(一)目的
掌握编写高性能的扫描kernel。两个阶段的平衡树遍历;更好的中间结果重用;减少控制分歧与更复杂的线程索引与数据索引映射。
(二)内容
分别利用CPU和GPU生成的一个256 * 1024的和表,设置矩阵的初始值为2,在此基础上进行处理,生成和表。包括以下内容:
版本一:CPU实现一维和表
版本二:CPU实现二维和表
版本三:GPU实现一维和表
版本四:GPU实现二维和表
实验步骤一 软件设计分析:

- 数据类型:
根据实验要求,本实验的数据类型为一个256*1024的整型矩阵,其中元素的值为256*1024个值为2的float类型数据。
二.存储方式:
矩阵在内存中的存储按照行列优先可以分为两种方式,一种是行优先的存储方式,一种是按照列优先的方式。
这两种存储方式在访问对应的位置的数据的时候有很大的差别。在cuda内部,矩阵默认是按照列优先的方式存储,如果要使用cuda device函数,就必须考虑存储方式的问题,有的时候可能需要我们队存储方式进行装换。但是无论是用那种存储方式,最终在内存中都是顺序存储的。
本次实验,我们采用二维矩阵一维存储的方式进行。
三.GPU程序的block和threads的相关设置:
本实验提供的英伟达实验平台每一个Grid可以按照一维或者二维的方式组织,每一个Block可以按照一维,二维或者三维的方式进行组织。每一个block最多只能有1536个线程。内核函数使用的线程总量也受到设备本身的限制。
对于本次实验,针对上文中提到的几个任务,block和threads的组织方式都可以描述为:
int threadSize = 1024;
long blockSize = (256*1024 + threadSize - 1) / threadSize;
即每一个grid包含(256*1024 + threadSize - 1) / threadSize个block,而每一个block包含1024个线程。
实验步骤二 实验设备:
本地设备:PC机+Windows10操作系统
Putty远程连接工具
PsFTP远程文件传输工具
远程设备:NVIDIA-SMI 352.79
Driver Version:352.79
实验步骤三 CPU计算代码:
- CPU实现一维和表程序
- CPU实现二维和表程序
#include <stdio.h>
#include <stdlib.h>
#define M 256
#define N 1024
int main()
{
float (*h_src)[N] = new float[M][N];
//数据初始化
for (int i = 0; i < M; i++)
for(int j = 0;j < N;j++)
h_src[i][j] = 2.0;
//************start
cudaEvent_t start1, stop1;
cudaEventCreate(&start1);
cudaEventCreate(&stop1);
cudaEventRecord(start1, 0);
//************start
//自乘求和
for(int i = 0;i < M;i++)
{
float temp = 0;
for(int j = 0;j < N;j++)
{
temp += h_src[i][j] * h_src[i][j];
h_src[i][j] = temp;
}
}
//*************end
cudaEventRecord(stop1, 0);
cudaEventSynchronize(stop1);
//*************end
for (int i = 0; i < M; i++)
{
for(int j = 0;j < N;j++)
printf("%f ",h_src[i][j]);
printf("\n");
}
float time1;
cudaEventElapsedTime(&time1, start1, stop1);
printf("The time of cpu calculating is :%f\n", time1);
return 0;
}
实验步骤四 GPU计算代码:
- GPU实现一维和表程序
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <iostream>
#define N 1024
__global__ void calc_sumTable1D(float * g_odata, float * g_idata,int n);
int main()
{
cudaError_t err = cudaSuccess;
float* h_src = NULL, *h_out = NULL; //主机端输入、输出指针
float* d_src = NULL, *d_out = NULL; //设备端输入、输出指针
h_src = (float*)malloc(N * sizeof(float));
h_out = (float*)malloc(N * sizeof(float));
err = cudaMalloc((void **)&d_src, N * sizeof(float));
err = cudaMalloc((void **)&d_out, N * sizeof(float));
//数据初始化
for (int i = 0; i < N; i++)
{
h_src[i] = 2;
}
