本篇博客所有示例使用Jupyter NoteBook演示。
Python数据分析系列笔记基于:利用Python进行数据分析(第2版)
目录
1.通用函数ufunc
通用函数(ufunc)是一种对ndarray中的数据执行元素级运算的函数。你可以将其看作简单函数(接受一个或多个标量值,并产生一个或多个标量值)的矢量化包装器。
许多通用函数ufunc都是简单的元素级变体,如sqrt和exp:
arr = np.arange(10)
print(arr)
#矢量化运算 相当于对数组中的每个元素都做运算
print(np.sqrt(arr))
print(np.exp(arr))
以上都是一元ufunc,另外还有一些2元ufunc,如add或maximum等可以接受两个数组,并返回一个结果数组:
x = np.random.randn(8)
y = np.random.randn(8)
print(x)
print(y)
print(np.maximum(x,y))#计算x和y两个数组中元素级别最大的元素

虽然不常见,但有些ufunc可以返回多个数组。modf就是一个例子,它是Python内置函数divmod的矢量化版本,它会返回浮点数数组的小数和整数部分:
arr = np.random.randn(7)*5
print(arr)
remainer,whole_part = np.modf(arr)
print(remainer) #数组中每个元素的小数部分
print(whole_part) #数组中每个元素的整数部分
ufuncs可以接受一个out可选参数,这样就能在数组原地进行操作:
print(arr)
print(np.sqrt(arr)) #返回数组中每个元素的平方根
print(arr) #arr本身并没有变
print("---------------")
print(np.sqrt(arr,out=arr)) #在arr数组原地进行 把计算结果赋给arr原数组
print(arr)
下表是一元ufunc:

下表是2元ufunc:

上表中的某些2元ufunc,既可以使用上述函数,也可以使用numpy重载的运算符。如np.add(a,b),也可以使用a+b,np.greater(a,b),也可以使用a>b等。
2.通用函数ufunc高级应用
虽然许多NumPy用户只会用到通用函数所提供的快速元素级运算(矢量化运算),但通用函数实际上还有一些高级用法能让我们丢开循环而编写出更为简洁的代码。
- ufunc实例方法
NumPy的各个2元ufunc都有一些用于执行特定矢量化运算的特殊方法。下表汇总了这些方法:

