二分类器,那么Softmax分类器是它泛化到多分类的情形。不像SVM那样会得到某个分类的分数,softmax会给出一个更加合适的输入即归一化的类别概率

理解:Softmax函数接收一组评分输出s(有正有负),对每个评分sk进行指数化确保正数,分母是所有评分指数化的和,分子是某个评分指数化后的值,这样就起到了归一化的作用。某个类的分值越大,指数化后越大,函数输出越接近于1,可以把输出看做该类别的概率值,所有类别的概率值和为一。


2、cross-entropy
交叉熵损失是应用softmax分类之后如何计算损失大小的一种方式,这种方式就来源于信息论理论。


它的损失如何计算?
0log(0.10)+0log(0.05)+0log(0.15)+0log(0.10)+0log(0.05)+0log(0.20)+1log(0.10)+0log(0.05)+0log(0.10)+0log(0.10)
在概率的角度理解,我们在做的事情,就是最小化错误类别的负log似然概率,也可以理解为进行最大似然估计/Maximum Likelihood Estimation (MLE)

# 三个类别分类,并且得到的分数大小
f = np.array([123, 456, 789])
# 1、直接这样计算会存在指数爆炸问题
p = np.exp(f) / np.sum(np.exp(f))
# 2、进行分数平移,得到最大值0
f -= np.max(f) # f becomes [-666, -333, 0]
p = np.exp(f) / np.sum(np.exp(f))
2.3.3 SVM与Softmax对比
下面这张图就清楚的展示了两个分类以及其损失计算方式的区别

实际应用中,两类分类器的表现是相当的,两者差异较小。每个人都回去根据那个表现更好来做选择。如果要对比的话,其中的一些差异如下:

2013年的一篇论文就针对于神经网络损失函数在CIFAR-10等数据集上进行了两种损失对比,参考:Deep Learning using Linear Support Vector Machines,这篇论文就告诉L2-SVM比Softmax效果好一些
现在我们知道了如何基于参数,将数据集中的图像映射成为分类的评分,也知道了两种不同的损失函数,它们都能用来衡量算法分类预测的质量。如何高效地得到能够使损失值最小的参数呢?这个求得最优参数的过程被称为最优化,下节课我们将会介绍。
2.2.4 总结
- 定义了从图像像素映射到不同类别的分类评分的评分函数
- 定义了两种分类器以及损失行数
- SVM 合页损失
- Softmax 交叉熵损失