err = cudaMemcpy(d_src, h_src, N * sizeof(float), cudaMemcpyHostToDevice);
//cpu创建和表
printf("\ncpu创建和表\n");
float sum = 0.0;
for (int i = 0; i < N; i++)
{
sum += h_src[i]* h_src[i];
h_out[i] = sum;
}
printf("\ngpu创建和表\n");
//GPU创建和表
int threadSize = 1024;
long blockSize = (N + threadSize - 1) / threadSize;
size_t shareTemp_bytes = 2 * N * sizeof(float);
calc_sumTable1D <<<blockSize, threadSize, shareTemp_bytes >>>(d_out, d_src, N);
cudaMemcpy(h_out, d_out, N * sizeof(float), cudaMemcpyDeviceToHost);
for (int i = 0; i < 1024; i++)
printf("%f", h_out[i]);
free(h_src); free(h_out);
cudaFree(d_src); cudaFree(d_out);
system("pause");
return 0;
}
__global__ void calc_sumTable1D(float * g_odata, float * g_idata, int n)
{
extern __shared__ float temp[];
int tid = threadIdx.x;
int bid = blockIdx.x;
int offset = 1;
float in1 = 0;
if (tid < n)
{
in1 = g_idata[tid];
temp[tid] = in1 * in1;
temp[N + tid] = temp[tid];
__syncthreads();
for (int d = n >> 1; d > 0; d >>= 1)
{
__syncthreads();
if (tid < d)
{
int ai = offset * (2 * tid + 1) - 1;
int bi = offset * (2 * tid + 2) - 1;
temp[bi] += temp[ai];
}
offset *= 2;
}
if (tid == 0) temp[n - 1] = 0;
for (int d = 1; d < n; d *= 2)
{
offset >>= 1;
__syncthreads();
if (tid < d)
{
int ai = offset * (2 * tid + 1) - 1;
int bi = offset * (2 * tid + 2) - 1;
if (ai >= 0 && bi >= 0)
{
float t = temp[ai];
temp[ai] = temp[bi];
temp[bi] += t;
}
}
}
__syncthreads();
g_odata[tid] = temp[tid];
g_odata[tid] += temp[N + tid];
__syncthreads();
}
}
- GPU实现二维和表程序
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <iostream>
#define M 256
#define N 1024
__global__ void calc_sumTable2D(float * g_odata, float * g_idata,int n);
int main()
{
//cudaError_t err = cudaSuccess;
float* h_src = NULL, *h_out = NULL; //主机端输入、输出指针
float* d_src = NULL, *d_out = NULL; //设备端输入、输出指针
h_src = (float*)malloc(M*N * sizeof(float));
h_out = (float*)malloc(M*N * sizeof(float));
err = cudaMalloc((void **)&d_src, M*N * sizeof(float));
err = cudaMalloc((void **)&d_out, M*N * sizeof(float));
//数据初始化
for (int i = 0; i < M*N; i++)
{
h_src[i] = 2;
}
err = cudaMemcpy(d_src, h_src, M*N * sizeof(float), cudaMemcpyHostToDevice);
//cpu创建和表
printf("\ncpu create sum_table2D....\n");
float sum = 0.0;
for (int i = 0; i < M*N; i++)
{
sum += h_src[i]* h_src[i];
h_out[i] = sum;
}
printf("cpu sum_table2D has been created \n\ngpu create sum_table2D....\n");
//GPU创建和表
int threadSize = N;