reduce接受一个数组参数,并通过一系列的2元运算对其值进行聚合(可以指定轴向).如我们可以使用np.add.reduce对数组中的各个元素求和,相当于ndarray.sum()或np.sum(ndarrray)
arr = np.arange(10)
print(np.add.reduce(arr))
print(np.sum(arr)) #arr.sum()
起始值取决于ufunc(对于add的情况,就是0).如果设置了轴号,约简运算就会沿该轴进行,我们就能用一种比较简洁的方式得到某些问题的答案。
接下来我们用np.logical_and检查数组各行中的值是否是有序的:
np.random.seed(12346)
arr = np.random.randn(5,5)
print(arr)
arr[::2].sort(1) # arr[::2]隔一行取一行 步长为2 对部分行进行排序
print(arr[:,:-1] < arr[:,1:]) #arr[:,:-1]从第一列到倒数第2列 不包括-1最后一列; arr[:,1:] 从第2列到最后一列
print(np.logical_and.reduce(arr[:,:-1]<arr[:,1:],axis=1))
注意logical_and.reduce跟al函数是等价的。
accumulate跟reduce的关系就像cumsum跟sum的关系一样,他产生一个和原数组大小相同的中间"累计"值数组:
arr = np.arange(15).reshape((3,5))
print(np.add.accumulate(arr,axis=1)) #np.cumsum(arr,axis=1)
print(np.cumsum(arr,axis=1))
print(np.cumsum(arr)) #所有值进行累计求和 返回一个一维数组
print(np.add.accumulate(arr)) #默认axis=0 而不是对所有值求累计值
可以用outer计算两个数组的叉积/外积:
arr = np.arange(3).repeat([1,2,2])
print(arr)
print(np.multiply.outer(arr,np.arange(5)))
outer输出结果的维度是两个输入数组的维度之和/拼接:
x,y = np.random.randn(3,4),np.random.randn(5)
res = np.subtract.outer(x,y)
print(res.shape)
最后一个方法reduceat用于计算"局部约简",其实就是一个对数据各个切片进行聚合的groupby运算。他接受一组用于指示如何对值进行拆分和聚合的"面元边界":
arr = np.arange(10)
print(np.add.reduceat(arr,[0,5,8])) #在arr[0:5] arr[5:8] arr[8:]上进行约简运算 和其他方法一样也可以接受一个axis参数![]()
arr = np.multiply.outer(np.arange(4),np.arange(5))
print(arr)
print(np.add.reduceat(arr,[0,2,4],axis=1))
- 编写新的ufunc
有多种方法可以让你编写自己的NumPy ufuncs。最常见的是使用NumPy CAPI,但它超过了Python数据分析系列博客的范围。本部分纯粹讲Python ufunc。
np.frompyfunc接受一个Python函数以及两个分别表示输入输出参数数量的参数,例如下面是一个实现元素级加法的简单函数:
def add_element(x,y):
return x+y
add_them = np.frompyfunc(add_element,2,1) #参数是2个数组 返回一个数组
print(add_them(np.arange(8),np.arange(8)))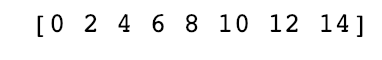
用frompyfunc创建的函数总是返回Python对象数组,这一点很不方便。还有另一个办法,即np.vectorize。虽然没有frompyfunc那么强大,但可以指定输出类型:
add_them = np.vectorize(add_element,otypes=[np.float64])
print(add_them(np.arange(8),np.arange(8)))
虽然这两个函数提供了一种创建ufunc通用函数的手段,但他们非常慢,因为他们在计算每个元素时都要执行一次Python函数调用,这会比NumPy自带的基于C的ufunc慢很多:
arr = np.random.randn(10000)
%timeit add_them(arr,arr)
%timeit np.add(arr,arr)
下一部分我们会介绍Numba,创建快速python ufuncs。
3.用Numba编写快速NumPy函数
Numba是一个开源项目,他可以利用CPUs、GPUs或其他硬件为类似NumPy的数据创建快速函数。它使用LLVM,将Python代码转换为机器代码。
首先考虑一个纯粹的Python函数,它使用for循环计算(x-y).mean():
def mean_distance(x,y):
nx = len(x)
res = 0.0
count = 0.0
for i in range(nx):
res += x[i]-y[i]
count +=1
return res/count
x = np.random.randn(10000000)
y = np.random.randn(10000000)
%timeit mean_distance(x,y)
%timeit (x-y).mean() #np.mean(x-y) 
NumPy版本比他快100倍。我们可以转换这个函数为编译的Numba函数,使用numba.jit函数:
import numba as nb
#numba_mean_distance = nb.jit(mean_distance)
#或写成装饰器
@nb.jit
def mean_distance(x,y):
nx = len(x)
res = 0.0
count = 0.0
for i in range(nx):
res += x[i]-y[i]
count +=1
return res/count
%timeit (x-y).mean() #np.mean(x-y)
%timeit mean_distance(x,y)
#%timeit numba_mean_distance(x,y)
他比矢量化的NumPy还要快,Numba不能编译Python代码,但他支持纯Python写的一个部分,可以编写数值算法。
Numba是一个深厚的库,支持多种硬件、编译模式和用户插件,他还可以编译NumPy Python API的一部分而不用for循环。Numba也可以识别可以编译为机器编码的结构体,但是若调用CPython API,他就不知道如何编译。Numba的jit函数有一个选项,nopython=True,他限制了可以被转换为Python代码的代码,这些代码可以编译为LLVM,但没有任何Python C API调用。jit(nopython=True)有一个简短的别名numba.njit。
之前的例子也可以这样写:
from numba import float64,njit
@njit(float64(float64[:],float64[:]))
def mean_distance(x,y):
return (x-y).mean()
- 用Numba创建自定义numpy.ufunc对象
numba.vectorize创建了一个编译的NumPy ufunc,他与内置的ufunc很像,考虑一个numpy.add的例子:
from numba import vectorize
@vectorize
def nb_add(x,y):
return x+y
arr = np.arange(10)
print(nb_add(arr,arr))
print(nb_add.accumulate(arr,0))