一.关于字体反爬的思路
1.打开猫眼电影我们发现其很多关于数值在网页显示正常,通过element看到是方框
如图:
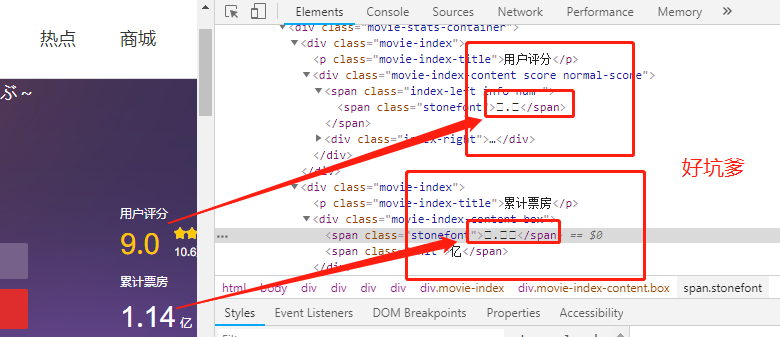
这些编码是自定义的,所以用utf-8编码方式是显示不出来的。浏览器显示的时候因为采用了自定义的字体文件,所以显示正常。
他们将这些数字的数据都做了字体进行映射,用了他们自己的字体,那我们可以看看开发者工具的 network 查看他所用的字体,
一般都是 wolf 或者 ttf 结尾的
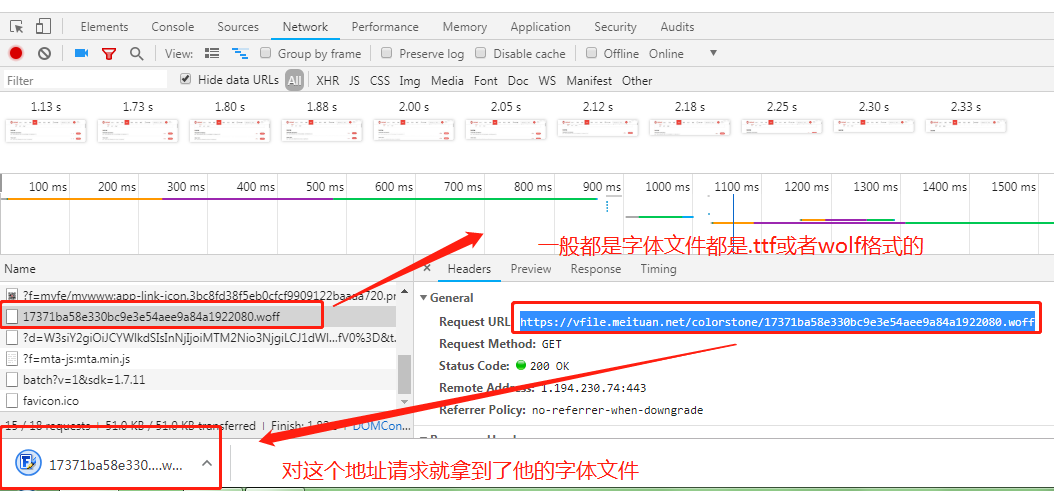
2.打开network看到所有的请求(找到字体的请求,直接那请求url就能拿到他的字体文件)
如图:
3.字体处理
接下来我们要查看和处理这个字体文件,这里要用到两个工具。一个是软件 FontCreator,可以直接打开ttf字体文件,查看每一个字符对应的编码。
还有一个是python第三方库fontTools,借助这个库可以用python代码来操作ttf文件。
1.FontCreator安装:
https://www.high-logic.com/font-editor/fontcreator(官网收费,可以免费使用30天,自己摸索)
打开字体文件如下

