记录k-近邻算法 解决猫眼电影的字体反爬。
此博客仅为我业余记录文章所用,发布到此,仅供网友阅读参考,如有侵权,请通知我,我会删掉。
文章有一些点没有说的很细。因为我相信能看到这篇文章的你,不通过我的叙述也是可以懂的。
1. 项目背景
- 打开猫眼电影查看实时票房是.,无疑,这是网站自定义了部分字体。
- 看到右边的font-family名为stonefont,这该是网站自定义字体的名称了。然后点击右边的画框的地方。
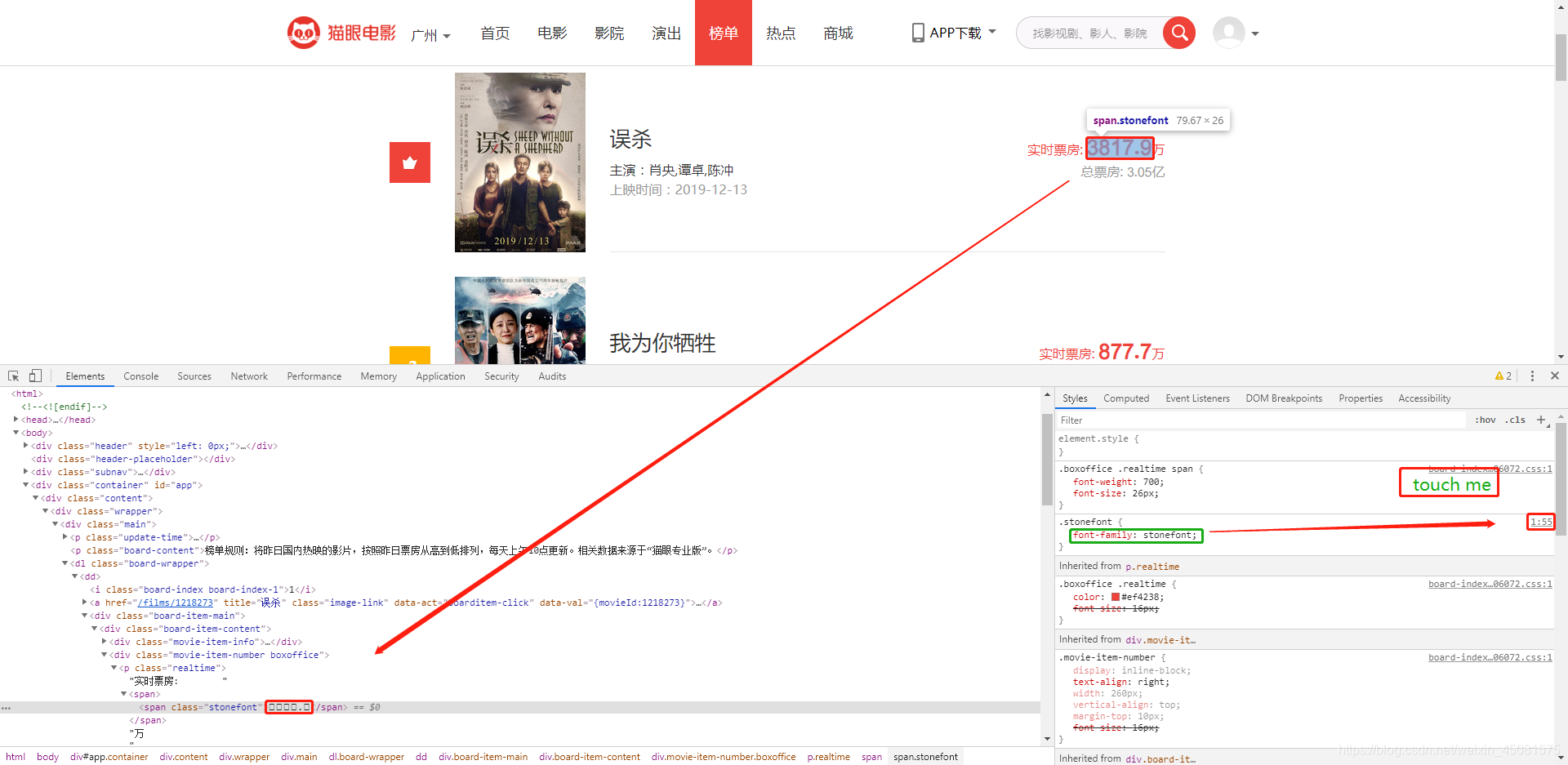
- 好家伙,点击后页面跳转到了这里。这里的font-family名字也是stonefont,自定义字体文件就是它了。
- 看到后缀为woff了没,这个就是字体文件。访问一下该 URL,就给我下载了一个字体文件。bingo!!