long blockSize = (M*N + threadSize - 1) / threadSize;
size_t shareTemp_bytes = 2 * N * sizeof(float);
//************start
cudaEvent_t start1, stop1;
cudaEventCreate(&start1);
cudaEventCreate(&stop1);
cudaEventRecord(start1, 0);
//************start
calc_sumTable2D <<<blockSize, threadSize, shareTemp_bytes >>>(d_out, d_src, N);
cudaMemcpy(h_out, d_out, M*N * sizeof(float), cudaMemcpyDeviceToHost);
printf("gpu sum_table2D has been created \n");
/*for (int i = 0; i < M*N; i++)
{
printf("%f\t", h_out[i]);
if ((i+1) % N == 0)
printf("\n");
}*/
//*************end
cudaEventRecord(stop1, 0);
cudaEventSynchronize(stop1);
//*************end
printf("\n\n");
for (int i = 0; i < M; i++)
{
for (int j = 0; j < N; j++)
{
if (i > 0)
{
h_out[i * N + j] += h_out[(i - 1) * N + j];
}
}
}
printf("\n\n");
for (int i = 0; i < M*N; i++)
{
printf("%f\t", h_out[i]);
if ((i + 1) % N == 0)
printf("\n");
}
float time1;
cudaEventElapsedTime(&time1, start1, stop1);
printf("\nThe time of cpu calculating is :%f\n", time1);
free(h_src); free(h_out);
cudaFree(d_src); cudaFree(d_out);
return 0;
}
__global__ void calc_sumTable2D(float * g_odata, float * g_idata, int n)
{
extern __shared__ float temp[];
int tid = threadIdx.x;
int t_id = blockDim.x * blockIdx.x + threadIdx.x;
//int bid = blockIdx.x;
int offset = 1;
float in1 = 0;
if (tid < n)
{
in1 = g_idata[t_id];
temp[tid] = in1 * in1;
temp[N + tid] = temp[tid];
__syncthreads();
for (int d = n >> 1; d > 0; d >>= 1)
{
__syncthreads();
if (tid < d)
{
int ai = offset * (2 * tid + 1) - 1;
int bi = offset * (2 * tid + 2) - 1;
temp[bi] += temp[ai];
}
offset *= 2;
}
if (tid == 0) temp[n - 1] = 0;
for (int d = 1; d < n; d *= 2)
{
offset >>= 1;
__syncthreads();
if (tid < d)
{
int ai = offset * (2 * tid + 1) - 1;
int bi = offset * (2 * tid + 2) - 1;
if (ai >= 0 && bi >= 0)
{
float t = temp[ai];
temp[ai] = temp[bi];
temp[bi] += t;
}
}
}
__syncthreads();
g_odata[t_id] = temp[tid];
g_odata[t_id] += temp[N + tid];
__syncthreads();
}
}
实验步骤五 观察输出结果:
- 版本1:CPU实现一维和表输出结果

2,版本2:CPU实现二维和表输出结果

3,版本3:GPU实现一维和表输出结果

4,版本4:GPU实现二维和表输出结果
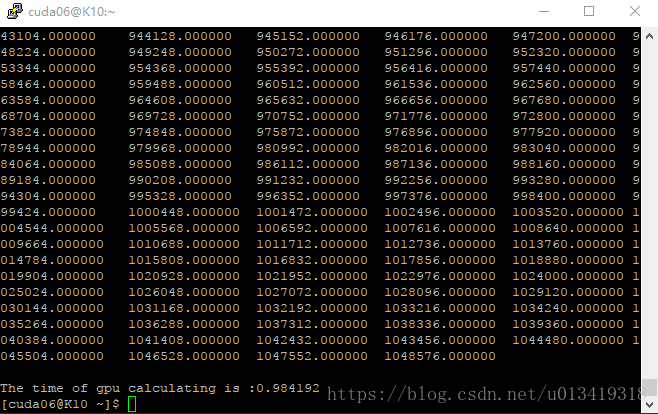
实验结论:
cpu程序计算所需时间:
版本1,CPU实现一维和表程序计算所需时间:0.050688 ms
版本2,CPU实现二维和表程序计算所需时间:3.279808 ms
gpu程序计算所需时间:
版本3,GPU实现一维和表程序计算所需时间:0.078496 ms
版本4,GPU实现二维和表程序计算所需时间:0.984192 ms
总结:
由实验结论可以看出,当数据量较大时,同样规模数据量的计算,与CPU端的运算效率相比较,GPU端的运算还是有所提高。我这里采用将数据平方及横向求和的步骤放在GPU端处理,而将纵向求和的步骤放在CPU端处理。这也是本程序的一个改进点,课程后续若有闲暇,可以进一步改进本程序。