2.在开发者工具中打开sourse

是不是对应上了呢?
3.fontTools模块,高版本的python自带,没有的就自己
pip install fonttools
基本命令:
from fontTools.ttLib import TTFont
#读取文件
font =TTFont('17371ba58e330bc9e3e54aee9a84a1922080.woff')
#使用fotTools将字体文件转为XML,
font.saveXML('1.xml')
先把字体文件转化成xml格式,以便打开查看里面的数据结构。打开xml文件可以看到类似html标签的结构。
这里我们用到的标签是<GlyphOrder...>和<glyf...> 。

点开标签内部,<GlyphOrder...>内包含着所有编码信息,注意前两个是不是0-9的编码,需要去除

<glyf...> 标签内包含着每一个字符的对象<TTGlyph>,同样第一个和最后一个不是0-9的字符,需要祛除。

点开<TTGlyph>对象,里面的信息如下,是一些坐标点的信息,可以联想到这些点应该是描绘字体形状的

4.思路
这里补充一点就是你每次访问加载的字体文件中的字符的编码可能是变化的,就是说网站有多套的字体文件。
既然编码是不固定的,那就不能用编码的一一对应关系来处理字体反爬。这里要用到上面说的三方库fontTools,
利用fontTools可以获取每一个字符对象,这个对象你可以简单的理解为保存着这个字符的形状信息。而且编码可以
作为这个对象的id,具有一一对应的关系。像猫眼电影,虽然字符的编码是变化的,但是字符的形状是不变的,也就是说这个对象是不变的。
基本思路:先下载一个字体文件保存到本地(比如叫01.ttf),人工的找出每一个数字对应的编码。当我们重新访问网页时,
同样也可以把新的字体文件下载下来保存到本地ttf(比如叫02.ttf)。网页中的一个数字的编码比如为AAAA,如何确定
AAAA对应的数字。我们先通过编码AAAA找到这个字符在02.ttf中的对象,并且把它和01.ttf中的对象逐个对比,直到找到
相同的对象,然后获取这个对象在01.ttf中的编码,再通过编码确认是哪个数字。
5.实现步骤
先在本地保存字体文件01.ttf,并手动确认编码和数字的对应关系,保存到字典中。然后重新访问网页的时候,
把网页中新的字体文件也下载保存到本地02.ttf。对于02中的编码uni2,先获取uni2的对象obj2,与01中的每一个
对象注逐一对比,直到找到相同的对象obj1,再根据obj1的编码,在字典中找到对应的数字
#!/usr/bin/env python # -*- coding: utf-8 -*- #author tom from fontTools.ttLib import TTFont # #读取文件 # font =TTFont('17371ba58e330bc9e3e54aee9a84a1922080.woff') # #使用fotTools将字体文件转为XML, # font.saveXML('1.xml') font_dic1={ 'uniF5F7':0, 'uniF03C':3, 'uniEB08':7, 'uniE168':5, 'uniF60B':4, 'uniF33E':6, 'uniEBF3':1, 'uniE1DE':2, 'uniE9C5':8, 'uniE10E':9 } font1=TTFont('17371ba58e330bc9e3e54aee9a84a1922080.woff') #打开本地文件1 obj_list1=font1.getGlyphNames()[1:-1] #获取所有字符的对象,去除第一个和最后一个 uni_list1=font1.getGlyphOrder()[2:] #获取所有编码,去除前2个 print(obj_list1) print(uni_list1) font2=TTFont('4fd35f4422018bc06643d2869a82f5602084.woff') obj_list2=font2.getGlyphNames()[1:-1]#获取所有的字符对象 unit_list2=font2.getGlyphOrder()[2:]#获取所有的编码 f=open('new.woff','a',encoding='utf-8') font_dic2={}#用来构造字体2对应的字典 for unit2 in unit_list2: obj2=font2['glyf'][unit2] #拿到文件二unit对应的对象 for unit1 in uni_list1: obj1=font1['glyf'][unit1] #拿到对象二和字体一的对象一一对比 if obj1==obj2: font_dic2[unit2]=font_dic1[unit1] #构造自已二字典 print((font_dic2))
#效果:
