Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring- CVPR2017
主要贡献
1、提出 多尺度学习CNN框架,实现由粗到细的方法提高了网络的收敛速度
之后多尺度学习框架大多基于这个模型(Scale-recurrent Network for Deep Image Deblurring -18CVPR)
2、 提出新的数据集
3、使用端到端神经网络解决模糊核估计问题————(传统CNN缺点 :1、简单的模糊核估计不能解决复杂的模糊核问题(例如被遮挡的区域)。2、核评估过程容易受到噪声影响,etc.)
数据集生成
作者通过捕获连续的锐利帧并进行整合以模拟模糊过程。(这里不做过多介绍)
方法模型
1、精细图像由粗糙的映射辅助----在保留精细信息的同时也利用了粗糙和中级水平的信息。
2、使用残差网络(加深网络结构)的同时去除整流线性单元(加快训练的速度和提升收敛速率)

图(b)为作者所用残差网络模型,图(a)为原始的残差网络模型。
使用K = 3 个等级 (等级越小模型越精细,1为最好模型),模型的输入和输出的三个分辨率分别为 {64x64,128x128,256x256} ,比例为0.5,在每个卷积层滤波器大小为5x5。每个尺度40个卷积层,一共120个卷积层。
模型如下:

我对这个模型的理解是:
1、首先使用256x256的模糊\清晰图相对进行下采样,分别的到64x64,128x128的模糊\清晰图相对。
2、然后从输入64x64的模糊图像B3开始训练,得到64x64去模糊图像L3(与真实清晰图像S3对比训练参数)
3、对L3进行上卷积(由于清晰和模糊的图像共享低频信息,因此通过向上卷积学习合适的特征有助于消除冗余。 在实验中,使用upconvolution表现出比上采样更好的性能,因此没有使用上采样)得到128x128去模糊图像,然后将上卷积得到的特征与更精细的模糊图像连接作为输入。
4、B2-B1同上。最后输出的L1被存储。
优化损失函数
1、多尺度内容损失
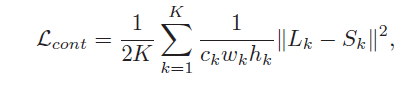
Lk 和 Sk 代表尺度为 k 的ground truth ,每个尺度的损失都被归一化为通道数量ck,宽度wk,以及高度hk。
2,对抗损失

G和D在这里分别代表生成器和鉴别器,当训练的时候G最大化损失,D最小化损失。
鉴别器将最精细尺度的输出或地面真实清晰图像作为输入,并将其分类为去模糊图像或清晰图像。
所以总的损失为:
在这里 λ=1×〖10〗^(-4) 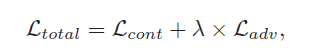

上表为在使用GOPRO数据集情况下测出来的PSNR 和 SSIM的对比
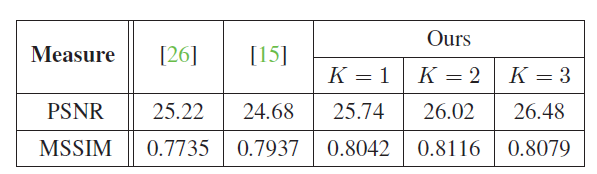
在使用Kohler Dataset 数据集下对比结果,可以看到大佬的还是很厉害。