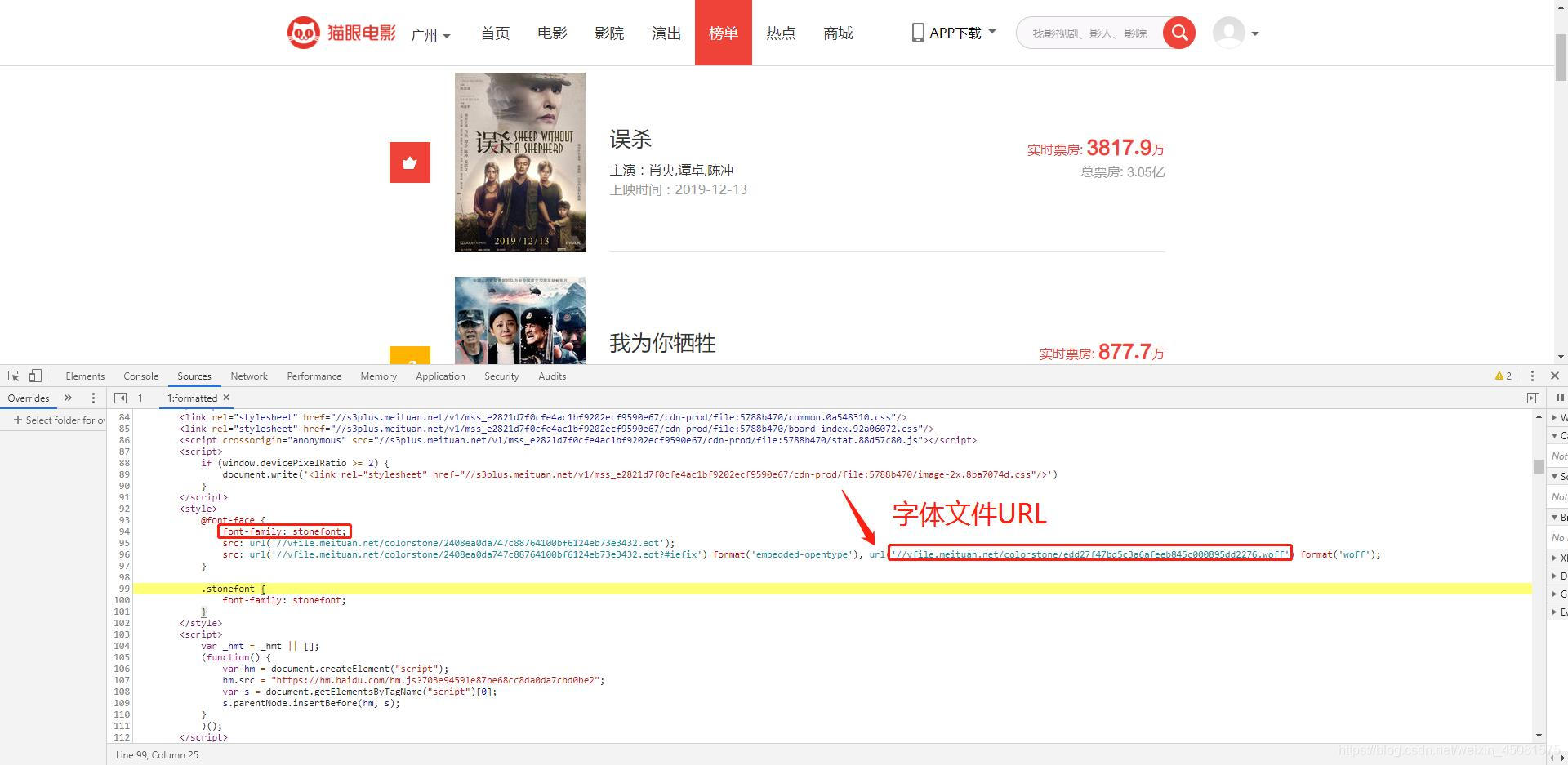
用字体编辑器打开下载的字体文件。
这里推荐两种字体编辑工具。
- FontCreator工具,安装包百度搜索一大堆。
- 百度在线FontEditor工具:http://fontstore.baidu.com/static/editor/index.html
