在做过汽车之家论坛的字体反爬过后,信心稍微增长点,那么索性找点字体文件反爬的网址,猫眼便是一个不错的网址,那么便开始搞起来。
目标网址
https://piaofang.maoyan.com/?ver=normal
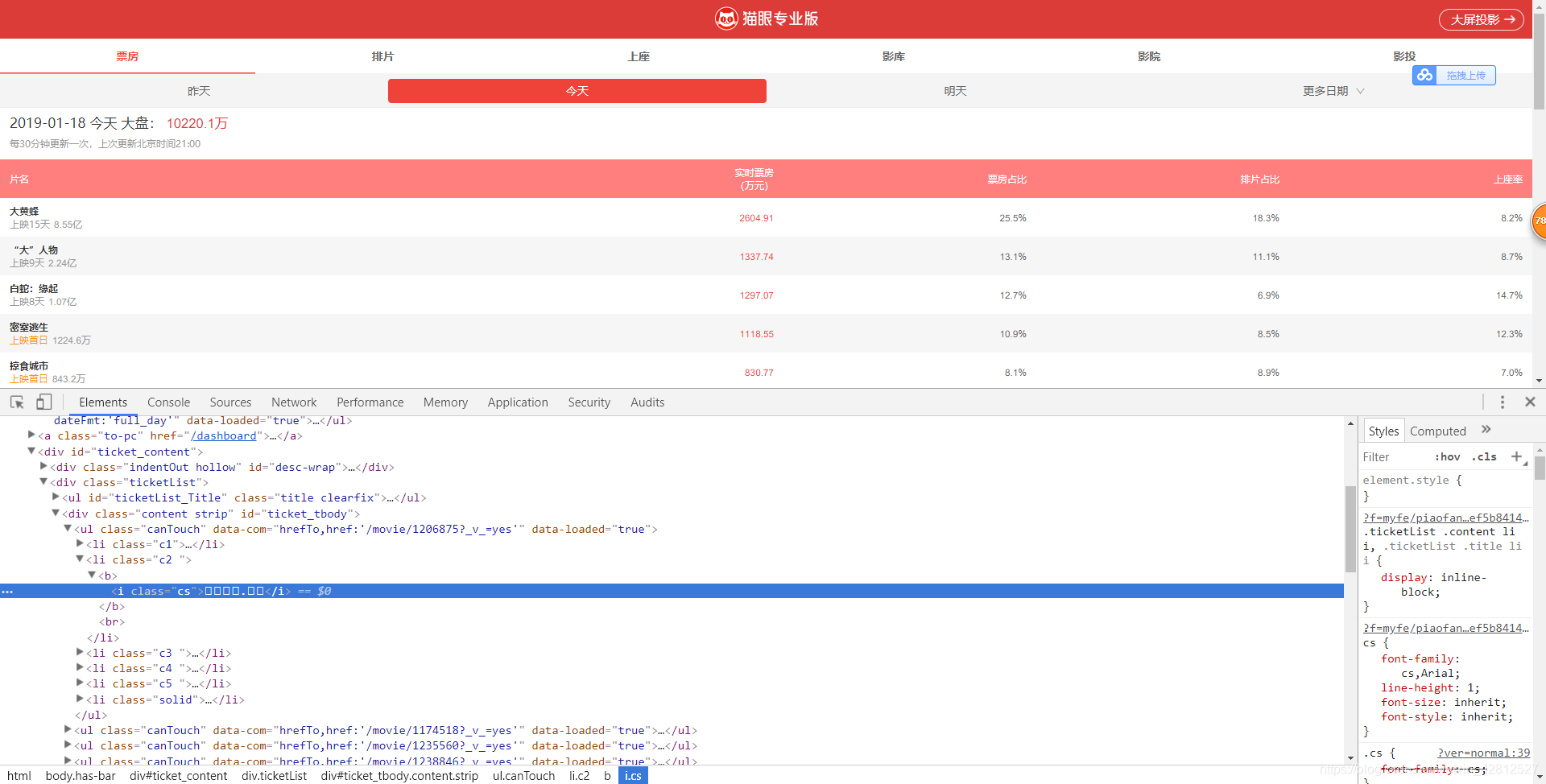
很明显和汽车之家的论坛是字体的加密,那么按照之前的步骤走:
第一步:找到字体文件,下载下来。
第二步:通过Font Creator工具读取下载好的字体文件。
第三步:按顺序拿到各个字符的unicode编码,并写出对应的文字列表。
第四步:将顺序unicode编码写成对应的unicode的类型。
第五步:替换掉文章中对应的unicode的类型的文字。
按照上边的简单的步骤一顿乱搞,发现最后更本就不对,这点作者是深有体会,不禁想这是为什么?想了好久也没有想太明白,那么只有去网上找资源,还好关于猫眼的爬虫不少,作者这里参考了他们的思路,这里列出参考的大神博客:
https://blog.csdn.net/xing851483876/article/details/82928607【作者:Mars_DD】
https://www.jianshu.com/u/10b8bef7b005【作者:董小贱】大家也可以参考他们的,这里作者发现他们也都写汽车之家的爬虫了,肯定比作者写的好。
那么思路是有了,自己还是要实践实践,毕竟只有实践才能更好的掌握,那么就简单分享以下这里作者的实践的思路。
分析
为什么猫眼不同于汽车之家呢?这里最重要的一点是,猫眼这里的字体是多个字体文件,每次访问会给你返回不同的字体的文件,这也就是为什么对不上字体的原因。那么作者便索性访问两次下载两套字体进行对比,如下图:
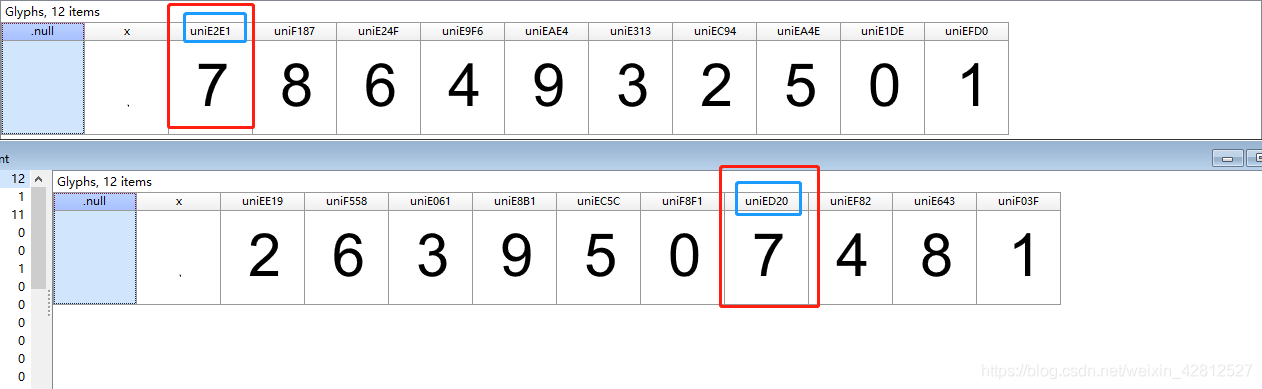
可以发现两次虽然是同一个文字但是字符编码发生了变化,完全和第一个不一样了,这个时候怎么解决呢?不禁考虑虽然对应的字符编码是改变的,那么同一个字体的结构会发生变化吗?(当然这是后话,以后自己可以往这个方向考虑),事实可以通过查看两个个字体文件内部数据结构,方法如下:
from fontTools.ttLib import TTFont
font = TTFont('online_base64.ttf') # 打开本地字体文件online_base64.ttf
font.saveXML('online_base64.xml') # 将ttf文件转化成xml格式并保存到本地,主要是方便我们查看内部数据结构
打开online_base64.xml文件可以看到类似html标签的结构.这里我们用到的标签是<GlyphOrder…>和<glyf…>如下图:
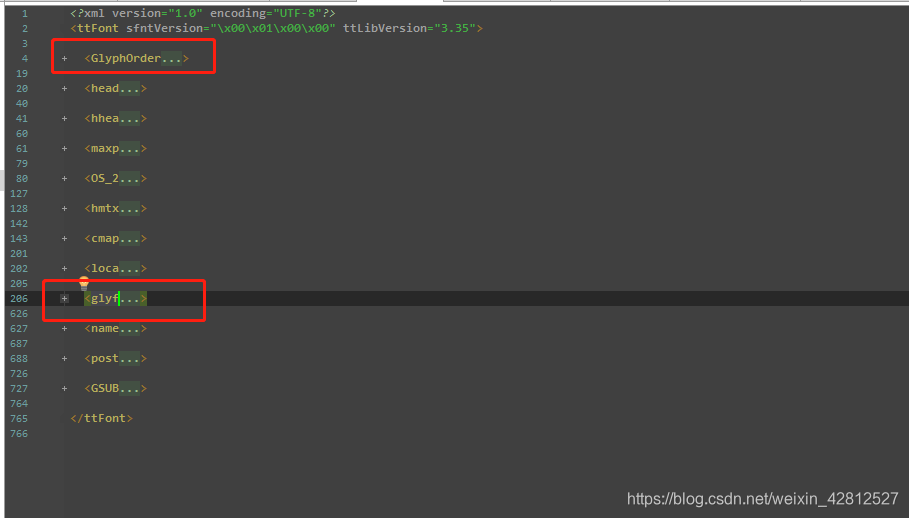
那么看一下<GlyphOrder…>标签,内包含着所有编码信息,注意前两个是不是0-9的编码,需要去除。如下图

在看一下<glyf…>标签 内包含着每一个字符对象,同样第一个和最后一个不是0-9的字符,需要祛除。在这里自己有点小理解:可以打开另外一个字体的结构,发现对象的结构是不变的,变化的只是对应的字符编码。
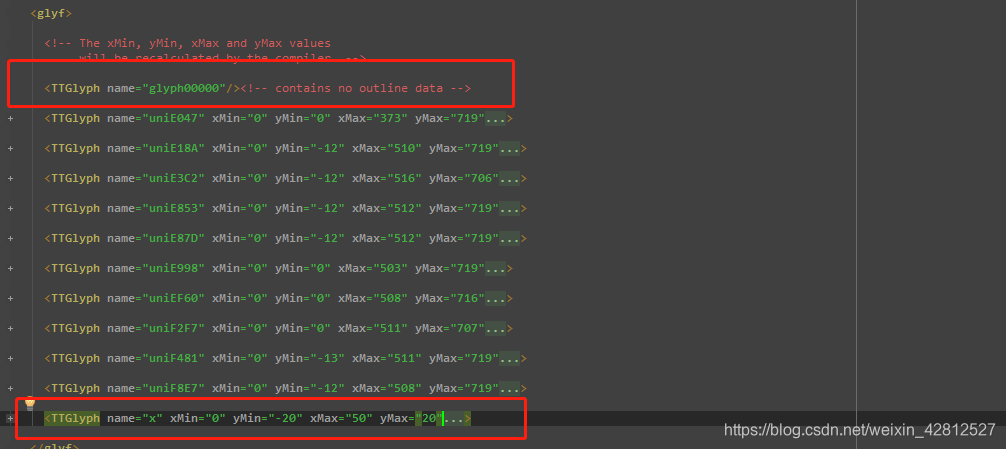
点开对象,里面的信息如下,是一些坐标点的信息,如下图:
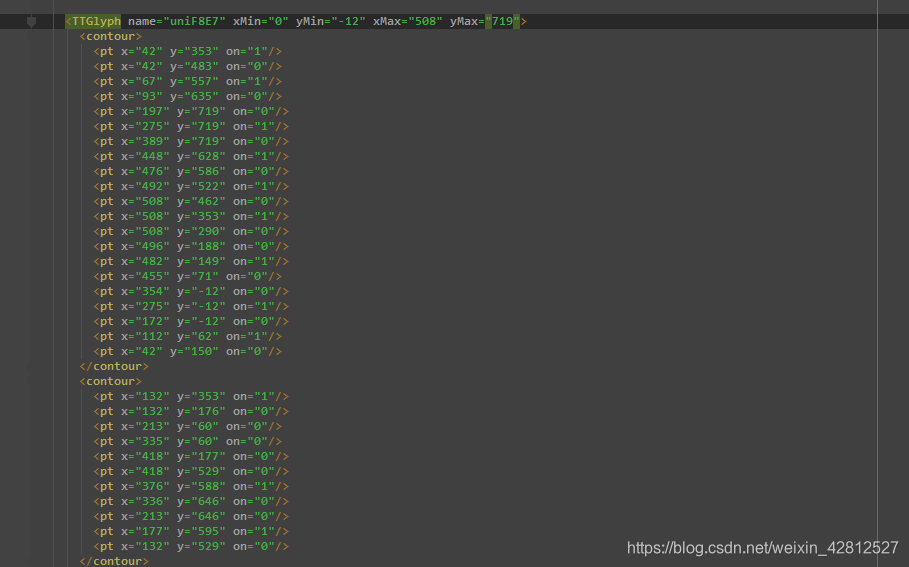
通过上边我们大致可以考虑:猫眼电影,虽然字符的编码是变化的,但是对象是不变的。那么我们可以通过第一次下载一个字体文件origin.ttf,并把对应编码的字体写出来,那么当第二次从网上重新下载一个字体文件online_base64.ttf 的时候,可以对比对象信息,如果对象是一样的,那么就把第一次编码对应的文字赋值给第二次的编码,这样即可,不知道说的明白不明白。你可以参考上边两位大神的,他们应该讲的更清楚。那么思路有了,代码如下,莫嫌弃low:
import re
import base64
import chardet
import requests
from scrapy import Selector
from fontTools.ttLib import TTFont
url = 'https://piaofang.maoyan.com/?ver=normal'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
}
response = requests.get(url=url, headers=headers).content # 得到字节
charset = chardet.detect(response).get('encoding') # 得到编码格式
response = response.decode(charset, "ignore") # 解码得到字符串
# 第一次获取的字体,以及对应编码位置,需要手动写一次。
origin_fonts = TTFont('origin.ttf')
origin_obj_list1 = origin_fonts.getGlyphNames()[1:-1] # 获取所有字符的对象,去除第一个和最后一个,之前的图已经解释清楚为什么去掉最后一个和第一个。
origin_uni_list1 = origin_fonts.getGlyphOrder()[2:] # 获取所有编码,去除前2个。
origin_dict = {'uniF855': '1', 'uniF755': '8', 'uniF617': '9', 'uniE4CA': '4', 'uniE912': '6', 'uniF514': '3',
'uniE3A5': '7', 'uniF594': '5', 'uniF16A': '0', 'uniF09C': '2'} # 写出第一次字体文件的编码和对应字体。
# 获取字体文件的base64编码
online_ttf_base64 = re.findall(r"base64,(.*)\) format", response)[0]
online_base64_info = base64.b64decode(online_ttf_base64)
with open('online_base64.ttf', 'wb')as f:
f.write(online_base64_info)
online_base64_fonts = TTFont('online_base64.ttf') # 网上动态下载的字体文件。
online_obj_list2 = online_base64_fonts.getGlyphNames()[1:-1] # 同上。
online_uni_list2 = online_base64_fonts.getGlyphOrder()[2:]
for uni2 in online_uni_list2:
obj2 = online_base64_fonts['glyf'][uni2] # 获取编码uni2在online_base64.ttf中对应的对象
for uni1 in origin_uni_list1:
obj1 = origin_fonts['glyf'][uni1] # 获取编码uni1在origin.ttf 中对应的对象。
if obj1 == obj2: # 如果对象一等于对象二
dd = "&#x" + uni2[3:].lower() + ';' # 把编码uni2替换成Unicode编码格式。
if dd in response: # 如果编码uni2的Unicode编码格式在response中,那么替换成origin_dict[uni1]的字体。
response = response.replace(dd, origin_dict[uni1])
response_info = Selector(text=response)
