猫眼电影字体反爬
我们再爬取猫眼电影的时候,会遇到如下情况:
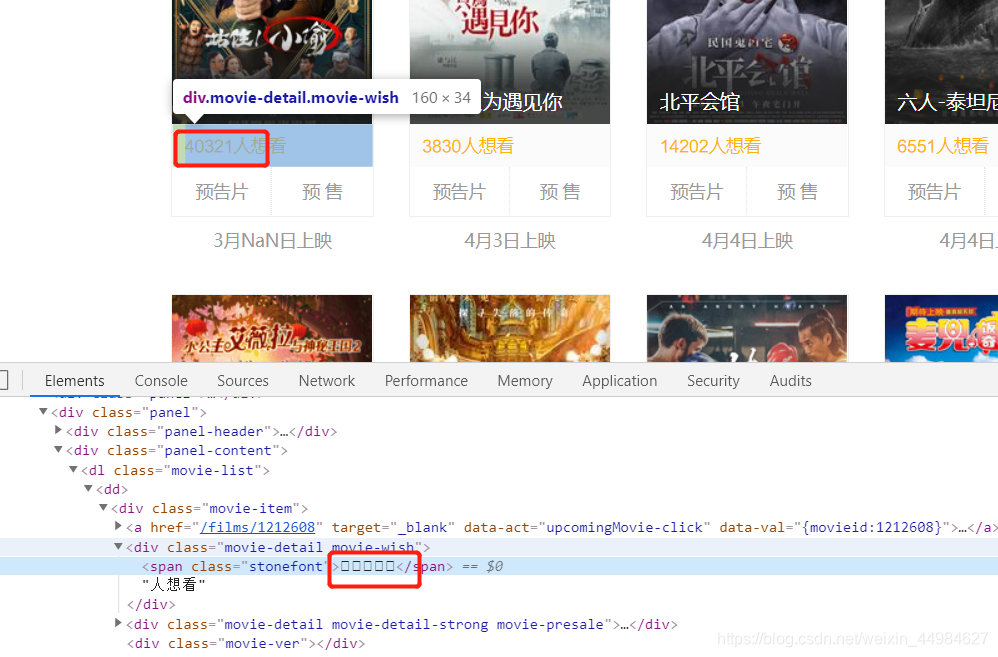
我们想要其中想看人数的数据,但是在网页源代码中并不是直接显示数字而是这一串东西。
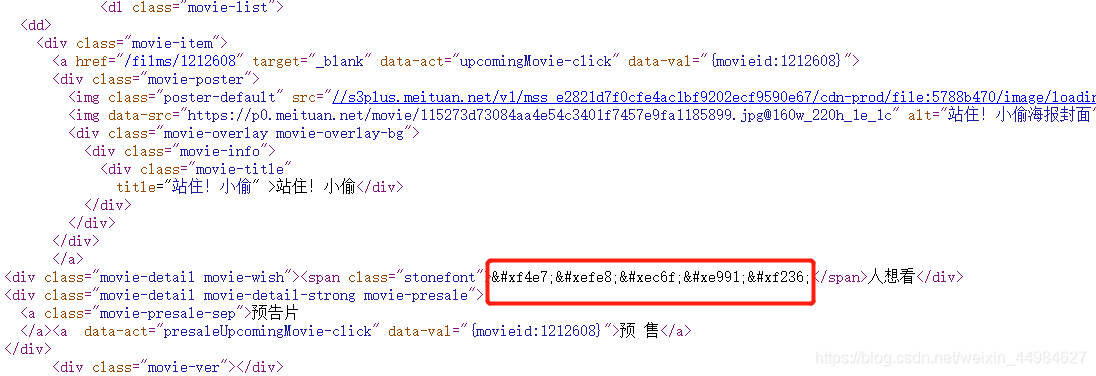
这一串,其实是猫眼本身的一种字体,目的是不想每个人都获取到数据。针对这个情况我们可以先找到他的字体文件,然后再根据字体文件当中的映射,会得到一个与其一一对应的文字,数字。
所以最关键的是,我们需要找到对应的字体文件。

这个就是我们要的字体文件。
现在我们已经找到字体文件,那就可以开始代码了。
# -*- coding: utf-8 -*-
# @Time : 2020/3/12 16:03
# @Author : Key-lei
# @File : 猫眼字体反爬.py
import pytesseract
import re
from PIL import Image, ImageDraw, ImageFont
import numpy
import requests
from fontTools.ttLib import TTFont
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='gb18030')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
'Cookie': '_lxsdk_cuid=16facc64c82c8-055dec5bcd6a8b-67e1b3f-144000-16facc64c83c8; mojo-uuid=ba4d3c82cda301e769a5f9c7be5ffc1b; uuid_n_v=v1; uuid=AE503A60640C11EA8A1F6D95DD58016C6194D2B9BDAF42BE931F0B7D7D333C9D; _csrf=f44cb36a00449de08883dbc550117e8248069b1af61f70e325e92bb8ddbc45b3; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1583981620; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; _lxsdk=AE503A60640C11EA8A1F6D95DD58016C6194D2B9BDAF42BE931F0B7D7D333C9D; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1583981673; __mta=50075417.1583981621233.1583981621233.1583981673734.2; _lxsdk_s=170cd067a1a-c61-a79-a14%7C%7C1',
}
# 获取
def get_response(url):
response = requests.get(url, headers=headers)
return response
# 获取字体文件
def get_font(html):
font_url = re.findall("url\('(//vfile.meituan.net/colorstone/.*?\.woff)'\)", html)
font_url_real = 'https:' + font_url[0]
get_font_html = requests.get(font_url_real)
font_name = font_url_real.split('/')[-1]
with open(font_name, mode='wb') as f:
f.write(get_font_html.content)
return font_name
# 将web下载的字体文件解析,返回其编码和数字的对应关系
def font_convert(font_name):
# 获取字体的映射规则
base_font = TTFont(font_name)
code_list = base_font.getGlyphOrder()[2:]
# 创建一张图片 用来把字体画上去
im = Image.new("RGB", (1800, 1800), (255, 255, 255))
image_draw = ImageDraw.Draw(im)
base_font = ImageFont.truetype(font_name, 40)
# 等分成一份
count = 1
# 等分成一份
array_list = numpy.array_split(code_list, count)
for i in range(len(array_list)):
print('替换之前的', array_list[i])
# 讲javascript的unicode码变成python总的unicode码
new_list = [i.replace("uni", "\\u") for i in array_list[i]]
print('替换之后的', new_list)
text = "".join(new_list)
text = text.encode('utf-8').decode('unicode_escape')
# print('text:', text)
# 把反向编码的 文字写在图片上 要使用的字体
image_draw.text((0, 100 * i), text, font=base_font, fill="#000000")
im.save("font_2_str.jpg")
im.show()
im = Image.open("font_2_str.jpg") # 可以将图片保存到本地,以便于手动打开图片查看
# 识别图片中的文字
result = pytesseract.image_to_string(im)
print(result)
# # 去除空白及换行
result_str = result.replace(" ", "").replace("\n", "")
# 将内容替换成网页的格式,准备去网页中进行替换
print(code_list)
html_code_list = [i.replace("uni", "&#x") + ";" for i in code_list]
print(html_code_list)
# print(len(html_code_list))
# print(len(result_str))
return dict(zip(html_code_list, list(result_str)))
if __name__ == '__main__':
response = get_response('https://maoyan.com/')
font_url = get_font(response.text)
with open('替换之前的.html', mode='w', encoding='utf-8') as f:
f.write(response.text)
font_name = get_font(response.text)
font_rule_map = font_convert(font_name)
print(font_rule_map)
new_html = response.text
for key, value in font_rule_map.items():
new_html = new_html.replace(str(key).lower(), value)
print(key, value)
with open('替换之后的.html', mode='w', encoding='utf-8') as f:
f.write(new_html)
github项目地址:https://github.com/Key-lei/maoyanSpider(欢迎star有问题可以在上面留言告诉我~)