文章使用的是FontCreator,(破解版哦!若经济条件允许,请支持并购买正版)
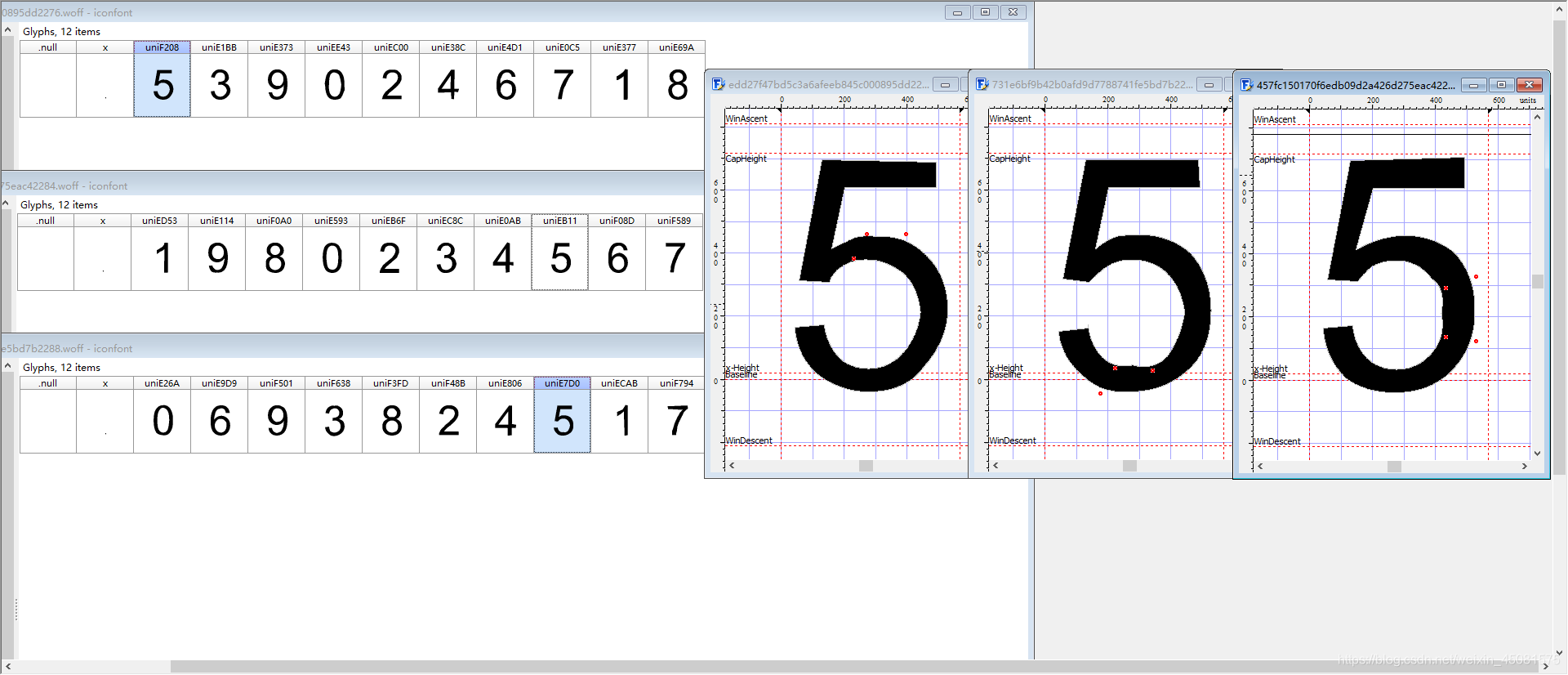
- 打开字体文件后看到,共有10位数字。
- 数字5对应的uni编码为uniF208,序号为2
- 数字都是由密密麻麻的坐标点连线组成的。
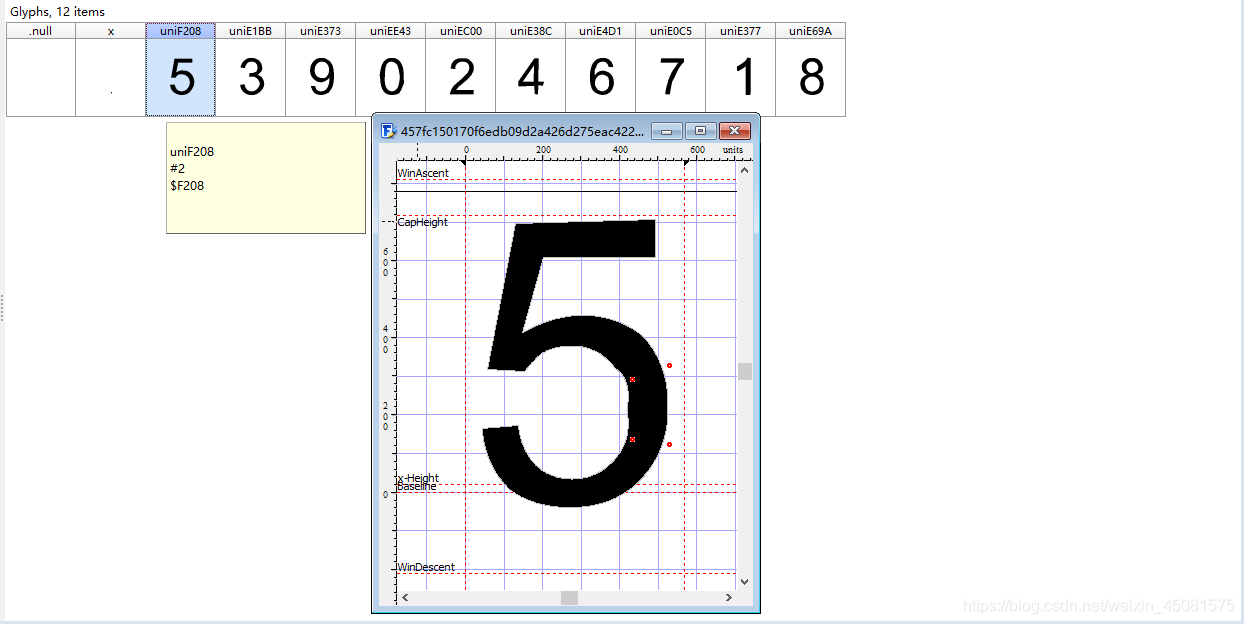