all_info = response_info.xpath('//ul[@class="canTouch"]') # 获取所有的信息
print('电影名字' + '\t' + '实时票房(万元)' + '\t' + '票房占比' + '\t' + '排片占比' + '\t' + '上座率')
for each_info in all_info:
movie_name = each_info.xpath('li[1]/b/text()').extract_first() # 电影名字
ticket_number = each_info.xpath('li[2]/b/i[@class="cs"]/text()').extract_first() # 实时票房(万元)
ticket_rate = each_info.xpath('li[3]/i[@class="cs"]/text()').extract_first() # 票房占比
film_rate = each_info.xpath('li[4]/i[@class="cs"]/text()').extract_first() # 排片占比
upper_seat_rate = each_info.xpath('li[5]/span/i[@class="cs"]/text()').extract_first() # 上座率
print(movie_name + '\t' + ticket_number + '\t' + ticket_rate + '\t' + film_rate + '\t' + upper_seat_rate)
结果如下:
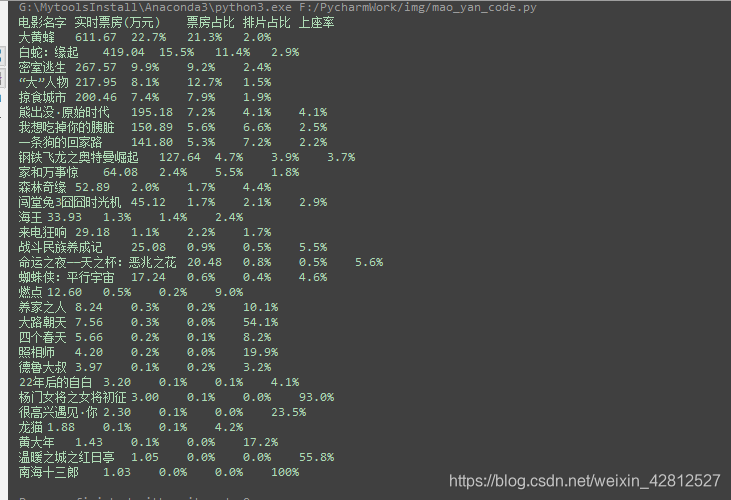
那么对比网站信息如下图:
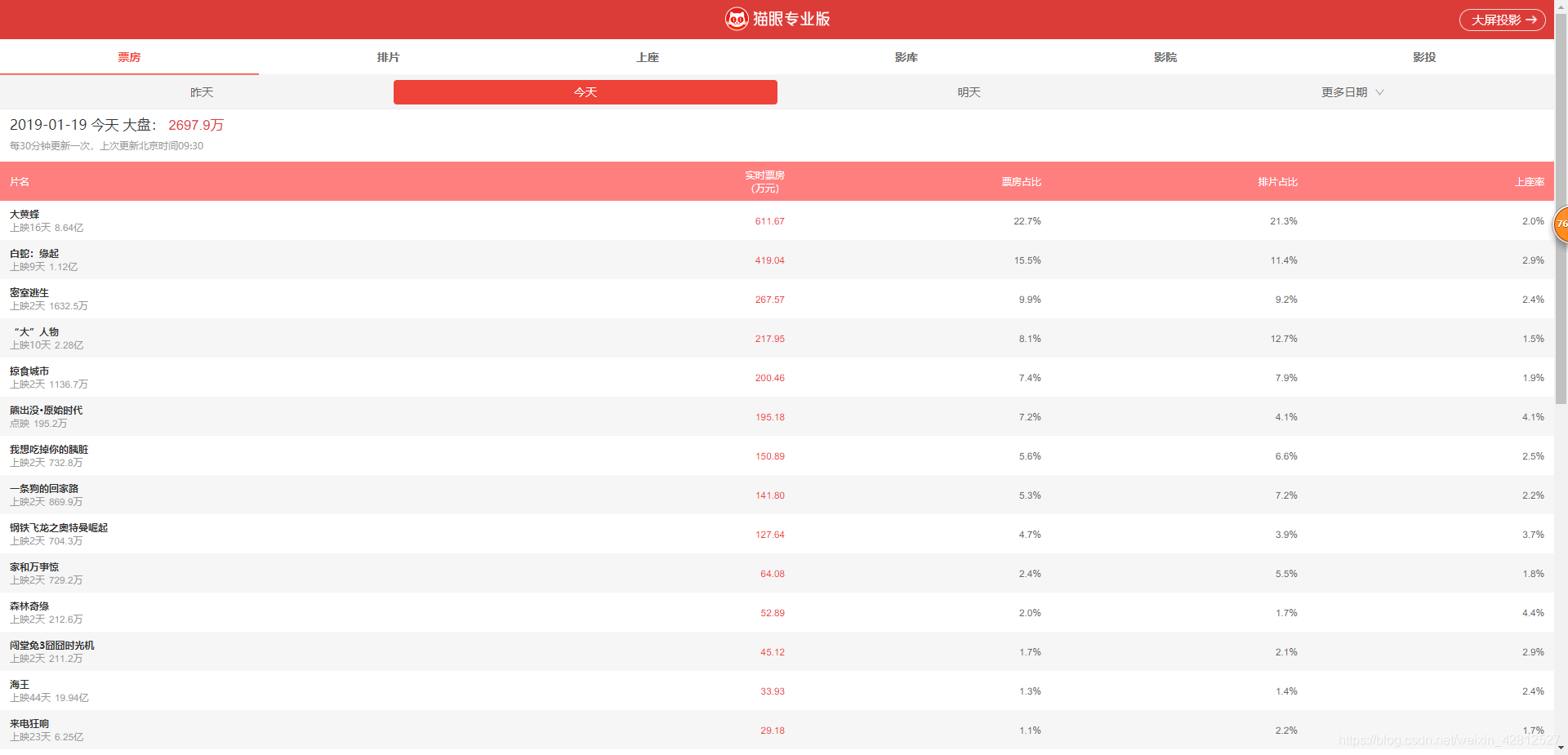
可以看到抓取正确了,猫眼代码和思路在上边,如果你路过看到了,有迷惑的地方,可以一起讨论共同进步,当然如果你有更好的网站或者难以破解的,咱们可以一起研究研究,共同进步。