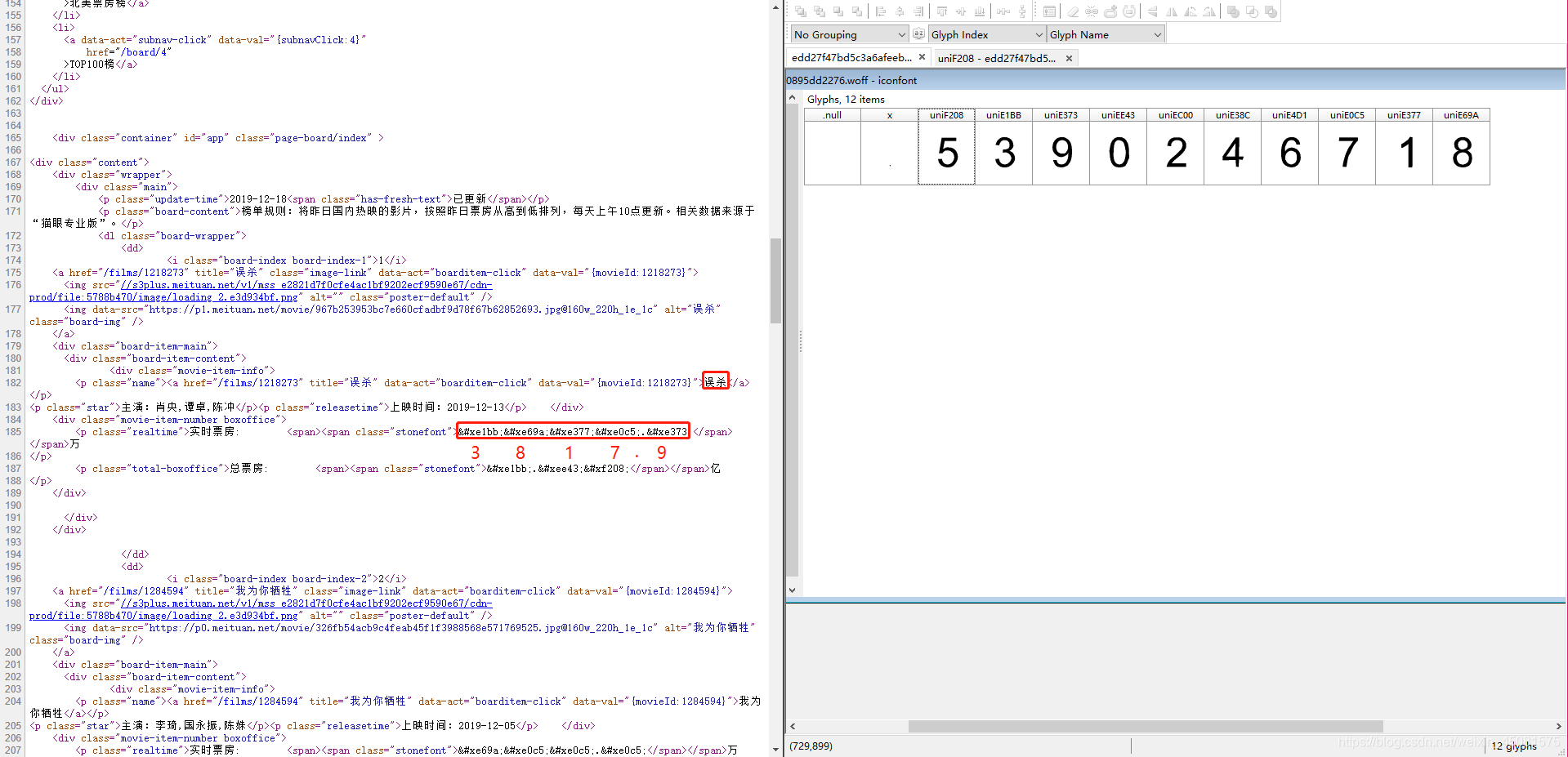
可以从表格中清楚的看出源码与字体的对应关系。
| 网页显示 | 源码显示 | 字体显示 |
|---|---|---|
| 3 |  | uniF1BB |
| 5 |  | uniF208 |
| … | … | … |
- 这里查看一下网页的源码,看到 《误杀》 这部电影的实时票房,看到它的票房的数字字体被带  的编码给替代了。
- 但是在仔细与右边的字体文件对比之下,发信他们的后三位是相同的。这就是规律!!!
- 既然如此!那根据他们的对应关系建立一个字典。
- 本文完。
等等??怎么我每次刷新页面时候,网站的字体文件都有变化???
这有什么,直接用字体文件的坐标做对应就行了。
- 但是!!仔细观看不同字体文件之间的表达同一个数字的坐标是有些差异的!
- 这个!下面用k-近邻算法实现对猫眼电影字体的破解。
2. 解决思路 + 重要代码
何为 k-近邻算法:
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。
该方法的思路是:在特征空间中,如果一个样本附近的k个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。
在这里换句话说就是,先保存多个字体坐标对应的数字样本。然后输入新字体文件的样本,从而判断新字体文件具体的数字。
那接下来的思路就是:
- 先保存多份数字与字体坐标对应的数据样本集
- 提取网页的字体坐标与样本集做比对,得出新坐标对应的数字
fontTools的基本操作
from fontTools.ttLib import TTFont
base_font = TTFont('xxx.woff') # 打开文件
base_font.saveXML('xxx.xml') # 将字体文件保存为xml文件
base_font.getBestCmap() # 映射关系unicode跟Name
base_font['glyf'][name].coordinates # 字形的轮廓信息(坐标数据)
获取新字体坐标数组
def parse_font():
"""
获取新字体文件的uni编码的坐标
:return:
"""
base_font = TTFont('maoyan.woff')
uni_list = base_font.getGlyphOrder()[2:]
print(uni_list)
num_dict = {}
for name in uni_list:
# 获取字体坐标 [(142, 151), (154, 89), (215, 35)......]
# 循环遍历 [142, 151, 154, 89, 215, 35.....]
coordinate = (list(base_font['glyf'][name].coordinates))
font_0 = [i for item in coordinate for i in item]
print(font_0)
knn-近邻算法实现:
这里只需要传入新字体文件的坐标数组即可返回坐标对应的数字。
# -*- coding: utf-8 -*-
"""knn算法实现传入新字体文件的坐标数组返回比对后的数字"""
import numpy as np
from font_dataset import dataset_ # 字体样本数据集
def handle_dataset():
"""
:return: 返回训练样本集,以及对应的标签
"""
# 值得注意的是,样本数据的长度和新字体坐标数组的长度必须一致!!
# 所以这里也要用zeros生成长度为200的数组,r然后再做替换
lables = list(data[0] for data in dataset_)
dataset = list(data[1] for data in dataset_)
returnmat = np.zeros((len(dataset), 200))
index = 0
for data in dataset:
returnmat[index, :len(data)] = data
index += 1
return returnmat, lables
def classify_knn(new_array, dataset, lables, k):
"""
:param new_array: 新实例
:param dataset: 训练数据集
:param lables: 训练集标签
:param k: 最近的邻居数目
:return: 返回算法处理后的结果
"""
# np.shape是取数据有多少组,然后生成tile生成与训练数据组相同数量的数据
# 然后取平方
# np.sum(axis=1) 取行内值相加,然后开发,求出两点之间的距离
datasetsize = dataset.shape[0]
diffmat = np.tile(new_array, (datasetsize, 1)) - dataset
sqrdiffmat = diffmat ** 2
distance = sqrdiffmat.sum(axis=1) ** 0.5
# np.argsort将数值从小到大排序输出索引
# dict的get返回指定键的值,如果值不在字典中返回默认值。
# 根据排序结果的索引值返回靠近的前k个标签
sortdistance = distance.argsort()
count = {}
for i in range(k):
volelable = lables[sortdistance[i]]
count[volelable] = count.get(volelable, 0) + 1
count_list = sorted(count.items(), key=lambda x: x[1], reverse=True)
return count_list[0][0]
def knn_num(inX):
"""
:param inX: 传入新字体文件的坐标数组
:return: 返回比对后的对象的数字
"""
# returnMats 返回一个长度为200的用0填充的数组
# 生成长度为200的数组,将returnMats前面替换为传入的字体坐标数组
returnMats = np.zeros([200])
returnMats[:len(inX)] = inX
inX = returnMats
dataset, lables = handle_dataset()
result = classify_knn(inX, dataset, lables, 5)
return (result)
3. 后面的话
好了,本次的分享就到这里。有任何问题欢迎在下方留言哦。
